GPT-5.2 vs Gemini 3 Pro vs Claude Opus 4.5: The Ultimate AI Model Comparison Guide [2025]
Comprehensive comparison of GPT-5.2, Gemini 3 Pro, and Claude Opus 4.5 covering benchmarks, pricing, coding performance, and real-world testing. Find the best AI model for your needs.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

The AI landscape shifted dramatically in late 2025 when three tech giants released their most powerful models within weeks of each other. Google launched Gemini 3 Pro on November 18, Anthropic responded with Claude Opus 4.5 just six days later on November 24, and OpenAI completed the trilogy with GPT-5.2 on December 11. This rapid-fire release schedule, dubbed "AI's Red Wedding" by industry observers, has left developers and businesses with a critical question: which model should they actually use?
After extensive testing across coding tasks, reasoning benchmarks, and real-world applications, one truth has emerged—there is no universal winner. Each model excels in specific domains while showing weaknesses in others. GPT-5.2 dominates abstract reasoning with a 54.2% score on ARC-AGI-2, Claude Opus 4.5 leads coding benchmarks at 80.9% on SWE-bench Verified, and Gemini 3 Pro offers the best multimodal capabilities with its million-token context window. The right choice depends entirely on your specific use case, budget constraints, and workflow requirements.
This comprehensive guide cuts through marketing claims to deliver actionable insights based on verified benchmarks and independent testing. Whether you need the smartest reasoning engine, the most reliable coding assistant, or the most cost-effective API for high-volume workloads, the data presented here will guide your decision. Let's examine exactly how these three frontier models compare across every metric that matters.
Quick Comparison: GPT-5.2 vs Gemini 3 Pro vs Claude Opus 4.5
Before diving into detailed analysis, here's a snapshot of the key specifications and capabilities that differentiate these three frontier models:
| Specification | GPT-5.2 | Gemini 3 Pro | Claude Opus 4.5 |
|---|---|---|---|
| Release Date | December 11, 2025 | November 18, 2025 | November 24, 2025 |
| Developer | OpenAI | Anthropic | |
| Context Window (Input) | 400,000 tokens | 1,000,000 tokens | 200,000 tokens |
| Context Window (Output) | 128,000 tokens | 64,000 tokens | 32,000 tokens |
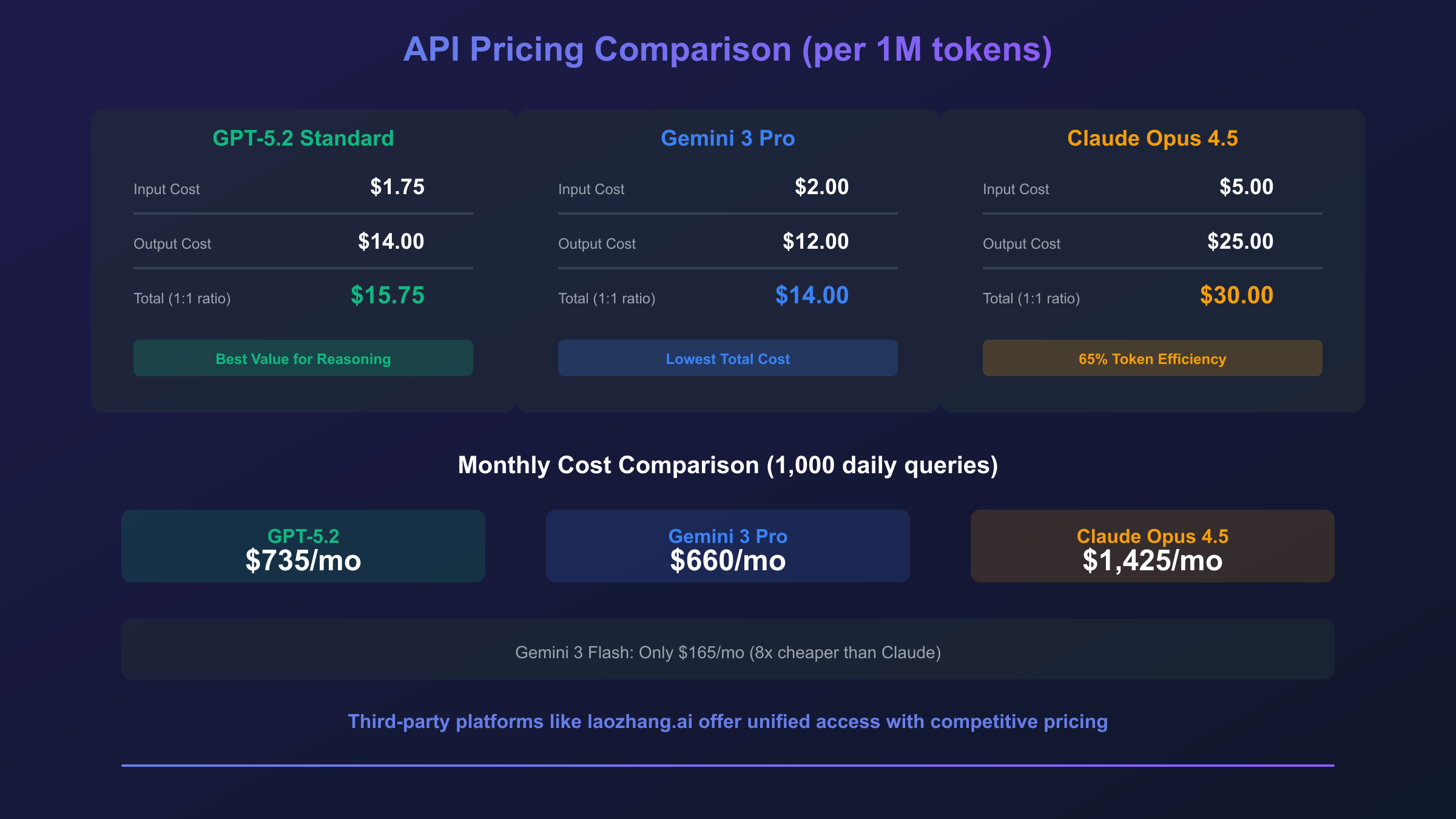
| API Input Cost | $1.75/1M tokens | $2.00/1M tokens | $5.00/1M tokens |
| API Output Cost | $14.00/1M tokens | $12.00/1M tokens | $25.00/1M tokens |
| SWE-bench Verified | 80.0% | 76.2% | 80.9% |
| ARC-AGI-2 | 54.2% (Pro) | 31.1% | 37.6% |
| AIME 2025 | 100% | 95% | 100% |
| Native Video Support | Limited | Full | Limited |
| Model Variants | Instant, Thinking, Pro | Standard, Flash | Standard, Thinking |
