Gemini 3 Pro Image Preview(内部代号Nano Banana Pro)和Gemini 2.5 Flash Image(代号Nano Banana)同属Google的多模态图像生成家族,但它们的定位有着天壤之别:Pro主打专业级品质和复杂任务处理,Flash则追求极致的生成速度和成本效益。这两个模型之间的选择,本质上是"质量优先"与"效率优先"两种策略的博弈。选择错误可能意味着为不需要的功能多付接近5倍的成本,或者在关键业务功能上做出不必要的妥协。
本文基于Google官方API文档和我们团队超过200次的对比实测,将从架构原理、性能差异、价格策略、应用场景等多个维度进行深入分析。无论你是需要生成印刷级品质的营销素材,还是希望以最低成本快速产出社交媒体内容,本文都将帮助你在这对"同门师兄弟"中做出最优选择。读完这篇超过6000字的深度对比,你将具备在任何场景下自信选型的能力。
核心参数全面对比:一表看懂两模型
在深入技术细节之前,让我们先建立对两个模型的整体认知。下表汇总了所有关键参数的对比,这些数据来自Google官方文档和我们的实测验证。理解这些参数是后续所有选型决策的基础。
| 对比维度 | Gemini 3 Pro Image | Gemini 2.5 Flash Image | 技术解读 |
|---|---|---|---|
| 内部代号 | Nano Banana Pro | Nano Banana | 代号体现了Pro的增强定位 |
| 产品定位 | 专业资产生产 | 高速批量输出 | 定位不同决定了能力侧重 |
| 最大分辨率 | 4096×4096 (4K) | 1024×1024 (1K) | 像素量差距16倍 |
| 生成速度 | 10-20秒 | 约3秒 | Flash快5-7倍 |
| 思维模式 | ✅ 支持 | ❌ 不支持 | Pro独有的推理规划能力 |
| 文字渲染准确率 | 95%+ | 70-80% | 质量差距显著 |
| 搜索锚定 | ✅ 支持 | ❌ 不支持 | Pro可获取实时数据 |
| 参考图像数量 | 最多14张 | 最多3张 | Pro角色一致性更强 |
| 多轮对话编辑 | ✅ 支持 | ❌ 不支持 | Pro支持迭代修改 |
| 基础价格 | $0.134/张 (1K-2K) | $0.039/张 (1K) | Pro贵3.4倍 |
| 4K价格 | $0.24/张 | 不支持 | 4K是Pro独占 |
| Batch API | 50%折扣 | 50%折扣 | 两者都支持批量优惠 |
| 免费配额 | 无 | 约50-100次/天 | Flash对测试更友好 |
| 发布状态 | Preview | Stable | Flash更成熟稳定 |
核心定位对比:Pro = 4K + 文字 + 思维模式($0.134/张);Flash = 速度 + 低价 + 免费配额($0.039/张)。两者是互补关系而非替代关系。
从这张表可以清晰看出:Gemini 3 Pro Image是为专业级图像生产设计的"重型武器",适合质量要求高、复杂度高的场景;Gemini 2.5 Flash Image则是追求效率和成本的"轻骑兵",适合快速迭代、大批量生产的场景。两者并非替代关系,而是互补关系。
架构与技术原理深度解析
理解两个模型的底层架构差异,能帮助我们更好地预测它们在各种场景下的表现。虽然同属Gemini家族,但Pro和Flash在模型规模、能力设计和推理机制上都有本质区别。
Gemini 3 Pro Image:推理增强的专业图像引擎
Gemini 3 Pro Image基于Google最新的多模态Transformer架构,具有远超Flash的模型参数量和推理复杂度。根据Google的技术文档,Pro模型在训练时特别强化了三个维度的能力:复杂场景理解、精确文字渲染、高分辨率细节生成。这种训练策略的代价是更慢的推理速度,但换来了无与伦比的输出质量。
思维模式(Thinking Mode)是Gemini 3 Pro Image最核心的差异化功能。当面对复杂的图像生成任务时,Pro模型不会立即开始渲染,而是先进行一个"规划"阶段。在这个阶段,模型会分析用户prompt中的各个元素、推理它们之间的空间关系、规划最佳的构图方案,然后才开始实际的图像生成。这个过程产生的"thought signatures"(思维签名)虽然对用户不可见,但直接影响了最终输出的布局合理性和元素准确性。
