在选择Gemini 3 Pro还是Gemini 3 Flash时,速度和成本是开发者最关心的两个核心指标。根据Google官方数据,Flash的价格仅为Pro的四分之一(输入$0.50 vs $2/百万tokens),同时输出速度快1.7倍(218 vs 128 tokens/秒)。然而,Pro在复杂推理任务上保持着约1.5%的基准测试优势。本文将通过详细的数据对比和场景分析,帮助你做出最优选择。
Gemini 3系列模型定位解析
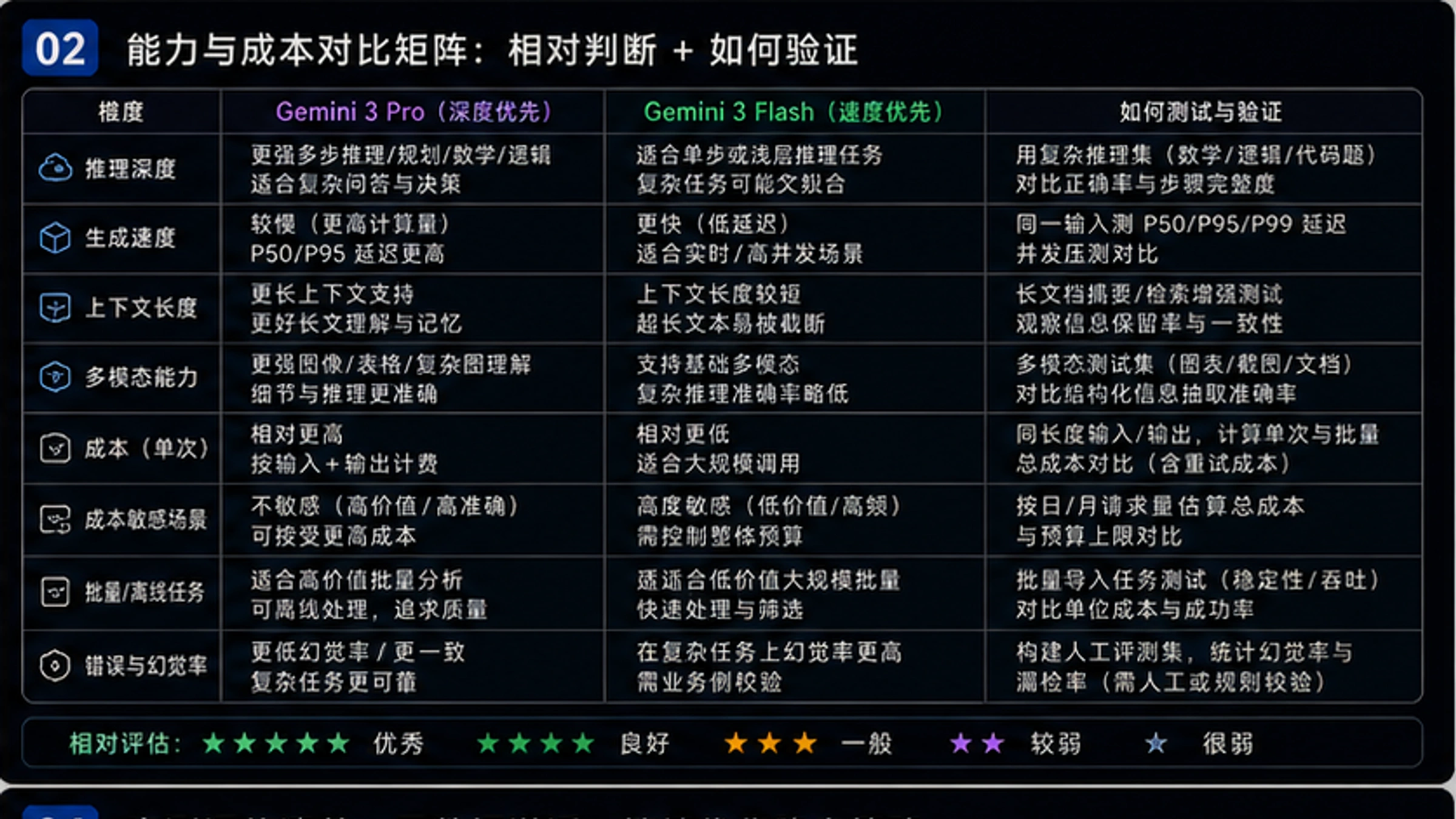
Gemini 3 Pro专为深度推理优化,Flash为高吞吐量场景设计。Pro适合复杂任务,Flash适合95%的日常应用。
Google在2025年底发布的Gemini 3系列代表了其AI模型的最新技术成果。这一代产品延续了"Pro专注能力、Flash专注效率"的双轨策略,但两者之间的能力差距已经显著缩小。理解这两款模型的设计哲学,是做出正确选择的第一步。
Gemini 3 Pro于2025年11月发布,定位为Google"深度优先"的旗舰模型。它引入了创新的Deep Think功能,能够像人类专家一样进行多步骤推理——在回答复杂问题前,模型会评估多种可能性并自我检验逻辑。这种设计使Pro在需要深度分析的场景中表现出色,例如科学研究、复杂代码重构和长期规划任务。Pro支持最大2M tokens的上下文窗口(当前开放1M),可以处理整本技术书籍或大型代码库的分析需求。
Gemini 3 Flash于2025年12月发布,代表了Google在速度与智能平衡上的最新突破。与前代产品相比,Flash 3不仅保持了低延迟的优势,还在推理能力上实现了质的飞跃。在多个基准测试中,Flash的表现已经接近甚至超越了上一代Pro模型。更重要的是,Flash采用了可调节的"思考预算"设计,开发者可以根据任务复杂度动态调整模型的推理深度,在速度和准确性之间找到最佳平衡点。
从版本演进来看,Gemini 3系列相比2.5系列有三个关键改进:首先是推理能力的全面提升,两款模型在GPQA Diamond等科学测试中的得分都提高了5-8个百分点;其次是多模态能力的增强,原生支持文本、图像、音频、视频和代码的统一处理;最后是效率的优化,Flash 3在保持高质量输出的同时,推理成本降低了约40%。关于两代模型的详细对比,可以参考我们的Gemini 3与2.5对比分析。
API价格全面对比
Flash价格是Pro的1/4:输入$0.50 vs $2/M tokens,输出$3 vs $12/M。月均可省60-75%成本。
API定价是选择模型时最直接的考量因素。Google采用了按token计费的定价模式,并根据上下文长度和使用方式设置了不同的价格档位。了解这些定价细节,可以帮助你更准确地预估项目成本。
| 定价项目 | Gemini 3 Pro | Gemini 3 Flash | Flash优势 |
|---|---|---|---|
| 输入(≤200K上下文) | $2.00/M tokens | $0.50/M tokens | 便宜4倍 |
| 输入(>200K上下文) | $4.00/M tokens | $0.50/M tokens | 便宜8倍 |