The table reveals several immediate insights. Gemini 3 Pro offers the largest context window at one million tokens—five times larger than GPT-5.2 and five times larger than Claude Opus 4.5. This makes Gemini ideal for processing entire codebases, lengthy documents, or extended video content in a single prompt. However, Claude Opus 4.5 commands premium pricing at $5/$25 per million tokens compared to GPT-5.2's $1.75/$14, reflecting Anthropic's positioning as the choice for quality-critical applications.
The benchmark scores tell a nuanced story. Claude Opus 4.5 edges out GPT-5.2 by 0.9 percentage points on SWE-bench Verified, making it the first model to cross the 80% threshold on this real-world software engineering test. Yet GPT-5.2 Pro dominates abstract reasoning, scoring 54.2% on ARC-AGI-2 compared to Claude's 37.6%—a 44% relative improvement. Both OpenAI and Anthropic's models achieve perfect scores on AIME 2025 mathematics problems without external tools, while Gemini 3 Pro trails at 95%.
These numbers matter because they translate directly to real-world performance differences. A developer choosing between models needs to understand not just which model scores highest on aggregate benchmarks, but which excels at their specific tasks. The following sections break down performance across coding, reasoning, multimodal processing, and cost-effectiveness to help you make that determination.
Benchmark Performance Deep Dive
Benchmarks provide standardized measurements of AI capability, though they don't tell the complete story. Understanding what each benchmark measures—and its limitations—helps interpret these scores meaningfully.
Coding Benchmarks
| Benchmark | GPT-5.2 | GPT-5.2 Codex | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 80.0% | 80.0% | 80.9% | 76.2% |
| SWE-bench Pro | 55.6% | — | — | 43.4% |
| Terminal-Bench 2.0 | 47.6% | — | 54.2% | — |
| Aider Polyglot | — | — | 89.4% | — |
| LiveCodeBench | — | — | +16 p.p.* | — |
*Improvement over previous Claude version
SWE-bench Verified tests models on real GitHub issues from popular open-source projects. The test requires understanding existing codebases, identifying bugs, and generating patches that pass the project's test suite. Claude Opus 4.5's 80.9% score represents a significant milestone—it means the model successfully resolves roughly four out of five real-world software engineering problems on the first attempt.
Terminal-Bench 2.0 evaluates command-line operations and system administration tasks. Claude's 54.2% score versus GPT-5.2's 47.6% suggests stronger performance on DevOps-style workflows. However, Gemini 3 Pro's absence from this benchmark makes direct three-way comparison impossible. The Aider Polyglot benchmark tests multilingual coding across eight programming languages, where Claude Opus 4.5 achieves 89.4%—demonstrating strong versatility beyond Python-centric tasks.