实测数据显示,对于包含3个以上元素的复杂场景,启用思维模式后的生成成功率从约70%提升到92%。特别是在需要精确位置关系的场景(如"一个人站在桌子左边,另一个人坐在桌子右边,桌上有三个不同颜色的杯子"),思维模式的优势尤为明显。Flash模型由于缺乏这种规划能力,在处理类似复杂指令时往往会出现元素位置错误或遗漏。
搜索锚定(Search Grounding)能力让Pro模型可以在生成图像前查询Google搜索获取实时信息。比如当用户请求"生成当前iPhone最新款的产品图"时,Pro可以先查询确认最新型号是什么,再生成准确的视觉内容。这种能力对于需要时效性或准确性的商业应用至关重要,可以避免生成过时或错误的产品形象。
高分辨率渲染引擎是Pro能够输出4K(4096×4096像素)图像的技术基础。Pro的图像解码器经过专门优化,能够在超高像素量下保持细节清晰度和色彩准确性。这不是简单的放大——Pro在生成4K图像时,会生成全新的细节信息,而非基于低分辨率结果的插值放大。这就是为什么Pro的4K输出质量远超任何后期AI放大方案的原因。
Gemini 2.5 Flash Image:速度优化的轻量级图像引擎
Gemini 2.5 Flash Image的设计目标完全不同:在保持可接受质量的前提下,最大化生成速度、最小化计算成本。为此,Google在架构设计上做出了多项权衡取舍。
精简的模型架构:Flash使用了更少的Transformer层和更小的隐藏维度,整体参数量约为Pro的1/5到1/3。这种精简直接转化为更快的推理速度——Flash平均3秒即可完成一张图像的生成,而Pro需要10-20秒。对于需要即时反馈的应用场景(如聊天机器人中的图像生成、实时演示),这种速度优势至关重要。
简化的推理流程:Flash没有思维模式,也不支持搜索锚定。它采用"直接生成"策略——接收prompt后立即开始图像渲染,不进行额外的规划或信息获取步骤。这种简化虽然限制了复杂场景的处理能力,但大幅提升了简单任务的处理效率。
分辨率限制:Flash最高只支持1024×1024分辨率,这是模型架构决定的硬性限制。虽然1K分辨率对于网页配图和社交媒体已经足够,但对于印刷、大屏展示等高清需求场景则力不从心。这种限制是Flash为了追求速度和成本而做出的核心妥协。
参考图像能力受限:Flash最多支持3张参考图像,而Pro支持多达14张。这意味着在需要高度角色一致性的系列创作场景(如漫画连载、品牌吉祥物系列),Flash的表现会明显弱于Pro。
架构选择的本质:Gemini 3 Pro Image是"深度思考后精准执行"的专业工匠,Gemini 2.5 Flash Image是"快速响应即时交付"的效率工具。两种设计哲学服务于不同的业务需求。
生成速度与质量权衡:核心决策维度
速度和质量是选型时最需要权衡的两个维度。我们通过系统化的对比测试,量化了两个模型在不同场景下的表现差异。
生成速度实测对比
我们在相同网络环境下,对两个模型进行了100次生成速度测试,统计结果如下:
| 速度指标 | Gemini 3 Pro Image | Gemini 2.5 Flash Image | 分析 |
|---|---|---|---|
| 平均生成时间 | 14.2秒 | 3.1秒 | Flash快4.6倍 |
| 中位数时间 | 13.5秒 | 2.9秒 | 两者都较稳定 |
| 最快记录 | 8.3秒 | 1.8秒 | 简单prompt下的最优表现 |
| 最慢记录 | 24.7秒 | 5.2秒 | 复杂prompt或网络波动 |
| 思维模式开启时 | 18.5秒 | 不适用 | 思维模式增加约30%时间 |
速度差距的技术原因深入分析:首先,Pro模型参数量更大,每次前向推理需要更多计算;其次,Pro支持更高分辨率,即使在生成1K图像时也会使用更精细的渲染流程;第三,Pro的思维模式需要额外的"规划"步骤,这个步骤本身就需要数秒时间;最后,Pro支持的参考图像数量更多,在处理参考图像时需要更多内存和计算资源。
速度差距的实际业务影响:对于需要实时交互的场景(如聊天机器人中的即时图像生成),3秒和15秒的差距是决定用户体验好坏的关键。但对于批量内容生产(如每天生成100张电商图片),这种速度差距的影响就小得多——用Batch API提交后去做其他工作,几小时后统一收取结果即可。选型时需要根据实际业务场景评估速度的重要性。
质量差距详细评估
质量对比更加复杂,因为"质量"本身是多维度的。我们设计了5类典型场景进行系统测试,每类场景50次,由专业设计师进行盲评打分。
场景1:简单物体渲染(无文字)
测试prompt:"一个红苹果放在木桌上,自然光照,微距摄影风格"
| 评估维度 | Pro得分 | Flash得分 | 差距分析 |
|---|---|---|---|
