Gemini 3 Complete Guide: Pro vs Flash vs Nano Banana - Pricing, Benchmarks & When to Use Each (2026)
Comprehensive comparison of Google Gemini 3 Pro, Flash, and Nano Banana image generation models. Includes pricing analysis, benchmark performance, API integration guide, and recommendations for choosing the right model.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

Google's Gemini 3 family represents a significant leap forward in AI capabilities, introducing three distinct models designed for different use cases: Gemini 3 Pro for maximum intelligence, Gemini 3 Flash for balanced performance, and Nano Banana for cutting-edge image generation. With Gemini 3 Pro achieving an unprecedented 91.9% on GPQA Diamond and becoming the first model to break the 1500 barrier on LMArena Elo, understanding which model to choose has become crucial for developers and businesses alike.
This comprehensive guide breaks down everything you need to know about the Gemini 3 family—from detailed specifications and pricing to real-world benchmark comparisons with Claude 4.5 and GPT-5. Whether you're building an agentic workflow, optimizing costs, or exploring native image generation, you'll find the information needed to make an informed decision.

Gemini 3 Pro: The Flagship Intelligence Model
Gemini 3 Pro is Google's most intelligent model, designed for complex reasoning tasks that require deep understanding across multiple domains. With a 1 million token context window and support for advanced thinking capabilities, it represents the state-of-the-art in multimodal AI.
The model excels in scenarios requiring sophisticated reasoning, including scientific research, complex code analysis, and multi-step agentic workflows. According to Google's official documentation, Gemini 3 Pro is "the world's leading multimodal understanding model" and "our most powerful agent and vibe coding model to date."
Key Specifications
| Property | Value |
|---|---|
| Model ID | gemini-3-pro-preview |
| Context Window | 1,048,576 tokens (1M) |
| Max Output | 65,536 tokens |
| Knowledge Cutoff | January 2025 |
| Input Types | Text, Images, Video, Audio, PDF |
| Output Types | Text |
| Status | Preview |
Supported Features
Gemini 3 Pro supports an extensive feature set that makes it suitable for production applications:
- Batch API: Process large volumes of requests efficiently
- Context Caching: Reduce costs by caching repeated context
- Code Execution: Execute code within the model's sandbox
- File Search: Search through uploaded documents
- Function Calling: Integrate with external tools and APIs
- Search Grounding: Access real-time information via Google Search
- Structured Output: Generate JSON and other structured formats
- Thinking Mode: Control reasoning depth with thinking levels
- URL Context: Process web pages directly
The model does not currently support Live API, Google Maps grounding, or audio/image generation natively—for image generation, you'll need Gemini 3 Pro Image (Nano Banana Pro).
When to Choose Gemini 3 Pro
Gemini 3 Pro is the right choice when your application requires maximum intelligence and you can tolerate slightly higher latency. The model shines in competitive programming scenarios, where its enhanced reasoning capabilities provide measurable advantages. Research teams analyzing scientific literature benefit from its ability to process and synthesize information from extensive documents. Development teams working on complex codebases find value in its superior code understanding and generation capabilities.
For cost-sensitive applications or those requiring faster response times, consider Gemini 3 Flash as an alternative.
Gemini 3 Flash: Speed Meets Intelligence
Gemini 3 Flash delivers professional-grade intelligence at Flash-tier speed and pricing, making it ideal for high-throughput applications that still require sophisticated reasoning. It offers the same 1 million token context window as Pro but with additional thinking level options for fine-tuned latency control.
The model positions itself as "our most balanced model, excelling in speed, scale, and frontier intelligence." This makes it particularly attractive for production deployments where cost-effectiveness matters without sacrificing capability.
Key Specifications
| Property | Value |
|---|---|
| Model ID | gemini-3-flash-preview |
| Context Window | 1,048,576 tokens (1M) |
| Max Output | 65,536 tokens |
| Knowledge Cutoff | January 2025 |
| Input Types | Text, Images, Video, Audio, PDF |
| Output Types | Text |
| Status | Preview |
| Free Tier | Available |
Thinking Levels: A Gemini 3 Flash Advantage
Gemini 3 Flash offers four thinking levels, providing granular control over the speed-intelligence tradeoff:
| Level | Use Case | Latency Impact |
|---|---|---|
minimal | Chat applications, high-throughput scenarios | Fastest |
low | Simple instructions, quick responses | Fast |
medium | Most general tasks | Balanced |
high (default) | Complex reasoning, detailed analysis | Slowest |
This flexibility allows developers to dynamically adjust model behavior based on the complexity of each request. A chatbot handling simple queries can use minimal thinking, while the same system switches to high for complex analytical questions.
In contrast, Gemini 3 Pro currently only supports low and high thinking levels, making Flash the more versatile option for applications with varying complexity needs.