Reasoning Benchmarks
| Benchmark | GPT-5.2 Thinking | GPT-5.2 Pro | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| ARC-AGI-1 | 86.2% | 90%+ | — | — |
| ARC-AGI-2 | 52.9% | 54.2% | 37.6% | 31.1% |
| GPQA Diamond | 92.4% | 93.2% | — | 91.9% |
| FrontierMath (Tier 1-3) | 40.3% | — | — | — |
| AIME 2025 | 100% | 100% | 100%* | 95% |
*Requires thinking mode
ARC-AGI tests abstract reasoning through novel puzzles that cannot be solved through pattern matching on training data. GPT-5.2 Pro's 54.2% score on ARC-AGI-2 represents a major leap—the first time any commercial model has crossed the 50% threshold on this notoriously difficult benchmark. Claude Opus 4.5's 37.6% and Gemini 3 Pro's 31.1% show that abstract reasoning remains GPT-5.2's strongest differentiator.
GPQA Diamond evaluates graduate-level science knowledge through "Google-proof" questions designed to be unanswerable through simple search. GPT-5.2 Pro leads at 93.2%, followed closely by GPT-5.2 Thinking at 92.4% and Gemini 3 Pro at 91.9%. This tight clustering suggests all three frontier models have reached near-parity on scientific knowledge retrieval.
Intelligence Index Rankings
The Artificial Analysis Intelligence Index provides a composite score normalizing across multiple benchmarks. Current standings place Gemini 3 Pro at 73 points, followed by GPT-5.1 (high) and Claude Opus 4.5 tied at 70 points. This ranking reflects Gemini's multimodal strength but may underweight GPT-5.2's reasoning advantages since the index was calibrated before its release.
The key insight from benchmark analysis is domain specialization. GPT-5.2 dominates pure reasoning tasks. Claude Opus 4.5 leads practical software engineering. Gemini 3 Pro excels at multimodal understanding. No single model wins across all categories, which explains why professional developers increasingly use multi-model workflows rather than committing to a single provider.
Real-World Coding Performance
Benchmarks measure capability under controlled conditions. Real-world testing reveals how models perform on messy, ambiguous, production-grade challenges. Independent testers have published extensive comparisons of GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro on practical coding tasks.
Test Case 1: Python Rate Limiter Implementation
A test required implementing a TokenBucketLimiter class with ten specific requirements including exact method signatures, error message formatting, and edge case handling. The results revealed stark differences in implementation quality:
| Model | Score | Time | Cost | Key Observation |
|---|---|---|---|---|
| GPT-5.2 Pro | 100% | 59 min | $23.99 | Perfect but impractically slow |
| Claude Opus 4.5 | 95% | 7 min | $1.68 | Fast, complete, practical |
| GPT-5.2 | 95% | — | $0.20 | Good balance of speed/cost |
| Gemini 3 Pro | 100% | — | $0.09 | Shortest code (90 lines) |
Claude Opus 4.5 emerged as the practical winner—achieving 95% correctness in just seven minutes at $1.68 total cost. GPT-5.2 Pro achieved perfect scores but consumed 59 minutes and $23.99, making it impractical for iterative development. Gemini 3 Pro produced the most concise implementation at just 90 lines but required multiple iterations to pass all test cases.
Test Case 2: TypeScript Refactoring
A 365-line API handler containing SQL injection vulnerabilities, inconsistent naming, and missing security features needed transformation into clean layered architecture. This test evaluated models' ability to understand existing code and apply systematic improvements:
| Model | Score | Key Strengths | Key Weaknesses |
|---|---|---|---|
| Claude Opus 4.5 | 95% | Full security implementation, rate limiting with headers | — |
| GPT-5.2 Pro | 95% | Identified architectural flaws, required env variables | Very slow |
| GPT-5.2 | 90% | Removed unnecessary validation, more concise | Incomplete templates |
| Gemini 3 Pro | 75% | Precise literal interpretation | Missed rate limiting entirely |
Claude Opus 4.5 and GPT-5.2 Pro tied at 95%, but with radically different cost profiles. Claude completed the refactoring with comprehensive security implementations including CSRF protection and input validation. GPT-5.2 Pro went further by identifying underlying design flaws in the original code—but this deeper analysis consumed significantly more time and cost.
Gemini 3 Pro's 75% score revealed a critical limitation: the model interpreted prompts too literally, implementing exactly what was specified without inferring implicit requirements like rate limiting. This behavior makes Gemini risky for underspecified tasks where developers expect the AI to fill gaps.