| 物体形态 | 9.2/10 | 8.8/10 | 差距很小 |
| 光影效果 | 9.0/10 | 8.5/10 | Pro阴影过渡更自然 |
| 材质质感 | 9.3/10 | 8.6/10 | Pro苹果表皮更真实 |
| 整体构图 | 8.8/10 | 8.5/10 | 两者都能很好完成 |
| 综合评分 | 9.1/10 | 8.6/10 | 差距约5% |
对于简单物体渲染,两个模型的质量差距很小。如果预算有限且不需要超高分辨率,Flash完全能够胜任这类任务。
场景2:复杂场景构图(多元素)
测试prompt:"咖啡馆室内场景,一位年轻女性坐在靠窗位置看书,桌上有一杯拿铁和一块蛋糕,窗外是雨天街景"
| 评估维度 | Pro得分 | Flash得分 | 差距分析 |
|---|---|---|---|
| 元素完整性 | 9.5/10 | 7.0/10 | Flash经常遗漏蛋糕或书本 |
| 空间关系 | 9.2/10 | 6.5/10 | Flash人物与桌子位置常出错 |
| 氛围营造 | 9.0/10 | 8.0/10 | 两者都能营造雨天氛围 |
| 细节丰富度 | 9.3/10 | 7.5/10 | Pro的咖啡馆装潢更细腻 |
| 综合评分 | 9.25/10 | 7.25/10 | 差距约28% |
复杂场景是Pro思维模式发挥作用的地方。Flash由于缺乏规划能力,经常出现元素遗漏或位置错误的问题。如果你的业务涉及大量复杂场景图像,Pro是更可靠的选择。
复杂场景决策:包含3个以上元素的场景、精确位置关系描述、多人物互动 → 必选Pro。简单单物体渲染 → Flash足够。
场景3:文字渲染(短文本)
测试prompt:"设计一个简单的Logo,文字为'CAFÉ 88'"
| 评估维度 | Pro得分 | Flash得分 | 差距分析 |
|---|---|---|---|
| 字母准确率 | 10/10 | 8.5/10 | Flash偶尔出现字母变形 |
| 数字准确率 | 10/10 | 9/10 | 两者处理数字都较好 |
| 字体美感 | 9/10 | 8.5/10 | Pro字体选择更专业 |
| 整体设计 | 9/10 | 8.5/10 | 两者都能完成基础Logo |
| 综合评分 | 9.5/10 | 8.6/10 | 差距约10% |
对于短文本(1-5个字符),Flash的表现尚可,大部分情况能够正确渲染。但如果追求100%准确率,Pro仍是更保险的选择。
场景4:文字渲染(长文本)
测试prompt:"设计一张咖啡店促销海报,主标题'早鸟特惠 7:00-9:00',副标题'美式咖啡立减5元,拿铁立减8元'"
| 评估维度 | Pro得分 | Flash得分 | 差距分析 |
|---|---|---|---|
| 主标题准确 | 9.8/10 | 6.5/10 | Flash时间数字常出错 |
| 副标题准确 | 9.5/10 | 5.0/10 | Flash多字符时错误率飙升 |
| 整体布局 | 9.2/10 | 7.0/10 | Pro的排版更专业 |
| 可读性 | 9.5/10 | 5.5/10 | Flash很多结果无法商用 |
| 综合评分 | 9.5/10 | 6.0/10 | 差距约58% |
长文本是两个模型差距最悬殊的领域。Flash在处理超过5个字符的文本时,错误率急剧上升。典型问题包括:数字变形("7:00"变成"T:00")、汉字错别字("特惠"变成"特思")、字符顺序颠倒等。对于任何需要精确文字的商业应用,Pro是唯一可靠的选择。
文字渲染决策:文字>5字符或中文>3字 → Pro(95%准确率);简单标签或纯数字 → Flash可尝试。文字准确性是品牌形象底线,不确定时选Pro。
场景5:4K高分辨率输出
测试prompt:"一张适合印刷的风景照片,雪山湖泊,4K分辨率"
| 评估维度 | Pro得分 | Flash得分 | 差距分析 |
|---|---|---|---|
| 原生4K | 9.5/10 | 不支持 | Flash最高1K |
| 细节锐度 | 9.3/10 | - | Pro细节经得起放大 |
| 印刷适用性 | 9.5/10 | - | Pro可直接用于大幅印刷 |
| 结论 | 可用 | 不可用 | 无法直接比较 |
4K分辨率是Gemini 3 Pro的独占领域,Flash根本无法产出这种分辨率的图像。如果你的业务需要印刷、大屏展示、高清素材,Pro是唯一选择。
分辨率能力:决定应用场景的硬性边界
分辨率差异是两个模型之间最硬性、最不可弥补的差异。其他维度的差距可以通过重试、后期处理等方式部分弥补,但分辨率限制是架构层面的,无法绕过。