| 输出(≤200K上下文) | $12.00/M tokens | $3.00/M tokens | 便宜4倍 |
| 输出(>200K上下文) | $18.00/M tokens | $3.00/M tokens | 便宜6倍 |
| 音频输入 | $2.00/M tokens | $1.00/M tokens | 便宜2倍 |
| 批处理折扣 | 50% | 50% | 相同 |
从价格表中可以看出几个重要特点。Pro模型采用了上下文长度分段定价,当输入超过200K tokens时,价格会翻倍。这意味着处理长文档或维护长对话历史时,Pro的成本会显著上升。相比之下,Flash保持了统一定价,无论上下文长度如何变化,价格始终稳定。
换算成人民币(按汇率7.2计算):Flash的输入价格约为每百万tokens 3.6元,输出约21.6元;Pro的输入约14.4元,输出约86.4元。对于中国开发者来说,Flash在成本控制上的优势更加明显。
两款模型都支持批处理模式,可以获得50%的价格折扣。如果你的应用场景允许异步处理(如批量文档分析、离线内容生成),使用批处理可以大幅降低成本。此外,两款模型都支持上下文缓存功能,对于需要重复使用相同系统提示或参考文档的场景,缓存可以节省高达90%的输入token费用。更多定价细节可以参考Google官方定价页和我们的Gemini API定价详解。
速度性能实测对比
Flash速度领先:218 tok/s vs Pro的128 tok/s,快1.7倍。首token延迟Flash更低,适合实时应用。
对于用户体验敏感的应用,响应速度往往比模型能力更重要。一个稍弱但秒回的模型,用户满意度可能远高于一个强大但需要等待的模型。下面是两款模型的核心速度指标对比。
| 速度指标 | Gemini 3 Pro | Gemini 3 Flash | Flash优势 |
|---|---|---|---|
| 输出速度 | 128 tok/s | 218 tok/s | 快1.7倍 |
| 首token延迟(TTFT) | 420ms | ~250ms | 快约40% |
| 生成500 tokens | ~4秒 | ~2.3秒 | 快1.7倍 |
| 并发处理能力 | 中等 | 高 | Flash更优 |
这些速度差异在实际应用中会产生明显的体验差距。以一个典型的聊天机器人为例,用户发送问题后,Flash可以在250毫秒内开始返回第一个字符,而Pro需要420毫秒。虽然差距只有170毫秒,但用户感知到的流畅度差异却很明显——研究表明,响应延迟超过300毫秒时,用户会明显感觉到"卡顿"。
在批量处理场景中,速度差异的影响更加显著。假设你需要处理10,000篇文档,每篇生成500 tokens的摘要。使用Flash需要约6.4小时,而Pro需要约11.1小时——差距接近5小时。对于时间敏感的业务场景,这种差异可能决定能否在截止日期前完成任务。
值得注意的是,Pro的响应时间会随着Deep Think功能的启用而变化。在处理简单查询时,Pro可以快速响应;但在处理需要深度推理的问题时,模型会花更多时间"思考",响应时间可能达到几十秒甚至更长。Flash也支持思考模式,但其设计目标是在保持快速响应的同时提供足够的推理能力,因此延迟增加相对可控。