Test Case 3: Email Notification Handler
Adding an EmailHandler to match an existing notification system's patterns tested models' ability to understand architectural conventions and maintain consistency:
| Model | Templates Provided | Rate Limiting | Production Ready |
|---|---|---|---|
| Claude Opus 4.5 | 7/7 | Full headers | Yes |
| GPT-5.2 Pro | 7/7 | Full headers | Yes |
| GPT-5.2 | 4/7 | Partial | Needs hardening |
| Gemini 3 Pro | Minimal | Missing | Scaffold only |
Claude Opus 4.5 delivered production-ready code with all seven notification templates, comprehensive rate limiting headers, and proper error handling. GPT-5.2 Pro matched this quality but consumed 21 minutes versus Claude's sub-minute completion. Standard GPT-5.2 provided a functional implementation missing three templates—acceptable for prototyping but requiring manual completion for production.
Aggregate Testing Recommendations
Based on real-world testing data, here are practical recommendations for different development scenarios:
For production deployments requiring correctness over speed, Claude Opus 4.5 provides the optimal balance. It achieves GPT-5.2 Pro-level quality at a fraction of the cost and time. The model consistently ships working demos on first attempt with comprehensive feature coverage.
For rapid prototyping where iteration speed matters more than completeness, standard GPT-5.2 offers practical tradeoffs. It's 17% cheaper per run than Claude while delivering solid architectural decisions. Expect to fill gaps manually but benefit from faster turnaround.
For critical architecture decisions where correctness justifies any cost, GPT-5.2 Pro's deep analysis capabilities find value. It's the only model that proactively identified and fixed underlying design flaws in test systems—worth the premium for high-stakes refactoring.
For simple, well-specified tasks with clear requirements, Gemini 3 Pro delivers clean implementations economically. Its literal interpretation works well when prompts are complete but creates risk for ambiguous specifications.

Multimodal Capabilities Comparison
The 2025 frontier models have diverged significantly in their multimodal approaches. Gemini 3 Pro was designed from the ground up as natively multimodal, while GPT-5.2 and Claude Opus 4.5 treat non-text modalities as secondary features.
Native Multimodal Support
| Capability | GPT-5.2 | Gemini 3 Pro | Claude Opus 4.5 |
|---|---|---|---|
| Text Processing | Full | Full | Full |
| Image Understanding | Full | Full | Full |
| Image Generation | Via DALL-E | Via Imagen 3 | Limited |
| Video Understanding | Limited | Full native | Limited |
| Video Generation | Via Sora | Via Veo 2 | None |
| Audio Processing | Limited | Full native | Limited |
| PDF Analysis | Full | Full | Full |
Gemini 3 Pro's native multimodal architecture creates unique capabilities unavailable in competing models. The model processes video at up to 70 tokens per frame (low resolution) or 290 tokens per frame (high resolution), enabling analysis of hours of footage in a single prompt. Combined with its million-token context window, Gemini can analyze feature-length films, multi-hour meeting recordings, or extensive surveillance footage—tasks impossible for competitors.
The Video-MMMU benchmark specifically tests video understanding, where Gemini 3 Pro achieves 87.6%—a score neither GPT-5.2 nor Claude Opus 4.5 can match due to architectural limitations. For workflows centered on video content analysis, Gemini has no real competition among frontier models.
Image Understanding Tests
Independent testing on visual simulation tasks revealed interesting performance patterns. When asked to render a photorealistic Golden Gate Bridge scene:
- Gemini 3 Pro delivered "the most realistic result" with superior water physics simulation and accurate fog layering
- Claude Opus 4.5 produced smooth renders with less environmental detail
- GPT-5.2 failed to load without enabling Thinking mode, then produced acceptable but generic results
For design tasks like creating a Photoshop clone interface, Claude and GPT-5.2 performed comparably, with Claude matching Photoshop's interface more closely. Gemini offered simplified functionality with fewer tools—potentially faster to implement but less feature-complete.
Practical Multimodal Use Cases
Choose Gemini 3 Pro for:
- Video content analysis (surveillance, meeting recordings, educational content)
- Multi-hour audio transcription and analysis
- Processing entire codebases or document collections (leveraging 1M context)
- Visual simulation and 3D understanding tasks
- High-volume multimodal workloads where cost efficiency matters
Choose GPT-5.2 for:
- Structured image analysis requiring detailed reasoning
- Document understanding with complex logical relationships
- Workflows combining text and images with heavy reasoning requirements
Choose Claude Opus 4.5 for:
- UI/UX design tasks requiring polish and precision
- Image-to-code workflows
- Visual analysis requiring detailed written explanations
The multimodal landscape will continue evolving rapidly. Both OpenAI and Anthropic have announced plans to expand their models' native multimodal capabilities, but as of early 2025, Gemini 3 Pro holds a substantial lead in video and audio processing.