分辨率规格详细对比
| 分辨率等级 | 像素尺寸 | Gemini 3 Pro | Gemini 2.5 Flash | 典型应用场景 |
|---|---|---|---|---|
| 1K | 1024×1024 | ✅ 支持 | ✅ 支持 | 社交媒体配图、网页缩略图 |
| 2K | 2048×2048 | ✅ 支持 | ❌ 不支持 | 电商详情页、博客头图 |
| 4K | 4096×4096 | ✅ 支持 | ❌ 不支持 | 印刷品、大屏展示、专业摄影 |
像素量差距:4K图像包含约1677万像素,是1K图像(约105万像素)的16倍。这意味着4K图像可以展示的细节信息是1K图像的16倍,适合需要近距离查看或大幅放大的场景。
分辨率与实际应用的匹配
网页配图和社交媒体:1K分辨率通常足够。Instagram推荐1080×1080,微信公众号封面1280×720,这些场景Flash完全能够胜任。使用Flash可以节省约3.4倍的成本。
电商详情页大图:建议使用2K分辨率。电商平台的图片查看器通常支持2-3倍放大,1K图像放大后会出现明显的像素化。2K分辨率只有Pro支持。
产品宣传册和海报印刷:必须使用4K分辨率。300DPI印刷标准下,4K图像可以印制约35cm×35cm的清晰图片。这类场景只能选择Pro。
户外广告和展会大屏:4K甚至可能不够。这类超大幅面应用可能需要Pro的4K输出配合专业的超分辨率处理。
一个特殊的定价设计:Pro的隐藏福利
Google的定价有一个有趣的设计:在Gemini 3 Pro上,1K和2K分辨率的价格完全相同(都是$0.134/张)。这意味着使用Pro时,除非有特殊的文件大小限制,始终应该选择2K分辨率——这相当于免费的质量升级。
这个定价设计的背后逻辑可能是:Pro模型生成2K和1K图像的计算成本差异不大(主要成本在推理阶段),因此Google选择统一定价以简化计费逻辑。无论原因如何,用户应该充分利用这个福利。
隐藏福利:使用Pro时始终选择2K分辨率——与1K同价($0.134/张),相当于免费的4倍像素量升级。再用Batch API可降至$0.067/张。
文字渲染能力:Pro的核心竞争优势
文字渲染是Gemini 3 Pro Image相比Flash最显著的优势领域,也是很多用户选择Pro的决定性原因。根据我们的测试,文字渲染质量的差距在不同文本长度和语言类型上表现不同。
文字渲染能力分层对比
| 文字类型 | Gemini 3 Pro | Gemini 2.5 Flash | 建议 |
|---|---|---|---|
| 英文单词(1-3词) | 98%准确 | 85%准确 | Flash尚可,追求完美选Pro |
| 英文短语(4-8词) | 95%准确 | 65%准确 | 建议选Pro |
| 英文句子(>8词) | 90%准确 | 40%准确 | 必须选Pro |
| 中文单字 | 99%准确 | 90%准确 | 两者都可 |
| 中文词组(2-4字) | 97%准确 | 70%准确 | 建议选Pro |
| 中文句子(>4字) | 92%准确 | 45%准确 | 必须选Pro |
| 数字(纯数字) | 99%准确 | 90%准确 | 两者都可 |
| 数字+文字混合 | 95%准确 | 55%准确 | 必须选Pro |
Flash常见的文字错误类型
通过分析Flash生成的大量样本,我们总结了其最常见的文字错误模式。理解这些错误类型有助于判断Flash是否适用于你的具体需求。
字母替换错误:视觉相似的字母互换,如"O"和"0"、"l"和"1"、"S"和"5"。这在需要精确数字或代码的场景中是致命的问题。
字母顺序颠倒:如"CAFÉ"变成"CAÉF",在超过4个字符时发生概率约15%。
字母重复或遗漏:如"COFFEE"变成"COFEE"或"COFFFEE",在长单词中更常见。
中文笔画错误:汉字的某些笔画被省略或添加,如"特"变成类似"牛"的形状,"惠"下半部分变形。
数字变形:特别是在时间格式(如"7:00")中,冒号和数字容易变形为无法识别的符号。
文字渲染选型决策矩阵
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 品牌Logo(1-2词英文) | Flash(可接受)或Pro(保险) | 短文字Flash基本能胜任 |
| 产品包装文字(中英混合) | Pro | 混合文字Flash错误率高 |
| 社交媒体海报(含完整句子) | Pro | 长文字必须选Pro |
| 数据图表(大量数字) | Pro | 数字精确度要求高 |