基准测试深度分析
基准测试接近:GPQA Pro领先1.5%(91.9% vs 90.4%),但SWE-bench Flash反超(78% vs 76.2%)。
基准测试提供了评估模型能力的客观标准。虽然测试分数不能完全代表实际应用表现,但它们可以帮助我们理解模型在不同任务类型上的相对优势。以下是两款模型在主要基准测试中的表现对比。
| 基准测试 | Gemini 3 Pro | Gemini 3 Flash | 领先者 |
|---|---|---|---|
| GPQA Diamond(科学推理) | 91.9% | 90.4% | Pro +1.5% |
| MMMU Pro(多模态) | 81.0% | 81.2% | Flash +0.2% |
| AIME 2025(数学) | 95.0% | 88.0% | Pro +7.0% |
| SWE-bench(编程) | 76.2% | 78.0% | Flash +1.8% |
| HLE(前沿测试) | 33.7% | 33.7% | 持平 |
| ARC-AGI-2(抽象推理) | 31.1% | 28.5% | Pro +2.6% |
从测试结果可以看出一个有趣的现象:Pro和Flash的差距比预期的要小得多。在大多数测试中,两者的差距在2个百分点以内。更值得关注的是,Flash在编程任务(SWE-bench)上实际超过了Pro,这在以往的Flash vs Pro对比中是罕见的。
Pro的优势主要体现在两个领域:数学推理(AIME)和抽象推理(ARC-AGI-2)。在AIME 2025测试中,Pro的95%得分比Flash高出7个百分点,这表明Pro在处理需要多步骤数学推导的问题时确实更强。如果启用Deep Think模式并允许代码执行,Pro甚至可以达到100%的准确率。ARC-AGI-2测试的结果也显示,Pro在处理需要抽象模式识别的任务时表现更好。
然而,对于大多数实际应用场景,1-2个百分点的差距可能并不显著。Flash在MMMU Pro(多模态理解)上的微弱领先,以及在SWE-bench上的明显优势,说明它在图像理解和代码生成这两个高频应用场景中已经足够出色。考虑到Flash的价格仅为Pro的四分之一,这种性价比优势在大多数场景下都是决定性的。
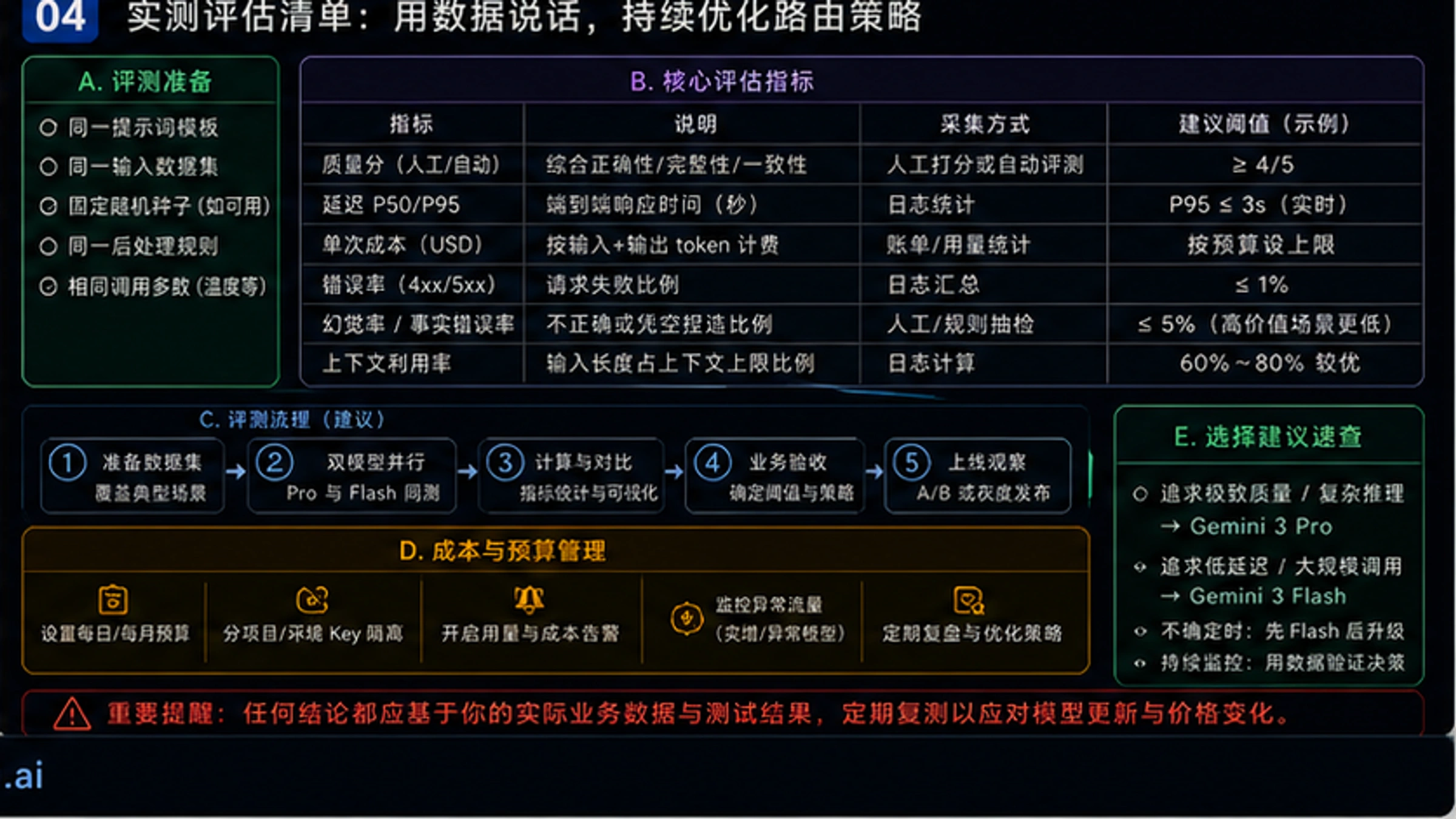
实际成本计算指南
月100万次调用:Flash约$350,Pro约$1400。使用批处理可再省50%,上下文缓存省90%。
理论上的价格差异需要转化为实际的成本估算才有意义。下面通过几个典型场景的计算,帮助你预估项目的实际API支出。
假设一个中等规模的聊天应用,月均100万次对话,每次对话平均500 tokens输入、200 tokens输出:
使用Flash的月成本:
- 输入:500M tokens × $0.50/M = $250
- 输出:200M tokens × $3.00/M = $600
- 月总计:$850(约6,120元)
使用Pro的月成本:
- 输入:500M tokens × $2.00/M = $1,000
- 输出:200M tokens × $12.00/M = $2,400