Cost-Performance Sweet Spot
At $0.50 per million input tokens and $3.00 per million output tokens, Gemini 3 Flash offers exceptional value. This pricing—combined with its free tier availability—makes it an attractive option for:
- Prototyping and development
- High-volume production workloads
- Applications where response time matters
- Startups and individual developers
For detailed pricing comparisons, see the Pricing Deep Dive section below.
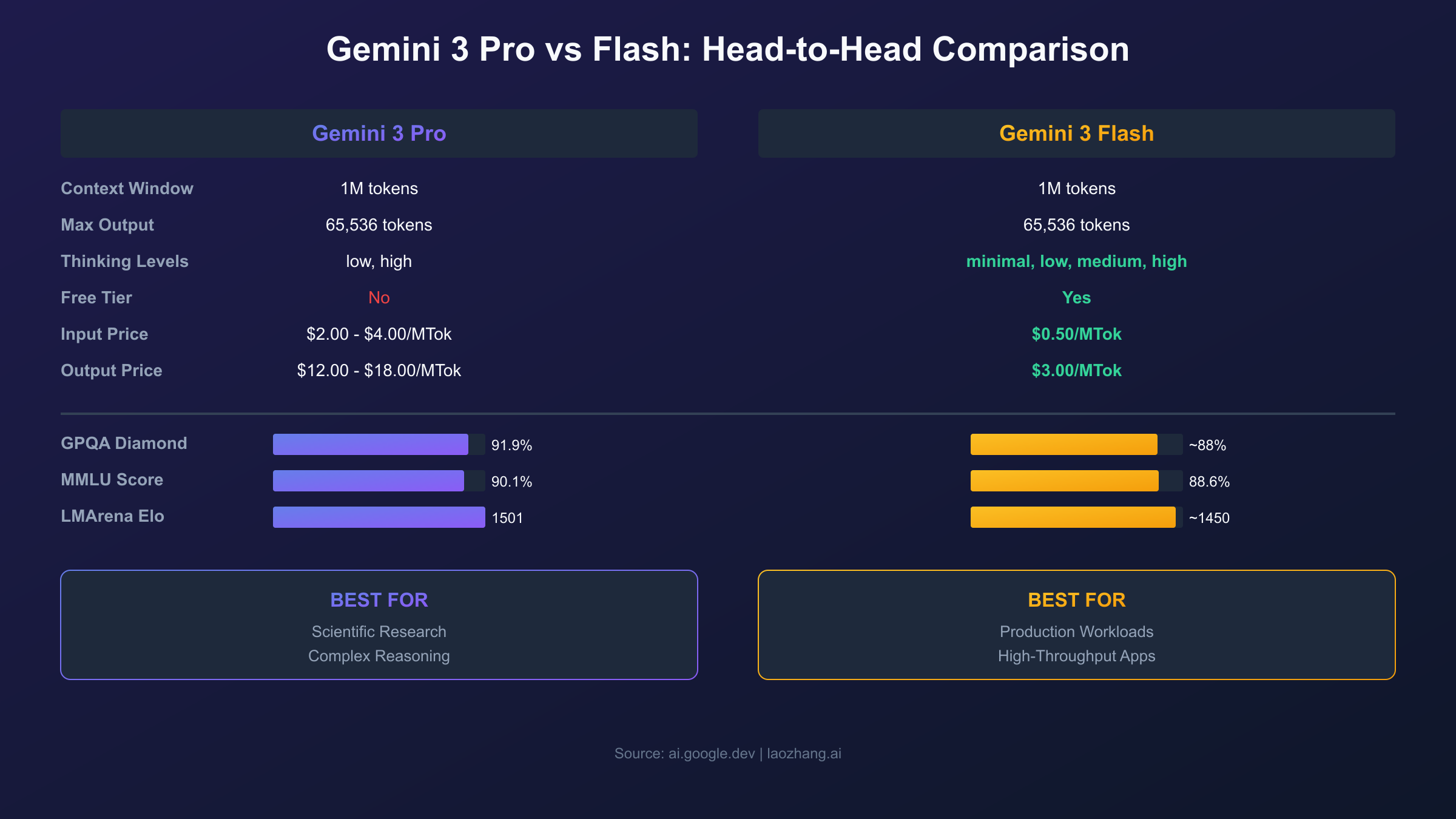
Gemini 3 Pro vs Flash: Head-to-Head Comparison
The choice between Gemini 3 Pro and Flash comes down to whether you prioritize maximum reasoning capability or balanced cost-performance. Both models share the same context window and output limits, but differ significantly in pricing, thinking level options, and optimal use cases.