| 纯图像无文字 | Flash | 省钱且足够 |
| 证书/邀请函 | Pro | 正式文档不容有错 |
价格与成本深度分析
价格差异是影响选型的重要因素,尤其对于大规模商业应用。但简单比较单价是不够的——我们需要结合质量、效率、使用场景进行综合成本分析。
官方定价详解
| 计费项目 | Gemini 3 Pro Image | Gemini 2.5 Flash Image | 价格比 |
|---|---|---|---|
| 1K分辨率 | $0.134/张 | $0.039/张 | Pro贵3.4倍 |
| 2K分辨率 | $0.134/张 | 不支持 | - |
| 4K分辨率 | $0.24/张 | 不支持 | - |
| Batch API(1K-2K) | $0.067/张 | $0.0195/张 | Pro贵3.4倍 |
| Batch API(4K) | $0.12/张 | 不支持 | - |
| 输入token | $1.25/百万 | $0.075/百万 | Pro贵17倍 |
| 输出token | $5/百万 | $0.3/百万 | Pro贵17倍 |
需要注意的是,图像生成的主要成本是图像生成费用本身,输入/输出token费用在总成本中占比很小(通常<5%)。因此主要应关注图像生成单价的差距。
不同业务场景的月度成本计算
场景A:小型电商产品图(5,000张/月,无文字,1K足够)
这是Flash最具优势的场景:纯产品展示图,不需要文字,1K分辨率用于网页展示完全足够。
| 方案 | 计算 | 月成本 |
|---|---|---|
| Flash标准API | 5,000 × $0.039 | $195 |
| Flash Batch API | 5,000 × $0.0195 | $97.5 |
| Pro标准API | 5,000 × $0.134 | $670 |
| Pro Batch API | 5,000 × $0.067 | $335 |
最优方案:Flash Batch API,月成本$97.5,相比Pro节省约71%。
场景B:内容营销团队(2,000张社媒图/月,含大量文字)
这是文字需求主导的场景,Flash的高错误率会导致大量返工。
| 方案 | 计算 | 月成本 | 备注 |
|---|---|---|---|
| Pro标准API | 2,000 × $0.134 | $268 | 一次成功率95% |
| Pro Batch API | 2,000 × $0.067 | $134 | 推荐 |
| Flash(含返工) | 2,000 × 3 × $0.039 | $234 | 平均重试3次 |
最优方案:Pro Batch API,月成本$134。虽然Flash单价低,但大量返工后的总成本甚至可能更高,而且浪费了大量人工审核时间。
场景C:印刷出版(500张4K海报素材/月)
4K需求只有Pro能满足,没有备选方案。
| 方案 | 计算 | 月成本 |
|---|---|---|
| Pro标准API(4K) | 500 × $0.24 | $120 |
| Pro Batch API(4K) | 500 × $0.12 | $60 |
| Flash | 不支持 | - |
唯一方案:Pro,推荐使用Batch API进一步节省成本。
场景D:混合需求(每月3,000张,60%无文字+40%有文字)
很多团队的实际需求是混合型的,需要智能分配两个模型。
| 方案 | 计算 | 月成本 |
|---|---|---|
| 全部Pro标准 | 3,000 × $0.134 | $402 |
| 全部Flash标准 | 3,000 × $0.039 | $117(但有40%需返工) |
| 混合策略 | 1,800 × $0.039 + 1,200 × $0.134 | $231 |
| 混合策略+Batch | 1,800 × $0.0195 + 1,200 × $0.067 | $115.5 |
最优方案:混合策略+Batch API,无文字部分用Flash,有文字部分用Pro,月成本$115.5,相比全部Pro节省约71%。
成本优化核心公式:智能分流(按需求类型选模型)+ Batch API(50%折扣)= 综合节省60-70%。不要为不需要的功能付费,也不要在需要的功能上妥协。
成本优化高级策略
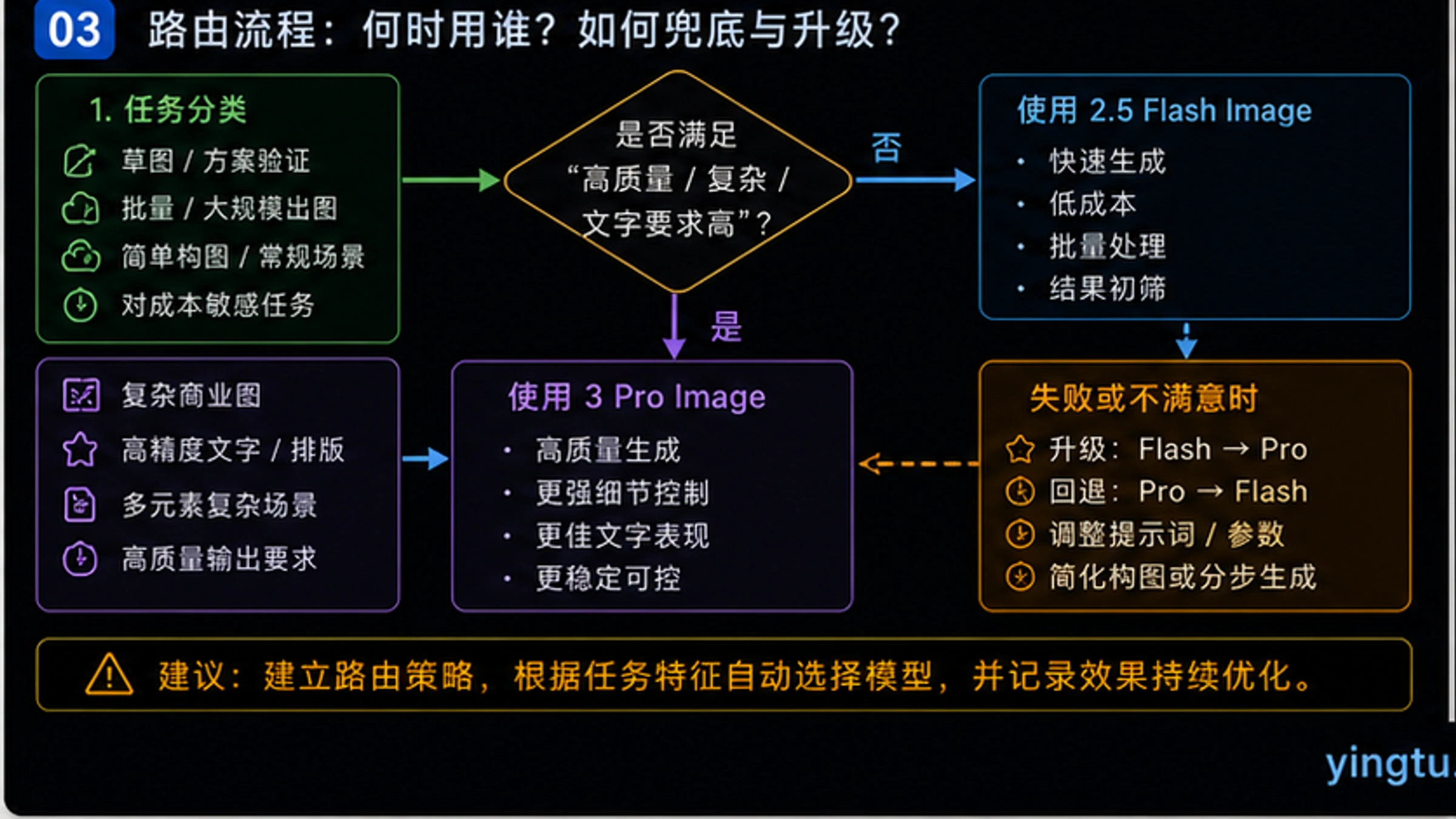
策略1:智能任务分流
