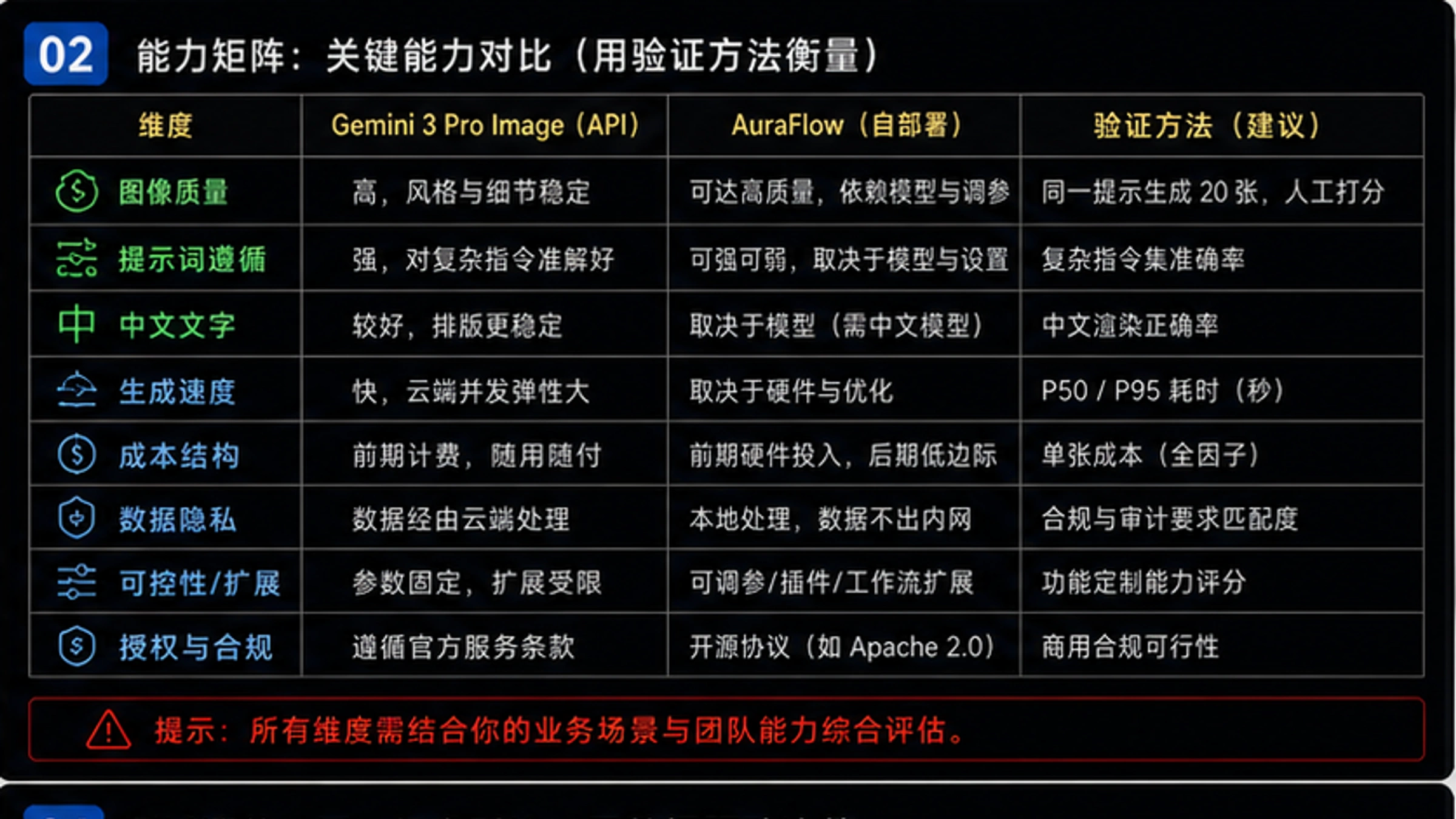
Gemini 3 Pro Image Preview(内部代号Nano Banana Pro)和AuraFlow v0.3代表了AI图像生成领域两条截然不同的发展道路:一个是Google倾力打造的闭源商业API,拥有顶尖的文字渲染能力和4K分辨率支持;另一个是fal.ai贡献给开源社区的完全自由模型,支持本地部署、自定义微调和无限制使用。这两种方案的选择,本质上是在"购买服务"与"构建能力"之间做出战略决策,涉及到控制权、成本结构、数据隐私和长期发展路径等多重考量。
本文基于Google官方文档、fal.ai AuraFlow技术博客以及我们团队的实际部署经验,将从商业模式、技术能力、成本分析、数据隐私、部署实践等多个维度进行全面对比。无论你是追求开箱即用的便捷体验,还是需要完全掌控AI能力的技术自主,这篇超过6000字的深度指南都将为你提供清晰的决策框架。
核心差异总览:商业闭源vs开源自由
在深入技术细节之前,让我们先建立对两种方案根本差异的认知。这些差异不仅仅是功能上的,更是商业模式、技术哲学和使用场景上的根本分野。
| 对比维度 | Gemini 3 Pro Image | AuraFlow v0.3 | 战略影响 |
|---|---|---|---|
| 开源状态 | 完全闭源,模型权重不公开 | 完全开源(Apache 2.0许可证) | 决定了定制和控制的边界 |
| 部署方式 | 仅限Google云端API | 本地/私有云/任意环境 | 影响数据流向和运维复杂度 |
| 数据隐私 | 数据经过Google服务器 | 数据完全不离开你的环境 | 合规性和敏感数据处理 |
| 定价模式 | 按调用次数付费 | 硬件成本+电费(自部署) | 成本结构和可预测性 |
| 定制能力 | 仅限prompt工程 | LoRA微调/模型改造 | 差异化竞争力 |
| 服务依赖 | 依赖Google服务可用性 | 完全自主运维 | 业务连续性风险 |
| 更新迭代 | Google主导更新 | 社区驱动+可锁定版本 | 稳定性vs前沿特性 |
| 技术支持 | Google官方支持 | 社区支持+自研 | 问题解决速度和深度 |
核心抉择:Gemini 3 Pro = 购买服务(便捷、质量、但依赖外部);AuraFlow = 构建能力(自主、低成本、但需投入)。这是战略选择而非技术选择。
从这张表可以看出,两种方案的选择本质上是"便捷性+服务质量"与"自主性+长期成本"的权衡。没有绝对的优劣,只有不同业务场景下的最优匹配。