Feature Comparison Table
| Feature | Gemini 3 Pro | Gemini 3 Flash |
|---|---|---|
| Model ID | gemini-3-pro-preview | gemini-3-flash-preview |
| Context Window | 1M tokens | 1M tokens |
| Max Output | 65,536 tokens | 65,536 tokens |
| Thinking Levels | low, high | minimal, low, medium, high |
| Free Tier | No | Yes |
| Input Price | $2.00/MTok (≤200k) $4.00/MTok (>200k) | $0.50/MTok |
| Output Price | $12.00/MTok (≤200k) $18.00/MTok (>200k) | $3.00/MTok |
| Best For | Complex reasoning, research | High-throughput, production |
Benchmark Performance Differences
While both models perform exceptionally well on standard benchmarks, Gemini 3 Pro maintains a consistent edge in reasoning-intensive tasks:
| Benchmark | Gemini 3 Pro | Gemini 3 Flash | Gap |
|---|---|---|---|
| GPQA Diamond | 91.9% | ~88% | +3.9% |
| MMLU | 90.10% | 88.59% | +1.51% |
| ARC-AGI-2 | 31.1% | ~25% | +6% |
| LMArena Elo | 1501 | ~1450 | +51 |
For most applications, this 2-4% performance gap may not justify the 4-6x price difference. However, for tasks where accuracy is paramount—such as medical research, legal analysis, or scientific computing—the additional capability of Pro could be worthwhile.
Decision Framework
Choose Gemini 3 Pro when:
- Maximum reasoning accuracy is critical
- Working with complex, multi-step analytical tasks
- Budget is secondary to capability
- Building competitive programming or research tools
Choose Gemini 3 Flash when:
- Cost efficiency is important
- Need granular control over latency (minimal/medium thinking)
- Building high-throughput production systems
- Prototyping or in early development stages
- Free tier is sufficient for initial testing
Nano Banana: The Image Generation Revolution
Nano Banana is Google's brand name for native image generation capabilities within the Gemini ecosystem, with Nano Banana Pro (Gemini 3 Pro Image) delivering industry-leading 94-96% text rendering accuracy. This represents a significant advancement over competitors like DALL-E 3 (~78%) and Midjourney V7 (~71%).
The term "Nano Banana" originated from Google AI Studio's internal naming and has been adopted by the developer community. It encompasses both the gemini-2.5-flash-image model and the newer gemini-3-pro-image-preview (Nano Banana Pro).
Nano Banana Model Variants
| Model | ID | Best For | Output Quality |
|---|---|---|---|
| Nano Banana | gemini-2.5-flash-image | General image generation | High |
| Nano Banana Pro | gemini-3-pro-image-preview | Professional, 4K, text-heavy | Highest |
Key Capabilities
Nano Banana Pro brings several groundbreaking capabilities to image generation:
Text-to-Image Generation: Create images from natural language descriptions with exceptional accuracy. The model understands complex compositions and can render readable text within images—a historically challenging task for AI image generators.
Image Editing: Modify existing images using text instructions. Upload an image along with edit requests, and the model produces targeted modifications while preserving the overall composition.
Multi-Turn Modification: Engage in conversational image editing sessions. Each subsequent request builds on the previous result, allowing iterative refinement without starting from scratch.
4K Resolution: Generate images up to 4096×4096 pixels natively, compared to the 1024×1024 ceiling of many competitors.
Reference Image Support: Use up to 14 reference images to guide generation, enabling style transfer and consistent character design.
Nano Banana vs Competitors
| Feature | Nano Banana Pro | DALL-E 3 | Midjourney V7 |
|---|---|---|---|
| Text Accuracy | 94-96% | ~78% | ~71% |
| Max Resolution | 4096×4096 (4K) | 1024×1024 | 1024×1024 |
| Generation Speed | <2 seconds | 15-25 seconds | ~22 seconds |
| API Cost | ~$0.05/image | ~$0.016/image | Subscription |
| Editing Capabilities | Full | Limited | Limited |
| Reference Images | Up to 14 | None | Limited |
Nano Banana Pro excels in scenarios requiring text within images, high resolution, or iterative editing. DALL-E 3 remains cost-effective for simple generations, while Midjourney continues to lead in artistic and atmospheric compositions. For a deeper comparison, see our Nano Banana vs DALL-E guide.
Pricing for Image Generation
| Model | Input (Text) | Output (1K/2K Image) | Output (4K Image) |
|---|---|---|---|
| Nano Banana Pro | $2.00/MTok | $0.134/image | $0.24/image |
| Nano Banana | $1.00/MTok | $0.067/image | $0.12/image |
For cost optimization strategies with Nano Banana, check our Nano Banana Pro cost guide.
Pricing Analysis: Getting the Best Value
Understanding Gemini 3 pricing requires considering not just base rates but also context caching, long-context premiums, and comparison with alternatives. The pricing structure rewards efficient API usage patterns while remaining competitive with other frontier models.