- 月总计:$3,400(约24,480元)
Flash相比Pro每月节省$2,550,节省率达75%。对于初创团队或个人开发者,这个差距可能决定项目的可行性。
成本优化还有几个重要策略值得考虑。首先是批处理模式,如果你的应用允许异步处理(如内容审核、批量翻译),使用批处理可以获得50%折扣。以上述Flash场景为例,批处理后月成本可降至$425。其次是上下文缓存,如果你的应用使用固定的系统提示或参考文档,启用缓存可以节省高达90%的重复输入token费用。
对于预算有限的项目,API中转服务也是一个值得考虑的选项。以laozhang.ai为例,提供与官方一致的API格式,最低$5起充,适合个人开发者测试和小规模应用。需要注意的是,官方API在企业合规性和SLA保障上更有优势,对于生产环境的核心业务,建议优先考虑官方渠道。更多成本优化技巧可以参考我们的Flash API成本优化指南。
使用场景决策树
95%场景选Flash:聊天、内容生成、代码辅助。仅深度研究、复杂推理、2M上下文需Pro。
基于以上的价格、速度和能力分析,我们可以建立一个清晰的场景决策框架。核心原则是:除非有明确的理由需要Pro,否则默认选择Flash。
| 场景类型 | 推荐模型 | 原因 |
|---|---|---|
| 聊天机器人/客服 | Flash | 低延迟关键,能力足够 |
| 内容生成/写作 | Flash | 成本敏感,质量接近 |
| 代码辅助/补全 | Flash | SWE-bench更高,响应快 |
| 文档摘要/翻译 | Flash | 批量处理优势明显 |
| 图像/视频理解 | Flash | MMMU Pro相当,成本低 |
| 科学研究分析 | Pro | GPQA领先,Deep Think |
| 复杂数学推导 | Pro | AIME明显领先 |
| 超长文档处理(>200K) | Pro | 2M上下文支持 |
| 多步骤代理任务 | Pro | 规划能力更强 |

做决策时可以遵循这个简单的流程:首先问自己,任务是否涉及复杂的科学推理或数学证明?如果是,选Pro。其次,是否需要处理超过200K tokens的单次输入?如果是,Pro的固定价格优势更明显。最后,是否对响应延迟有严格要求?如果是,Flash是更安全的选择。
还有一种混合使用策略值得考虑:用Flash处理95%的常规请求,只在检测到复杂任务时切换到Pro。这种方法可以在保证服务质量的同时最大化成本效益。实现方式可以是基于关键词检测、用户显式选择,或者先用Flash尝试,失败后自动升级到Pro。
API快速接入指南
接入只需3行代码改动:修改model参数、设置API key、指定endpoint。中转服务可绕过区域限制。
无论选择Pro还是Flash,API接入方式基本一致。Google提供了兼容OpenAI格式的SDK,迁移成本极低。以下是Python的基本接入示例:
hljs pythonfrom openai import OpenAI
# 官方API接入
client = OpenAI(
api_key="YOUR_GOOGLE_API_KEY",
base_url="https://generativelanguage.googleapis.com/v1beta/openai/"