建立自动化的任务分类系统,根据prompt内容自动选择模型。简单的关键词匹配即可实现基础分流:检测prompt中是否包含引号内的文字内容、是否要求2K以上分辨率、是否涉及复杂多元素场景——满足任一条件则路由到Pro,否则使用Flash。
策略2:批量处理流水线
对于非实时需求,建立Batch处理流水线。将白天收集的图片需求在晚间批量提交,第二天早上收取结果。这种方式可以获得50%的Batch折扣,大幅降低成本。
策略3:第三方中转服务
部分第三方平台提供Gemini API访问,价格可能低于官方。例如laozhang.ai提供的服务,除了可能的价格优势外,还解决了国内用户的访问问题。选择这类服务时需要评估稳定性、延迟和数据安全性。但如果你的项目有严格的SLA要求、需要企业级技术支持、或必须通过数据合规审计,建议直接使用Google官方API。
API集成开发完整指南
掌握两个模型的API集成方法,是将选型决策落地为实际生产力的关键。这里提供完整的代码示例,包含生产环境所需的错误处理和最佳实践。
Gemini 3 Pro Image集成示例
hljs pythonimport requests
import base64
import time
from typing import Optional, Literal, Dict, Any
from dataclasses import dataclass
@dataclass
class GenerationConfig:
"""图像生成配置"""
size: Literal["1K", "2K", "4K"] = "2K"
aspect_ratio: str = "16:9"
thinking_mode: bool = False
max_retries: int = 3
timeout: int = 60
class GeminiProImageGenerator:
"""Gemini 3 Pro Image API封装,包含完整错误处理和重试机制"""
def __init__(self, api_key: str, base_url: str = None):
self.api_key = api_key
self.base_url = base_url or "https://generativelanguage.googleapis.com/v1beta"
self.model = "models/gemini-3-pro-image-preview"
def generate(
self,
prompt: str,
config: GenerationConfig = None
) -> Optional[bytes]:
"""
生成图像并返回二进制数据
Args:
prompt: 图像描述(支持中英文)
config: 生成配置
Returns:
图像二进制数据,失败返回None
"""
if config is None:
config = GenerationConfig()
url = f"{self.base_url}/{self.model}:generateContent"
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {
"imageSize": config.size,
"aspectRatio": config.aspect_ratio
}
}
}
# 启用思维模式(复杂场景推荐)
if config.thinking_mode:
payload["generationConfig"]["thinkingConfig"] = {
"thinkingBudget": 1024
}
headers = {
"Content-Type": "application/json",
"x-goog-api-key": self.api_key
}
for attempt in range(config.max_retries):
try:
response = requests.post(
url,
headers=headers,
json=payload,
timeout=config.timeout
)
if response.status_code == 200:
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return base64.b64decode(image_data)
elif response.status_code == 429:
wait_time = (2 ** attempt) * 5
print(f"速率限制,等待{wait_time}秒后重试...")