Gemini 3 Base Pricing
| Model | Input (≤200k) | Input (>200k) | Output (≤200k) | Output (>200k) |
|---|---|---|---|---|
| Gemini 3 Pro | $2.00 | $4.00 | $12.00 | $18.00 |
| Gemini 3 Flash | $0.50 | - | $3.00 | - |
| Gemini 3 Pro Image | $2.00 (text) | - | See image pricing | - |
Prices per million tokens unless otherwise noted
Context Caching: Reduce Costs by 90%
Context caching allows you to store frequently-used context (like system prompts or reference documents) and reuse it across multiple requests at a fraction of the cost:
| Model | Cached Input (≤200k) | Cached Input (>200k) | Storage (hourly) |
|---|---|---|---|
| Gemini 3 Pro | $0.20/MTok | $0.40/MTok | $4.50/MTok |
| Gemini 3 Flash | $0.05/MTok | $0.10/MTok | $1.00/MTok |
For applications with repeated context, this represents a 90% cost reduction on input tokens.
Comparison with Competitors
| Model | Input | Output | Context Window |
|---|---|---|---|
| Gemini 3 Pro | $2.00-4.00 | $12.00-18.00 | 1M |
| Gemini 3 Flash | $0.50 | $3.00 | 1M |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K (1M beta) |
| Claude Opus 4.5 | $5.00 | $25.00 | 200K |
| GPT-5.1 | $1.25 | $10.00 | 128K |
Key Observations:
- Gemini 3 Flash offers the best value for high-volume applications
- Gemini 3 Pro's 1M context window at competitive pricing provides unique value for long-document processing
- Claude and GPT models have smaller context windows at higher or comparable prices
Cost Optimization Strategies
For developers looking to minimize API costs while maintaining quality, several strategies prove effective. Using context caching for repeated system prompts and reference documents can reduce input costs by up to 90%. Implementing dynamic model selection allows routing simple queries to Flash while reserving Pro for complex tasks. Optimizing prompt length by removing unnecessary context reduces token consumption. Batch processing through the Batch API provides additional discounts for non-time-sensitive workloads.
For an alternative access method with potentially better pricing, developers can explore platforms like laozhang.ai, which aggregate multiple AI providers with unified API access.
Benchmark Performance: The Real Numbers
Gemini 3 Pro achieves an unprecedented 91.9% on GPQA Diamond and becomes the first model to break the 1500 barrier on LMArena Elo, establishing new benchmarks for AI reasoning capabilities. These results position it as the leading model for scientific and analytical tasks.
Reasoning Benchmarks
| Benchmark | Gemini 3 Pro | Gemini 3 Pro (Deep Think) | GPT-5.1 | Claude Opus 4.5 |
|---|---|---|---|---|
| GPQA Diamond | 91.9% | 93.8% | 88.1% | ~87% |
| ARC-AGI-2 | 31.1% | 45.1% | 17.6% | ~15% |
| Humanity's Last Exam | 37.5% | 40%+ | ~27% | ~25% |
The GPQA Diamond benchmark tests PhD-level scientific knowledge and reasoning. Gemini 3 Pro's 91.9% score (93.8% with Deep Think mode) surpasses human expert performance (~89.8%), representing a significant milestone in AI capability.
ARC-AGI-2 measures abstract visual reasoning—a task that has historically challenged large language models. Gemini 3 Pro's jump from Gemini 2.5 Pro's 4.9% to 31.1% (45.1% with Deep Think) indicates a core improvement in non-verbal problem-solving capabilities.
Knowledge and Language Benchmarks
| Benchmark | Gemini 3 Pro | Gemini 3 Flash | Claude Opus 4.5 | GPT-5.1 |
|---|---|---|---|---|
| MMLU | 90.10% | 88.59% | 87.92% | ~89% |
| Language Understanding | 91.8% | - | - | ~90% |
On knowledge tests like MMLU, all frontier models operate at or above the level of a well-educated human in many domains. Gemini 3 Pro holds a slight edge, though the practical difference at these levels may be minimal for most applications.
Coding Benchmarks
| Benchmark | Gemini 3 Pro | Claude Sonnet 4.5 | GPT-5.1 Codex |
|---|---|---|---|
| SWE-bench Verified | 76.2% | 77.2% | ~78% |
Coding benchmarks show a more competitive landscape. Claude Sonnet 4.5 leads SWE-bench Verified at 77.2%, with GPT-5.1 Codex close behind. Gemini 3 Pro's 76.2% represents a significant improvement from Gemini 2.5 Pro's 59.6%, closing the gap with competitors.
LMArena Elo Rankings
| Model | Elo Score |
|---|---|
| Gemini 3 Pro | 1501 |
| GPT-5.1 | ~1480 |
| Claude Opus 4.5 | ~1470 |
| Gemini 3 Flash | ~1450 |
Gemini 3 Pro's 1501 LMArena Elo makes it the first model to break the 1500 barrier, indicating consistent performance across diverse real-world tasks.
For detailed benchmark methodology and more comparisons, see Artificial Analysis and LM Council.