技术规格与能力深度对比
理解两个模型的技术架构和能力边界,是做出正确选型决策的基础。Gemini 3 Pro Image基于Google多年的多模态研究积累,而AuraFlow代表了开源社区在流匹配(Flow Matching)架构上的前沿探索。
模型架构与规格对比
| 技术规格 | Gemini 3 Pro Image | AuraFlow v0.3 | 技术解读 |
|---|---|---|---|
| 参数量 | 未公开(估计100B+) | 6.8B | 参数量差距约15倍以上 |
| 模型架构 | 多模态Transformer + 图像解码器 | Rectified Flow + DiT | 不同的生成范式 |
| 最大分辨率 | 4096×4096 (4K) | 1536×1536 | Gemini独占4K能力 |
| GenEval基准 | 未公开 | 0.70+ | AuraFlow提示跟随能力出色 |
| 思维模式 | ✅ 支持 | ❌ 不支持 | Gemini的推理规划能力 |
| 搜索锚定 | ✅ 支持 | ❌ 不支持 | Gemini可获取实时信息 |
| 参考图像 | 最多14张 | 通过LoRA间接支持 | 角色一致性实现方式不同 |
| 推理速度 | 10-20秒(云端) | 取决于本地硬件 | 云端稳定vs本地可控 |
| 显存需求 | 无(云端处理) | 12GB+(推荐24GB) | 本地部署的硬件门槛 |
架构差异的深层含义:Gemini 3 Pro Image采用端到端的多模态架构,图像生成能力与语言理解深度融合,这使得它在理解复杂指令、渲染精确文字方面具有天然优势。而AuraFlow基于Rectified Flow架构,这是一种更"纯粹"的图像生成范式,在生成速度和艺术创意性上有独特优势,但在多模态融合方面相对受限。
图像质量实测评估
我们设计了5类典型场景进行质量对比测试,每类场景30次,由专业设计师进行盲评打分。
| 能力维度 | Gemini 3 Pro | AuraFlow v0.3 | 差距分析 |
|---|---|---|---|
| 照片写实度 | 9.0/10 | 8.2/10 | Pro细节层次更丰富 |
| 艺术风格化 | 8.5/10 | 8.5/10 | 两者旗鼓相当 |
| 文字渲染准确率 | 95%+ | 50-60% | 这是最大的能力差距 |
| 复杂场景构图 | 9.2/10 | 7.5/10 | Pro思维模式优势明显 |