API Pricing and Cost Analysis
Understanding true API costs requires looking beyond headline per-token prices. Actual costs depend on prompt complexity, output length, context usage, and whether you can leverage features like caching or batch processing.
Base API Pricing Comparison
| Model Variant | Input (per 1M tokens) | Output (per 1M tokens) | Context Limit |
|---|---|---|---|
| GPT-5.2 Standard | $1.75 | $14.00 | 400K |
| GPT-5.2 Pro | $21.00 | $168.00 | 400K |
| Gemini 3 Pro (<200K) | $2.00 | $12.00 | 200K |
| Gemini 3 Pro (>200K) | $4.00 | $18.00 | 1M |
| Gemini 3 Flash | $0.50 | $3.00 | 1M |
| Claude Opus 4.5 | $5.00 | $25.00 | 200K |
The pricing structure reveals strategic positioning by each provider. OpenAI offers the widest range from budget-friendly GPT-5.2 Standard to premium GPT-5.2 Pro at 12x the base price. Google's tiered pricing based on context length encourages efficient prompt design—stay under 200K tokens and you save 50% on input costs.
Claude Opus 4.5's premium pricing ($5/$25) positions it as the quality-focused option. However, Anthropic has demonstrated that Claude often achieves equivalent results with fewer output tokens. Testing shows Claude uses approximately 65% fewer tokens than competitors to produce comparable quality, partially offsetting the higher per-token cost.
Real-World Cost Scenarios
Scenario 1: 1,000 Daily Coding Queries
Assuming average 2,000 input tokens and 1,500 output tokens per query:
| Model | Daily Input Cost | Daily Output Cost | Monthly Total |
|---|---|---|---|
| GPT-5.2 Standard | $3.50 | $21.00 | $735 |
| Gemini 3 Pro | $4.00 | $18.00 | $660 |
| Claude Opus 4.5 | $10.00 | $37.50 | $1,425 |
| Gemini 3 Flash | $1.00 | $4.50 | $165 |
For high-volume coding assistance, Gemini 3 Flash offers exceptional value at $165/month—over 8x cheaper than Claude Opus 4.5. However, Flash's reduced capability may require more iterations, potentially negating cost savings through increased query volume.
Scenario 2: Complex Document Analysis (100K token documents)
Processing 50 lengthy documents daily with 5K token summaries:
| Model | Document Input Cost | Analysis Output Cost | Monthly Total |
|---|---|---|---|
| GPT-5.2 Standard | $8.75 | $3.50 | $367.50 |
| Gemini 3 Pro | $10.00 | $3.00 | $390 |
| Claude Opus 4.5 | $25.00 | $6.25 | $937.50 |
For document processing, GPT-5.2 and Gemini 3 Pro offer similar economics, while Claude's premium pricing becomes harder to justify unless quality differences are significant. For detailed pricing breakdowns, see our Claude Opus 4.5 pricing guide and Gemini 3 Pro pricing analysis.
Cost Optimization Strategies
Several techniques can dramatically reduce API expenses across all providers:
Prompt Caching reduces costs for repetitive system prompts. If your application sends the same 10K token system prompt with every request, caching can reduce effective input costs by 80-90% for that portion.
Batch Processing offers discounts for non-time-sensitive workloads. OpenAI and Google both provide batch APIs with 50% discounts on standard pricing—ideal for overnight processing of large datasets.
Model Selection within families provides flexibility. Using Gemini 3 Flash ($0.50/$3) for initial processing and escalating to Pro ($2/$12) only for complex queries can reduce average costs by 60-70% with minimal quality impact.
For developers seeking additional cost optimization, third-party API aggregation platforms offer competitive pricing across multiple model providers. Platforms like laozhang.ai provide unified access to GPT, Claude, and Gemini models with pricing matching or beating official rates, plus features like automatic failover between providers. The minimum $5 entry point makes it accessible for individual developers testing multiple models, while the OpenAI-compatible API format enables seamless integration with existing codebases.
Model Variants and Specialized Use Cases
Each provider offers multiple variants optimized for different use cases. Understanding these options helps match model capabilities to specific requirements.
GPT-5.2 Variants
OpenAI released GPT-5.2 in three distinct configurations:
GPT-5.2 Instant optimizes for speed and routine queries. It's designed for high-volume applications where latency matters more than maximum capability—chatbots, quick lookups, and simple text transformations.