Gemini 3 vs Claude 4.5 vs GPT-5: The Ultimate Showdown
Each frontier model excels in different areas: Gemini 3 Pro leads reasoning benchmarks, Claude 4.5 dominates software engineering, and GPT-5 offers the best developer ecosystem. Understanding these strengths helps match the right model to your specific use case.
Feature Comparison
| Feature | Gemini 3 Pro | Claude Opus 4.5 | GPT-5.1 |
|---|---|---|---|
| Context Window | 1M tokens | 200K (1M beta) | 128K |
| Max Output | 65,536 | 64,000 | 32,000 |
| Vision | Yes | Yes | Yes |
| Code Execution | Yes | Yes (Bash/Editor tools) | Yes |
| Web Search | Yes (native) | Yes (web search tool) | Yes |
| Image Generation | Yes (separate model) | No | Yes (separate model) |
| Knowledge Cutoff | Jan 2025 | May 2025 | - |
Pricing Comparison
| Model | Input (per MTok) | Output (per MTok) |
|---|---|---|
| Gemini 3 Pro | $2.00-4.00 | $12.00-18.00 |
| Gemini 3 Flash | $0.50 | $3.00 |
| Claude Opus 4.5 | $5.00 | $25.00 |
| Claude Sonnet 4.5 | $3.00 | $15.00 |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| GPT-5.1 | $1.25 | $10.00 |
Strengths and Weaknesses
Gemini 3 Pro Strengths:
- Largest context window (1M tokens) at competitive pricing
- Best reasoning benchmarks (GPQA, ARC-AGI-2)
- Native Google Search integration
- Multimodal input support
Gemini 3 Pro Weaknesses:
- Preview status (not yet stable)
- Higher latency for complex reasoning
- No native image generation (requires Pro Image)
Claude 4.5 Strengths:
- Leading coding performance (SWE-bench)
- Extended agentic operation (30+ hours)
- Natural, nuanced writing style
- Most recent knowledge cutoff (May 2025)
Claude 4.5 Weaknesses:
- Smaller context window (200K standard)
- No native image generation
- Higher pricing at Opus tier
GPT-5.1 Strengths:
- Best developer ecosystem (Copilot, Cursor)
- Balanced cost-performance
- Adaptive reasoning
- Extensive IDE integration
GPT-5.1 Weaknesses:
- Smallest context window (128K)
- No public API pricing for latest features
- Less transparent model versioning
Recommendation Matrix
| Use Case | Recommended Model | Why |
|---|---|---|
| Scientific research | Gemini 3 Pro | Best reasoning, 1M context |
| Software engineering | Claude Sonnet 4.5 | Top SWE-bench, natural code |
| General development | GPT-5.1 | Ecosystem, cost balance |
| High-volume chat | Gemini 3 Flash | Cost-effective, fast |
| Long document analysis | Gemini 3 Pro | 1M context native |
| Creative writing | Claude | Most natural style |
| Image generation | Nano Banana Pro | Text accuracy, 4K |
For a more detailed comparison, see our guide on GPT-5 vs Gemini 3 Pro vs Claude Opus 4.5.
New Features in Gemini 3: What's Different
Gemini 3 introduces thinking levels, media resolution control, and thinking signatures—new parameters that give developers fine-grained control over model behavior. These features enable optimization for specific use cases without changing models.
Thinking Levels Explained
Thinking levels control how much "reasoning" the model performs before generating a response. Higher levels mean deeper analysis but increased latency and cost.
hljs pythonfrom google import genai
from google.genai import types
client = genai.Client()
# Low thinking for simple tasks
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="What is 2+2?",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="low")
),
)
# High thinking for complex reasoning
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="Analyze the economic implications of quantum computing adoption",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="high")
),
)
| Level | Description | Best For |
|---|---|---|
| minimal | Nearly no thinking, maximum speed | Chat, simple Q&A |
| low | Minimal reasoning overhead | Standard queries |
| medium | Balanced thinking | General tasks |
| high | Maximum reasoning depth | Complex analysis |
Note: minimal and medium are only available on Gemini 3 Flash.
Media Resolution Control
New in Gemini 3, the media_resolution parameter controls token allocation for image and video processing:
hljs python# High resolution for detailed image analysis
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents=[
types.Content(
parts=[
types.Part(text="Identify all text in this image"),
types.Part(
inline_data=types.Blob(
mime_type="image/jpeg",
data=image_bytes,
),
media_resolution={"level": "media_resolution_high"}
)
]
)
]
)
Higher resolution means better detail recognition but increased token consumption and cost.
Thinking Signatures
Gemini 3 can return "thinking signatures"—metadata about the reasoning process used to generate a response. This helps debug model behavior and understand why certain conclusions were reached.