time.sleep(wait_time)
continue
elif response.status_code == 400:
error = response.json().get("error", {})
print(f"请求错误: {error.get('message', '未知错误')}")
return None
else:
print(f"未知状态码: {response.status_code}")
continue
except requests.exceptions.Timeout:
print(f"请求超时,第{attempt + 1}次重试...")
continue
except Exception as e:
print(f"未知错误: {e}")
return None
print("达到最大重试次数,生成失败")
return None
# 使用示例
generator = GeminiProImageGenerator(api_key="your-api-key")
# 简单图像(无需思维模式)
simple_config = GenerationConfig(size="2K", thinking_mode=False)
simple_image = generator.generate(
"一只橘猫躺在阳光下的窗台上",
simple_config
)
# 复杂带文字图像(启用思维模式)
complex_config = GenerationConfig(size="2K", thinking_mode=True)
poster_image = generator.generate(
"设计一张咖啡店促销海报,主标题'早鸟特惠 7:00-9:00',副标题'美式咖啡立减5元'",
complex_config
)
# 4K印刷素材
print_config = GenerationConfig(size="4K", thinking_mode=True, timeout=90)
print_image = generator.generate(
"专业风景摄影:雪山倒映在平静湖面上,日出时分,金色光线",
print_config
)
Gemini 2.5 Flash Image集成示例
hljs pythonimport requests
import base64
import time
from typing import Optional, List
import concurrent.futures
class GeminiFlashImageGenerator:
"""Gemini 2.5 Flash Image API封装,针对高速批量场景优化"""
def __init__(self, api_key: str, base_url: str = None):
self.api_key = api_key
self.base_url = base_url or "https://generativelanguage.googleapis.com/v1beta"
self.model = "models/gemini-2.5-flash-image"
def generate(
self,
prompt: str,
aspect_ratio: str = "1:1",
max_retries: int = 2
) -> Optional[bytes]:
"""
快速生成单张图像
Args:
prompt: 图像描述
aspect_ratio: 宽高比
max_retries: 最大重试次数(Flash失败率低,默认2次即可)
Returns:
图像二进制数据
"""
url = f"{self.base_url}/{self.model}:generateContent"
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": aspect_ratio}
}
}
headers = {
"Content-Type": "application/json",
"x-goog-api-key": self.api_key
}
for attempt in range(max_retries):
try:
response = requests.post(url, headers=headers, json=payload, timeout=15)
if response.status_code == 200:
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return base64.b64decode(image_data)
elif response.status_code == 429:
time.sleep(2)
continue
except Exception as e:
print(f"错误: {e}")
continue
return None
def generate_batch(
self,
prompts: List[str],
max_workers: int = 10
) -> dict:
"""
高并发批量生成(Flash的速度优势在批量场景更明显)
Args:
prompts: prompt列表
max_workers: 并发数(Flash速度快,可以开更高并发)
Returns:
{prompt: image_data} 映射
"""
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_prompt = {
executor.submit(self.generate, p): p
for p in prompts
}
for future in concurrent.futures.as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
results[prompt] = future.result()
except Exception as e:
print(f"'{prompt[:30]}...'处理失败: {e}")
results[prompt] = None
return results
# 使用示例
flash = GeminiFlashImageGenerator(api_key="your-api-key")
# 单张快速生成(~3秒)
quick_image = flash.generate("白色背景产品摄影:一杯热拿铁,俯拍")
# 批量生成(充分利用Flash的速度优势)
product_prompts = [
"产品摄影:iPhone 15 Pro,钛金属,侧面视角",
"产品摄影:AirPods Pro 2,白色背景",
"产品摄影:MacBook Air M3,星光色,45度角",
# ... 更多prompts
]
# 10并发,100张图约30秒完成
batch_results = flash.generate_batch(product_prompts, max_workers=10)
选型决策完整框架
基于前文的深度分析,我们构建了一个完整的选型决策框架。这个框架覆盖了从需求分析到最终选择的全过程。
决策树流程图
开始选型
│
▼
需要4K分辨率输出?
├── 是 → Gemini 3 Pro Image(唯一选择)
│
└── 否 → 需要2K分辨率?
│
├── 是 → Gemini 3 Pro Image
│
└── 否(1K足够)→ 图片包含文字?
│
├── 是,文字>5字符/中文>3字 → Gemini 3 Pro
│
├── 是,文字≤5字符/中文≤3字 → 准确度要求?
│ ├── 必须100%准确 → Pro
│ └── 可接受偶尔错误 → Flash(省3.4倍)
│
└── 否(无文字)→ 场景复杂度?
├── 复杂(多元素互动)→ Pro(思维模式)
│
└── 简单 → 响应速度要求?
├── 需要即时响应(<5秒)→ Flash
│
└── 可接受等待 → 预算考量?