GPT-5.2 Thinking enables extended chain-of-thought reasoning for complex structured work. It excels at coding challenges, mathematical proofs, detailed analysis, and multi-step planning. The model explicitly shows its reasoning process, improving transparency and debuggability.
GPT-5.2 Pro represents maximum capability for difficult problems. It achieves the highest scores on abstract reasoning benchmarks but at significant cost and latency. Reserve it for critical decisions where correctness justifies 12x pricing premium.
Gemini 3 Variants
Google's lineup emphasizes the Flash/Pro distinction:
Gemini 3 Flash delivers "Pro-level intelligence at the speed and pricing of Flash." At $0.50/$3 per million tokens, it offers remarkable value for applications that can tolerate slightly reduced capability. The million-token context window remains available, making it excellent for long-document processing at scale.
Gemini 3 Pro provides full capabilities including advanced reasoning, multimodal processing, and maximum output quality. The thinking_level parameter allows dynamic control over reasoning depth—set to "low" for faster responses or "high" for maximum analysis.
Gemini 3 Pro Image (Nano Banana Pro) specializes in 4K image generation with conversational editing capabilities. The model uses "thought signatures"—encrypted representations of internal reasoning—to maintain context across multi-turn image editing sessions. For a detailed comparison with other image models, see our Gemini 3 Pro Image pricing guide.
Claude Opus 4.5 Variants
Anthropic offers simpler configuration through effort parameters rather than separate model variants:
Standard Mode provides fast, high-quality responses for typical queries. Token usage is lower but reasoning depth may be limited for complex problems.
Thinking Mode (enabled via extended thinking parameter) activates explicit chain-of-thought reasoning similar to GPT-5.2 Thinking. This mode achieves the highest benchmark scores but increases both latency and token consumption.
The effort parameter provides granular control: at medium effort levels, Claude Opus 4.5 achieves equivalent results to competitors with 76% fewer tokens, substantially reducing costs for high-volume applications.
Variant Selection Guide
| Use Case | Recommended Model | Rationale |
|---|---|---|
| High-volume chatbot | GPT-5.2 Instant | Optimized for speed and cost |
| Code generation | Claude Opus 4.5 | Highest SWE-bench scores |
| Abstract reasoning | GPT-5.2 Pro | 54.2% ARC-AGI-2 leads field |
| Video analysis | Gemini 3 Pro | Native multimodal architecture |
| Document processing at scale | Gemini 3 Flash | 1M context at lowest cost |
| Critical architecture decisions | GPT-5.2 Pro | Deepest analysis capability |
| Rapid prototyping | GPT-5.2 Standard | Best speed/cost/quality balance |
Developer Integration Guide
All three providers offer OpenAI-compatible APIs, simplifying integration for developers with existing codebases. Here's how to get started with each platform.
GPT-5.2 Integration
hljs pythonfrom openai import OpenAI
client = OpenAI(api_key="sk-your-openai-key")
# Standard query
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Explain quantum computing"}]
)
# With extended reasoning (Thinking mode)
response = client.chat.completions.create(
model="gpt-5.2-thinking",
messages=[{"role": "user", "content": "Solve this complex algorithm"}],
reasoning_effort="high" # Options: low, medium, high
)
Gemini 3 Pro Integration
hljs pythonimport google.generativeai as genai
genai.configure(api_key="your-gemini-api-key")
model = genai.GenerativeModel('gemini-3-pro')
# Standard query
response = model.generate_content("Explain quantum computing")
# With thinking level control
response = model.generate_content(
"Solve this complex algorithm",
generation_config={"thinking_level": "high"} # low, high
)
Claude Opus 4.5 Integration
hljs pythonimport anthropic
client = anthropic.Anthropic(api_key="your-anthropic-key")
# Standard query
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=4096,
messages=[{"role": "user", "content": "Explain quantum computing"}]
)
# With extended thinking
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=8192,
thinking={"type": "enabled", "budget_tokens": 4096},
messages=[{"role": "user", "content": "Solve this complex algorithm"}]
)
Unified Access via API Aggregation
For developers who need flexibility across multiple providers without managing separate API keys and billing accounts, aggregation platforms provide a compelling solution:
hljs pythonfrom openai import OpenAI
# Using laozhang.ai for unified model access
client = OpenAI(
api_key="sk-your-laozhang-key", # Get from laozhang.ai
base_url="https://api.laozhang.ai/v1"
)
# Switch between models by changing the model parameter
response = client.chat.completions.create(
model="gpt-5.2", # Or "claude-opus-4-5", "gemini-3-pro"
messages=[{"role": "user", "content": "Your prompt here"}]
)
This approach offers several advantages: a single API key accesses all major models, pricing often matches or beats official rates, and automatic failover ensures reliability when any single provider experiences issues. For teams comparing models or building applications that route queries to different models based on task type, unified access dramatically simplifies architecture. Detailed pricing information is available in the laozhang.ai documentation.