OpenAI Compatibility
Gemini 3 maintains compatibility with OpenAI's API format, making migration straightforward:
hljs pythonfrom openai import OpenAI
# Using OpenAI SDK with Gemini
client = OpenAI(
api_key="YOUR_GEMINI_API_KEY",
base_url="https://generativelanguage.googleapis.com/v1beta/openai/"
)
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Hello!"}]
)
This compatibility layer enables seamless migration between different AI providers with minimal code changes.
Getting Started: API Integration Guide
Integrating Gemini 3 into your application requires an API key from Google AI Studio and choosing between the official SDK or REST API. The process is straightforward and compatible with existing OpenAI workflows.
Step 1: Get Your API Key
- Visit Google AI Studio
- Sign in with your Google account
- Create a new API key
- Copy and securely store the key
Step 2: Install the SDK
Python:
hljs bashpip install google-genai
JavaScript:
hljs bashnpm install @google/genai
Step 3: Make Your First Request
Python Example:
hljs pythonfrom google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="Explain quantum computing in simple terms"
)
print(response.text)
JavaScript Example:
hljs javascriptimport { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({ apiKey: "YOUR_API_KEY" });
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: "Explain quantum computing in simple terms",
});
console.log(response.text);
}
main();
cURL Example:
hljs bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum computing in simple terms"}]
}]
}'
Alternative: OpenAI-Compatible Endpoint
For projects already using OpenAI's SDK, you can use Gemini through the compatibility layer:
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://generativelanguage.googleapis.com/v1beta/openai/"
)
response = client.chat.completions.create(
model="gemini-3-flash-preview",
messages=[{"role": "user", "content": "Hello!"}]
)
For developers seeking cost optimization or improved access from certain regions, third-party aggregator platforms offer unified API access with OpenAI-compatible endpoints.
Best Practices
When integrating Gemini 3 into production systems, several practices improve reliability and cost efficiency. Implementing retry logic with exponential backoff handles transient errors gracefully. Using context caching for repeated prompts reduces costs significantly. Setting appropriate thinking levels based on task complexity optimizes the latency-quality tradeoff. Monitoring token usage helps identify optimization opportunities.
For rate limit guidance, see our Gemini API quota guide.
Migration Guide: From Gemini 2.x to 3.x
Gemini 2.0 Flash and 2.0 Flash-Lite are deprecated and will be shut down on March 31, 2026—migration to Gemini 2.5 or 3.x is required to avoid service disruption. The migration process is straightforward for most applications.
Deprecation Timeline
| Model | Status | Shutdown Date |
|---|---|---|
| Gemini 2.0 Flash | Deprecated | March 31, 2026 |
| Gemini 2.0 Flash-Lite | Deprecated | March 31, 2026 |
| Gemini 1.x | Already retired | 404 errors |
Model ID Mapping
| Old Model | Recommended Replacement |
|---|---|
| gemini-2.0-flash | gemini-3-flash-preview or gemini-2.5-flash |
| gemini-2.0-flash-lite | gemini-2.5-flash-lite |
| gemini-1.5-pro | gemini-3-pro-preview |
| gemini-1.5-flash | gemini-3-flash-preview |
Breaking Changes
Thinking Configuration: Gemini 3 uses thinking_level instead of thinking_budget. Using both in the same request returns a 400 error.
hljs python# Old (Gemini 2.5)
config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_budget=1000)
)
# New (Gemini 3)
config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="high")
)
Media Resolution: New parameter for controlling image/video token allocation. Not available in Gemini 2.x.
Model Aliases: The -latest alias behavior may change. Use specific model versions for production stability.
Migration Checklist
Before migrating to Gemini 3, follow this checklist to ensure a smooth transition:
- Audit current usage: Identify which Gemini 2.x models your application uses
- Review feature dependencies: Check if you rely on features not yet available in Gemini 3 (e.g., Live API)
- Update model IDs: Replace old model strings with new ones
- Adjust thinking configuration: Migrate from
thinking_budgettothinking_level - Test thoroughly: Run your test suite against the new models
- Monitor costs: Gemini 3 pricing differs—verify budget impact
- Deploy gradually: Use canary deployments to catch issues early
Handling Preview Status
Gemini 3 models are currently in preview. For production applications:
- Implement fallback to Gemini 2.5 stable models
- Monitor Google's release notes for stable releases
- Plan for potential API changes during preview period
Model Selection Framework: Choosing the Right Model
The optimal Gemini 3 model depends on your specific requirements for intelligence, speed, cost, and features. Use this decision framework to identify the best fit for your use case.