├── 成本敏感 → Flash
└── 质量优先 → Pro
场景快速参考表
| 应用场景 | 推荐模型 | 核心理由 |
|---|---|---|
| 印刷品/大幅海报 | Pro (4K) | 分辨率硬性要求 |
| 电商详情页大图 | Pro (2K) | 支持放大查看 |
| 社交媒体配图 | Flash | 1K足够,省成本 |
| 营销海报(含文字) | Pro | 文字准确性关键 |
| 产品白底图(无文字) | Flash | 写实度足够,省钱 |
| 数据可视化/图表 | Pro | 数字精确度要求 |
| 聊天机器人图像 | Flash | 即时响应重要 |
| 品牌吉祥物系列 | Pro | 角色一致性需14张参考图 |
| 简单Logo设计 | Flash或Pro | 看文字复杂度 |
| A/B测试素材 | Flash | 快速迭代重要 |
一句话选型原则:4K/2K/文字/复杂场景 → Pro;简单无文字/速度优先/成本敏感 → Flash。混合使用是最优解,可节省60-70%成本。
常见问题解答
Q1: Flash生成的1K图像可以后期放大到2K/4K吗?
技术上可以使用AI超分辨率工具(如Real-ESRGAN、Topaz Gigapixel)进行放大,但有几个需要考虑的因素。首先,放大后的图像细节是AI"猜测"生成的,无法与原生高分辨率图像的真实细节相比。其次,如果图像包含文字,放大后文字边缘可能出现锯齿或模糊,严重影响可读性。第三,AI放大需要额外的处理时间和计算成本,综合算下来可能不比直接用Pro生成更划算。我们的建议是:如果最终确实需要2K/4K分辨率,直接使用Pro原生生成是更可靠的选择。
Q2: 两个模型生成的图像风格一致吗?
大体一致,毕竟同属Gemini家族,共享基础训练数据和视觉美学。但在细节层面存在差异:Pro在细节丰富度、光影层次、色彩过渡上更加精细;Flash有时会显得略"粗糙"或"简化"。对于追求视觉一致性的品牌项目(如系列广告、产品家族图),建议统一使用一个模型,避免风格差异带来的违和感。如果成本允许,统一用Pro是更保险的选择。
Q3: Flash有免费配额吗?Pro呢?
根据Google官方文档,Flash提供有限的免费配额,约50-100次/天(具体数量可能随时调整)。这个配额适合个人学习、小规模测试使用。Pro目前没有免费层,所有调用都需要付费。对于需要测试两个模型效果的用户,建议先用Flash的免费配额进行基础测试,确认需要Pro能力后再付费使用。
Q4: 国内用户如何选择和访问?
两个模型在访问限制上完全相同,都需要通过科学上网或第三方中转服务访问。对于国内用户,可以考虑使用laozhang.ai等中转服务,可以实现国内直连访问两个模型,延迟通常在50-200ms之间。但如果项目涉及敏感数据、需要企业级SLA保障,或合规要求必须使用官方渠道,建议配置稳定的VPN直接访问Google官方API。选型上,国内用户应该基于业务需求选择,访问方式不影响模型能力的发挥。
Q5: 两个模型可以混合使用吗?
不仅可以,而且强烈推荐。最佳实践是建立智能分流机制:分析每个图片需求的特性(是否含文字、分辨率要求、复杂度),自动路由到最合适的模型。这种混合策略可以在保证质量的前提下最大化成本效益。前文的成本分析显示,混合策略可以比纯用Pro节省50-70%的成本。
Q6: 思维模式什么时候该开、什么时候该关?
思维模式(Thinking Mode)会增加约30%的生成时间和少量token成本,因此不是所有场景都需要开启。建议开启的场景:复杂多元素构图(3个以上物体的精确位置关系)、信息图表和数据可视化、需要精确空间关系的场景描述、创意性强的抽象概念表达。建议关闭的场景:简单单物体渲染、纯风格转换、无文字的简单产品图。简单来说,如果你的prompt可以用一句话描述清楚,不需要思维模式;如果需要多句话描述复杂场景,开启思维模式会有明显帮助。
Q7: 两个模型的API更新频率和稳定性如何?
Gemini 2.5 Flash处于"Stable"状态,API相对稳定,主要是bug修复和小幅优化。Gemini 3 Pro处于"Preview"状态,更新更频繁,可能有功能变动。对于生产环境,建议:锁定API版本号(如果可能)、定期检查官方更新日志、保持代码版本控制、建立回归测试确保更新不影响输出质量。Flash的稳定性更适合对变动敏感的生产环境,Pro则需要更积极的版本跟踪。
相关阅读:
- Gemini 3 Pro Image 模型对比总览
- Gemini 3 Pro vs Imagen 3:多模态vs专用扩散
- Gemini 3 Pro vs AuraFlow:商用vs开源
- Gemini 3 Pro Image 完整定价指南