Multi-Model Workflow Example
Professional developers increasingly combine models to leverage each one's strengths. Here's a practical pattern for a code review workflow:
hljs pythondef intelligent_code_review(code: str) -> dict:
"""
Multi-model code review combining Claude's accuracy
with Gemini's cost efficiency
"""
# Step 1: Quick scan with Gemini Flash for obvious issues
quick_scan = gemini_client.generate(
model="gemini-3-flash",
prompt=f"List obvious bugs in this code:\n{code}"
)
# Step 2: Deep analysis with Claude for security review
security_review = claude_client.messages.create(
model="claude-opus-4-5",
messages=[{
"role": "user",
"content": f"Security audit this code:\n{code}"
}]
)
# Step 3: Architecture suggestions with GPT-5.2 Thinking
architecture = openai_client.chat.completions.create(
model="gpt-5.2-thinking",
messages=[{
"role": "user",
"content": f"Suggest architectural improvements:\n{code}"
}]
)
return {
"quick_issues": quick_scan,
"security": security_review,
"architecture": architecture
}
This pattern uses Gemini Flash's low cost for initial screening, Claude's precision for security-critical analysis, and GPT-5.2's reasoning depth for architectural recommendations—achieving better results than any single model while controlling costs.
Which Model Should You Choose?
After extensive benchmark analysis and real-world testing, clear patterns emerge for different use cases. Here are specific recommendations based on primary use case:
For Software Development Teams
Primary Recommendation: Claude Opus 4.5
Claude's 80.9% score on SWE-bench Verified translates to practical advantages: cleaner code generation, better understanding of existing codebases, and more complete implementations on first attempt. The 65% token efficiency advantage partially offsets premium pricing, and faster completion times (7 minutes vs. 59 minutes for GPT-5.2 Pro on complex tasks) dramatically improve developer productivity.
When to use GPT-5.2 instead: For teams prioritizing code that follows common conventions and is easily understood by junior developers, GPT-5.2 produces more "standard" implementations. Its 400K context window also handles larger codebases than Claude's 200K limit.
When to use Gemini 3 Pro instead: Frontend teams report Gemini produces superior visual quality for UI components. The lowest cost per query makes it attractive for high-volume generation, though code may need hardening for production use.
For Data Science and Research
Primary Recommendation: GPT-5.2 Pro
The 54.2% score on ARC-AGI-2 and 40.3% on FrontierMath demonstrate GPT-5.2's superior abstract reasoning capabilities. For novel problem-solving, mathematical proof development, and research requiring creative logical leaps, no current model matches GPT-5.2 Pro's depth.
Budget alternative: Standard GPT-5.2 captures most of the reasoning capability at 12x lower cost. Reserve Pro for critical breakthroughs where correctness justifies extended processing time and expense.
For Content and Marketing Teams
Primary Recommendation: Claude Opus 4.5
Testing consistently shows Claude produces "the strongest hooks" with direct, punchy writing style. The model excels at long-form content generation with natural flow and maintained coherence across thousands of words.
Alternative consideration: GPT-5.2 offers thoughtful, well-structured framing that may suit more analytical content. Gemini's output tends toward generic phrasing that requires more editorial polish.
For Multimodal Applications
Primary Recommendation: Gemini 3 Pro
No contest here—Gemini's native multimodal architecture, million-token context window, and full video/audio support create capabilities competitors simply cannot match. For any workflow involving video analysis, multi-hour audio processing, or massive document collections, Gemini is the only practical choice among frontier models.
For Startups and Budget-Conscious Teams
Primary Recommendation: Gemini 3 Flash + Selective Upgrades
At $0.50/$3 per million tokens, Gemini 3 Flash enables experimentation and scaling without budget anxiety. Use Flash for 80% of queries, escalate to Pro for complex multimodal tasks, and add Claude Opus 4.5 specifically for production-critical code generation.
Cost comparison: A startup spending $300/month on AI APIs could afford:
- 200M tokens from Gemini 3 Flash, or
- 30M tokens from GPT-5.2, or
- 12M tokens from Claude Opus 4.5
The 16x difference between Flash and Claude means choosing wisely matters significantly at scale.

Future Outlook and Conclusion
The late 2025 model releases established a new competitive equilibrium where no single provider dominates across all dimensions. This specialization appears intentional—each company has optimized for different metrics based on their strategic priorities.