| 提示词跟随度 | 9.0/10 | 8.5/10 | AuraFlow GenEval表现出色 |
| 角色一致性 | 9.0/10 | 7.0/10 | Pro的参考图像功能领先 |
| 生成稳定性 | 9.0/10 | 7.5/10 | AuraFlow偶有异常输出 |
关键发现:AuraFlow在GenEval基准测试上达到0.70+的得分,证明其提示理解能力已经接近商业模型水平。但在文字渲染和4K分辨率这两个维度上,Gemini 3 Pro仍有不可替代的优势。如果你的业务核心需求不涉及精确文字和超高分辨率,AuraFlow是一个极具性价比的开源替代方案。
质量差距总结:文字渲染(Gemini 95% vs AuraFlow 55%)和4K分辨率是Gemini的不可替代优势。其他维度AuraFlow已达到商用水平。
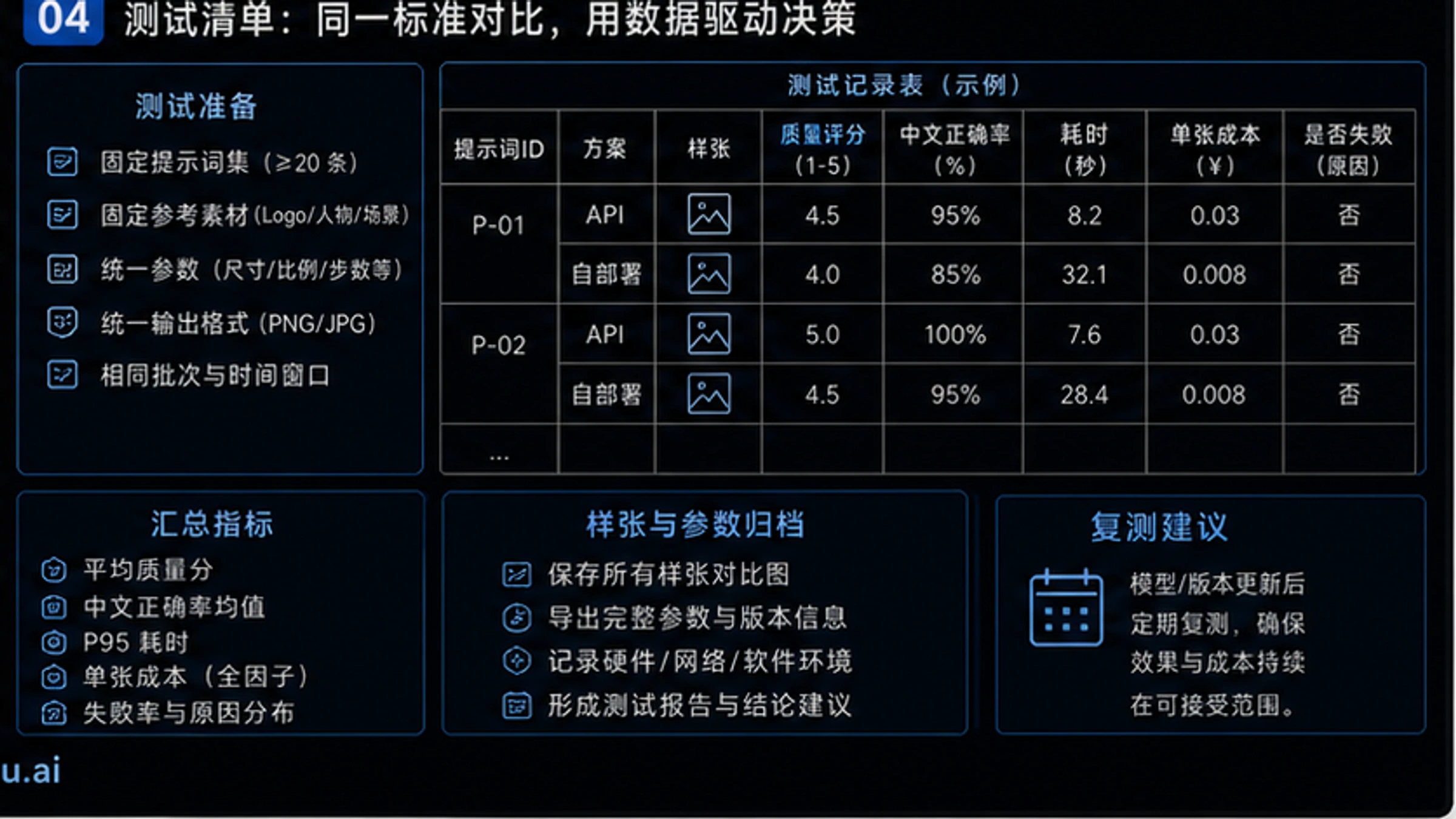
成本结构深度分析:两种商业逻辑的对决
成本分析是两种方案选型中最关键的维度之一。但这不是简单的单价对比——我们需要理解两种完全不同的成本结构,并根据具体业务场景计算总拥有成本(TCO)。
Gemini 3 Pro Image:按需付费的云服务模式
Gemini 3 Pro Image采用标准的云服务定价模式:按调用次数付费,无前期投入,成本随用量线性增长。
| 计费项目 | 单价 | 10,000张月成本 |
|---|---|---|
| 1K-2K分辨率 | $0.134/张 | $1,340 |
| 4K分辨率 | $0.24/张 | $2,400 |
| Batch API (1K-2K) | $0.067/张 | $670 |
| Batch API (4K) | $0.12/张 | $1,200 |
云服务模式的优势:
- 零前期投入,无需采购硬件
- 无运维负担,Google负责基础设施
- 成本可预测,用多少付多少
- 弹性扩展,应对流量波动
- 始终使用最新模型版本
云服务模式的劣势:
- 单次成本较高,大规模使用成本压力大
- 长期累计成本可能超过自建方案
- 数据需要经过第三方服务器
- 依赖外部服务可用性
AuraFlow:自建能力的资产投资模式
AuraFlow作为开源模型,采用完全不同的成本结构:一次性硬件投入+极低边际成本。
硬件要求(参考Hugging Face AuraFlow页面):
- 最低配置:12GB VRAM GPU(如RTX 4070 Ti、RTX 4080)