Decision Flowchart
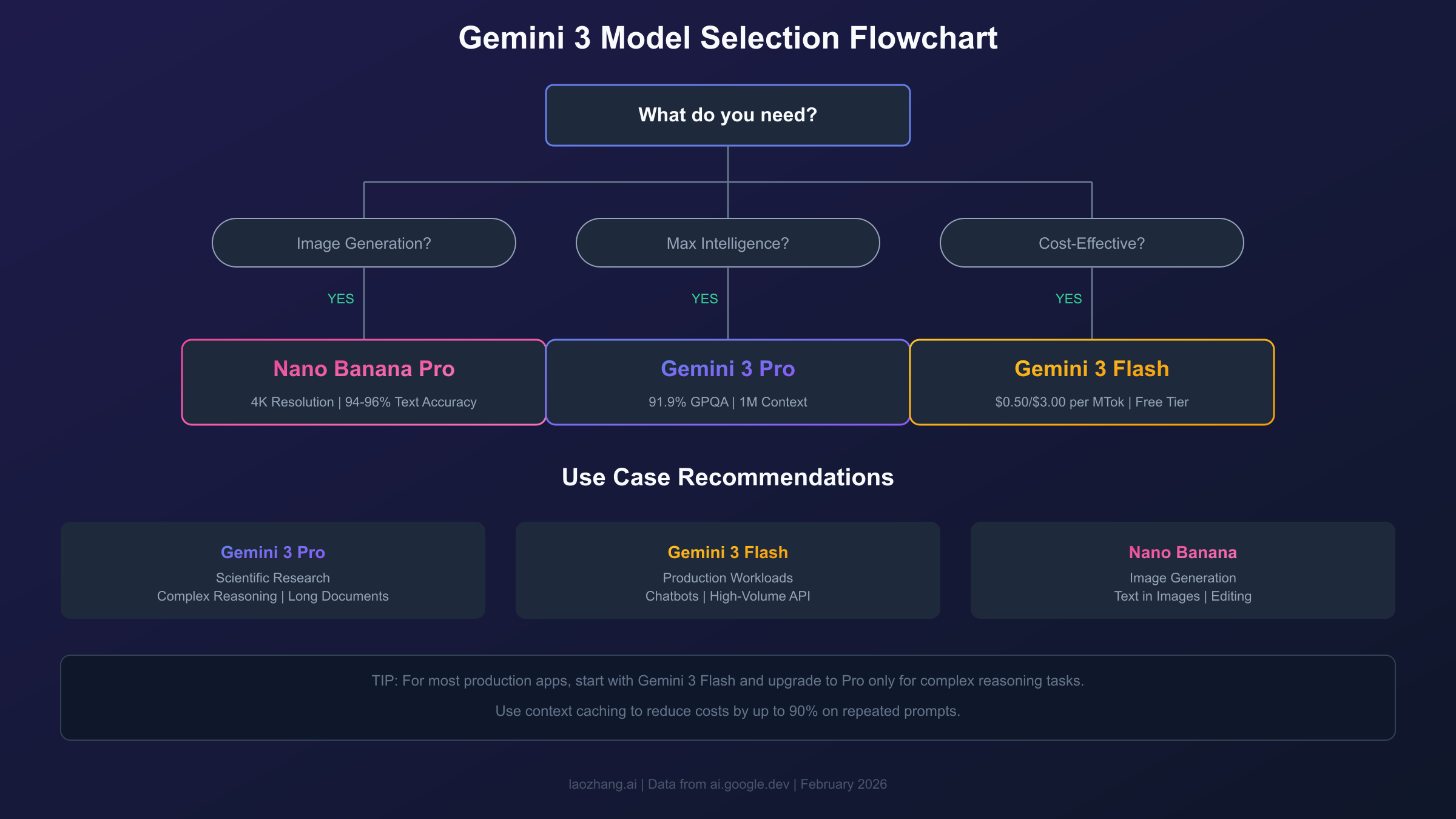
Use Case Recommendations
| Use Case | Recommended Model | Reasoning |
|---|---|---|
| Scientific research | Gemini 3 Pro | Best reasoning, 1M context |
| Coding assistant | Gemini 3 Flash | Balance of capability and cost |
| Chat applications | Gemini 3 Flash (minimal) | Fastest response time |
| Document analysis | Gemini 3 Pro | 1M context for long documents |
| Image generation | Nano Banana Pro | Best quality, 4K support |
| High-volume API | Gemini 3 Flash | Cost-effective at scale |
| Prototyping | Gemini 3 Flash | Free tier available |
Cost-Sensitive Scenarios
For budget-constrained applications, consider this progression:
- Start with Flash Free Tier: Test and iterate without cost
- Move to Flash Paid: When volume exceeds free limits
- Add Pro for Complex Tasks: Route only complex queries to Pro
- Implement Caching: Reduce costs by 90% on repeated context
When to Use Competitors Instead
While Gemini 3 excels in many areas, consider alternatives for specific needs:
- Coding with context awareness: Claude Sonnet 4.5 leads SWE-bench
- Creative writing: Claude produces more natural prose
- IDE integration: GPT-5.1 has deeper Copilot/Cursor support
- Artistic image generation: Midjourney for stylistic compositions
The best approach often involves intelligent model routing—using the right model for each specific task rather than defaulting to one provider.
Frequently Asked Questions
What is the difference between Gemini 3 Pro and Flash?