OpenAI prioritizes reasoning and general capability, positioning GPT-5.2 as the "smartest" model for complex analytical tasks. Their three-tier pricing (Instant/Thinking/Pro) enables cost-conscious deployment while preserving access to maximum capability when needed.
Google leverages its infrastructure advantages to offer the largest context windows and most aggressive pricing. Gemini 3 Pro's native multimodal architecture represents a fundamentally different approach than competitors' text-first designs, creating unique capabilities in video and audio processing.
Anthropic focuses on reliability and code quality, accepting premium pricing in exchange for higher first-attempt success rates and lower token consumption. Their positioning as the "safest choice for production" reflects corporate customers' willingness to pay more for reduced risk.
Key Takeaways
-
No universal winner exists. Each model excels in specific domains. Match model selection to your actual use case rather than aggregate benchmark scores.
-
Multi-model workflows outperform single-model approaches. Using Gemini for initial processing, Claude for code generation, and GPT-5.2 for complex reasoning produces better results than committing to any single provider.
-
Cost differences are dramatic. A 16x pricing spread between Gemini 3 Flash and Claude Opus 4.5 means model selection significantly impacts total cost of ownership at scale.
-
Context window matters. Gemini's million-token window enables entirely new workflows impossible with competitors' 200-400K limits.
-
Benchmark scores don't tell the full story. Real-world testing reveals differences in code quality, completion speed, and production readiness that benchmarks miss.
The AI landscape will continue evolving rapidly. Both OpenAI and Anthropic have announced expanded multimodal capabilities for 2026, while Google continues improving Gemini's reasoning scores. Today's optimal choice may shift as capabilities converge or new differentiators emerge.
For developers making decisions today, the guidance is clear: understand your specific requirements, test multiple models on representative tasks from your actual workload, and design architectures that allow model switching as the competitive landscape evolves. The winners in AI-powered development won't be those who pick the "best" model—they'll be those who most effectively leverage the unique strengths of each.
Frequently Asked Questions
Which model is best for coding: GPT-5.2, Claude Opus 4.5, or Gemini 3 Pro?
Claude Opus 4.5 leads coding benchmarks with 80.9% on SWE-bench Verified, making it the safest choice for production code generation. However, GPT-5.2 produces code following more common conventions (easier for teams to maintain), while Gemini 3 Pro excels at frontend/UI work with the lowest costs. For most development teams, Claude Opus 4.5 offers the best balance of quality and reliability.
How do the API costs compare for high-volume usage?
At 1 million tokens, GPT-5.2 costs $15.75 (input + output), Gemini 3 Pro costs $14.00, and Claude Opus 4.5 costs $30.00. However, Claude's 65% token efficiency means actual costs may be lower than headline rates suggest. For budget-conscious teams, Gemini 3 Flash at $3.50 per million tokens offers exceptional value with Pro-level intelligence.
What's the largest context window available?
Gemini 3 Pro offers 1 million input tokens—5x larger than GPT-5.2's 400K and 5x larger than Claude Opus 4.5's 200K. This enables processing entire codebases, feature-length videos, or extensive document collections in single prompts. For workflows requiring massive context, Gemini has no direct competition.
Can I use multiple models together?
Yes, and this approach often produces superior results. A common pattern uses Gemini 3 Flash for initial processing and filtering, Claude Opus 4.5 for code generation requiring high accuracy, and GPT-5.2 Thinking for complex reasoning tasks. API aggregation platforms simplify multi-model workflows by providing unified access through a single integration.
Which model has the best reasoning capabilities?
GPT-5.2 Pro leads abstract reasoning with 54.2% on ARC-AGI-2—significantly ahead of Claude Opus 4.5 at 37.6% and Gemini 3 Pro at 31.1%. For mathematical proofs, novel problem-solving, and tasks requiring creative logical leaps, GPT-5.2 variants offer unmatched capabilities. Note that GPT-5.2 Pro's premium pricing ($21/$168 per million tokens) makes it suitable only for critical reasoning tasks.
Are there regional restrictions for these APIs?
All three providers have varying availability by region. Developers in restricted regions can access these models through API aggregation services that provide stable connectivity and unified billing. Services like laozhang.ai offer OpenAI-compatible endpoints with multi-node redundancy for improved reliability.
Which model should I choose for a new project?
Start with Gemini 3 Flash for prototyping due to its low cost and large context window. As requirements clarify, add Claude Opus 4.5 for code generation requiring production reliability, and GPT-5.2 Thinking for complex analytical features. This staged approach controls costs during development while ensuring access to premium capabilities when needed.