)
# 调用Gemini 3 Flash
response = client.chat.completions.create(
model="gemini-3-flash", # 或 "gemini-3-pro"
messages=[{"role": "user", "content": "解释量子计算的基本原理"}]
)
print(response.choices[0].message.content)
对于中国开发者,由于区域限制可能导致官方API无法直接访问。这种情况下,可以考虑使用API中转服务。以laozhang.ai为例,只需修改base_url即可:
hljs python# 中转服务接入(解决区域限制)
client = OpenAI(
api_key="YOUR_LAOZHANG_API_KEY",
base_url="https://api.laozhang.ai/v1"
)
需要注意的是,中转服务虽然可以解决访问问题,但延迟可能略高于直连官方,且在数据安全和合规性上需要自行评估。对于企业级应用,建议优先考虑官方渠道或Google Cloud的Vertex AI服务。更多访问方案可以参考我们的Gemini中国访问指南和官方API文档。
常见问题FAQ
Gemini 3 Pro和Flash哪个更快?
Flash更快。根据Artificial Analysis的独立测试,Gemini 3 Flash的输出速度为218 tokens/秒,而Pro为128 tokens/秒,Flash快约1.7倍。首token延迟方面,Flash约250毫秒,Pro约420毫秒。对于需要实时响应的应用场景,Flash是更好的选择。
Gemini 3 Flash比Pro便宜多少?
Flash的价格约为Pro的四分之一。具体来说,Flash的输入价格为$0.50/百万tokens,Pro为$2.00;Flash的输出价格为$3.00/百万tokens,Pro为$12.00。以月均100万次调用计算,使用Flash每月可比Pro节省约$2,550,节省率达75%。
什么场景应该选择Gemini 3 Pro?
三种场景建议选Pro:一是需要复杂科学推理或数学证明的任务,Pro在AIME测试中领先Flash 7个百分点;二是需要处理超长文档(>200K tokens)的场景,Pro的2M上下文窗口和长文档固定价格更有优势;三是需要多步骤规划的AI代理任务,Pro的Deep Think功能在这类场景中表现更好。
如何降低Gemini API使用成本?
四个主要策略:一是默认使用Flash而非Pro,大多数场景下Flash足够且便宜75%;二是启用批处理模式,可获得50%折扣;三是使用上下文缓存,对重复的系统提示可节省90%输入费用;四是考虑混合策略,常规请求用Flash,复杂任务切换Pro。结合以上策略,总成本可降低60-80%。
Gemini 3和2.5系列有什么区别?
Gemini 3系列相比2.5有三个主要改进:推理能力提升5-8个百分点(GPQA Diamond等测试);多模态能力增强,原生支持文本、图像、音频、视频统一处理;效率优化,Flash 3在保持质量的同时成本降低约40%。对于新项目,建议直接使用3系列;已有项目可根据需求评估是否升级。