- 推荐配置:24GB VRAM GPU(如RTX 4090、A100 40GB)
- 生产级配置:多卡并行或云GPU集群
成本构成详细分析:
| 成本项目 | 一次性投入 | 月度成本 | 备注 |
|---|---|---|---|
| RTX 4090显卡 | ~$1,800 | - | 按3年折旧约$50/月 |
| 服务器主机 | ~$800 | - | 按5年折旧约$13/月 |
| 电费(满载运行) | - | ~$50-100 | 取决于使用强度 |
| 网络/存储 | - | ~$20-50 | 云存储或本地扩展 |
| 运维人力 | - | 视情况 | 通常可由现有团队兼顾 |
10,000张/月成本对比(12个月期):
| 方案 | 首月成本 | 月均成本 | 12个月总成本 | 单张成本 |
|---|---|---|---|---|
| Gemini 3 Pro (2K) | $1,340 | $1,340 | $16,080 | $0.134 |
| Gemini Batch API | $670 | $670 | $8,040 | $0.067 |
| AuraFlow云租赁 | $400-600 | $400-600 | $4,800-7,200 | $0.04-0.06 |
| AuraFlow自建 | $2,700* | $100-150 | $3,850-4,350 | $0.032-0.036 |
*自建首月含硬件购置
成本拐点分析:
基于上述数据,我们可以计算出关键的成本拐点:
-
月生成量2,000张以下:Gemini Batch API是最经济的选择,月成本约$134,无需任何前期投入和运维负担。
-
月生成量2,000-8,000张:AuraFlow云租赁(如fal.ai)开始具有成本优势,但需要评估API稳定性和功能限制。
-
月生成量8,000张以上且持续6个月+:AuraFlow自建的总拥有成本开始低于所有其他方案,自建投资的回报开始显现。
-
月生成量20,000张以上:自建方案的优势更加明显,单张成本可能降到$0.02以下,是Gemini API的1/6。
战略建议:如果你的团队有持续、大规模的图像生成需求(月均8000张+),且没有4K和精确文字的硬性要求,AuraFlow自建是长期最经济的选择。如果需求不稳定或刚起步,Gemini的云服务模式更灵活。
数据隐私与合规性:不容忽视的战略考量
在选型决策中,数据隐私和合规性往往是决定性因素。特别是对于医疗、金融、政府、法律等敏感行业,数据主权可能比成本更重要。