Gemini 3 Pro is optimized for maximum intelligence and complex reasoning tasks, achieving 91.9% on GPQA Diamond benchmarks. Gemini 3 Flash offers a balance of speed and capability at lower cost ($0.50 vs $2.00 input), with additional thinking level options (minimal, medium) for fine-tuned latency control. Both share the same 1M token context window, but Pro is better for research and complex analysis, while Flash suits high-throughput production workloads.
What is Nano Banana?
Nano Banana is Google's brand name for native image generation capabilities within the Gemini ecosystem. The name originated from Google AI Studio's internal naming conventions. Nano Banana Pro (gemini-3-pro-image-preview) is the highest-quality variant, achieving 94-96% text rendering accuracy compared to DALL-E 3's 78% and Midjourney V7's 71%. It supports up to 4K resolution and multi-turn image editing.
How much does Gemini 3 API cost?
Gemini 3 Pro costs $2.00/MTok input and $12.00/MTok output for prompts under 200K tokens, with higher rates for longer contexts. Gemini 3 Flash costs $0.50/MTok input and $3.00/MTok output with a free tier available. Context caching reduces input costs by up to 90%. Nano Banana Pro image generation costs approximately $0.134 per 1K/2K image and $0.24 per 4K image.
Is Gemini 3 better than Claude 4.5?
It depends on the use case. Gemini 3 Pro leads in reasoning benchmarks (91.9% GPQA vs ~87%) and offers a larger 1M context window. Claude 4.5 Sonnet leads in software engineering tasks (77.2% SWE-bench vs 76.2%) and produces more natural writing. For scientific research and long-document analysis, choose Gemini 3 Pro. For coding and creative writing, Claude 4.5 may be preferable.
When will Gemini 3 stable be released?
Google has not announced a specific date for Gemini 3 stable releases. All current Gemini 3 models (Pro, Flash, Pro Image) are in preview status. Based on previous patterns, stable releases typically follow several months after preview. Monitor Google AI's release notes for announcements.
Can I use Gemini 3 for production applications?
Yes, but with caveats. Preview models may have API changes and more restrictive rate limits. For production use, implement fallback mechanisms to stable Gemini 2.5 models, handle potential API changes gracefully, and test thoroughly before deployment. Google bills for preview model usage, making them suitable for production if you accept the preview status risks.
How do I migrate from Gemini 2.x?
Update your model IDs (e.g., gemini-2.0-flash → gemini-3-flash-preview), migrate thinking_budget to thinking_level parameters, and test your application. Gemini 2.0 Flash and Flash-Lite will be shut down on March 31, 2026, so migration is required. See the Migration Guide section for detailed steps.
What are thinking levels in Gemini 3?
Thinking levels control how much reasoning the model performs before responding. Gemini 3 supports low and high levels (Pro) or minimal, low, medium, and high (Flash). Higher levels mean deeper analysis but increased latency. Use minimal for chat, low for simple queries, medium for general tasks, and high for complex reasoning.
How does Nano Banana compare to DALL-E?
Nano Banana Pro excels in text rendering (94-96% vs 78%), resolution (4K vs 1K), and generation speed (<2s vs 15-25s). DALL-E 3 is more cost-effective ($0.016 vs ~$0.05 per image) and integrates with ChatGPT ecosystem. Choose Nano Banana for text-heavy images, high resolution, or iterative editing; choose DALL-E for cost-sensitive bulk generation.
Can I access Gemini 3 from China?
Direct access to Google AI services is restricted in China. Developers can use VPN solutions or alternative API providers like laozhang.ai that aggregate AI services with better regional accessibility. These platforms typically offer OpenAI-compatible endpoints, making integration straightforward for existing projects.
Conclusion
Gemini 3 represents a significant advancement in AI capabilities, with each model serving distinct purposes: Pro for maximum intelligence (91.9% GPQA Diamond, 1501 LMArena Elo), Flash for balanced cost-performance ($0.50/$3.00 with free tier), and Nano Banana Pro for industry-leading image generation (94-96% text accuracy, 4K support).
The choice between models depends on your specific needs. Use Gemini 3 Pro when reasoning accuracy is paramount and budget allows. Choose Gemini 3 Flash for production workloads requiring speed and cost efficiency. Deploy Nano Banana Pro for image generation tasks, especially those involving text or requiring high resolution.
For developers currently on Gemini 2.x, migration is straightforward but time-sensitive—Gemini 2.0 models sunset March 31, 2026. The new thinking level controls and context caching features provide optimization opportunities not available in earlier versions.
As the AI landscape continues evolving rapidly, intelligent model routing—choosing the right model for each task rather than defaulting to one—becomes increasingly important. Gemini 3, Claude 4.5, and GPT-5 each have strengths worth leveraging. The winners will be developers who match the right tool to each job.
Ready to get started? Generate your API key and begin building with Gemini 3 today.