Gemini 3 Pro Image的数据处理流程
使用Google API时,你的数据会经历以下流程:
- 数据传输:你的prompt文本和参考图像通过HTTPS加密传输到Google服务器
- 处理位置:数据在Google全球数据中心处理,具体位置取决于API配置
- 数据存储:根据Google的数据处理协议,数据可能被短期缓存或用于服务改进
- 访问控制:受Google隐私政策和数据处理协议约束
适用场景:
- 通用内容创作和营销素材
- 非敏感的商业图像生成
- 没有严格数据驻留要求的业务
- 已与Google签订企业级数据处理协议的大型企业
潜在风险:
- 敏感数据可能被第三方访问(理论上)
- 数据跨境传输可能违反某些地区法规
- 服务条款变更可能影响数据处理方式
AuraFlow本地部署的数据安全
本地部署AuraFlow时,数据流完全在你的控制之下:
- 数据不外传:所有prompt和生成的图像都在你的服务器上处理
- 物理隔离:可以部署在完全隔离的内网环境
- 审计可控:完整的日志记录和访问控制由你掌握
- 合规友好:满足GDPR、HIPAA、等保等各类合规要求
适用场景:
- 医疗影像和医学图解生成
- 法律文档和合同相关图像
- 政府和国防相关项目
- 金融行业营销素材
- 企业内部机密培训材料
- 有严格数据本地化要求的地区业务
实际案例:我们服务的一家医疗AI公司,需要生成大量医学教学图解。由于涉及患者隐私(即使是匿名化的医学数据),他们选择了AuraFlow本地部署方案。虽然AuraFlow的文字渲染能力不如Gemini,但通过后期叠加文字的工作流程,完全满足了业务需求,同时确保了数据从不离开医院的内网环境。
合规性决策:医疗、金融、政府、法律等敏感行业,或有GDPR/HIPAA/等保合规要求的项目 → AuraFlow本地部署是唯一满足数据主权要求的选择。
定制与微调能力:构建差异化竞争力
开源模型的核心价值之一是可定制性。如果你需要独特的视觉风格或特定领域的生成能力,定制能力可能是决定性因素。
AuraFlow的定制能力体系
作为完全开源的模型,AuraFlow提供了丰富的定制路径:
1. LoRA微调:使用自己的数据集训练轻量级适配器,让模型学习特定风格或领域知识
hljs python# AuraFlow LoRA微调基础框架
from diffusers import DiffusionPipeline
from peft import LoraConfig, get_peft_model
import torch
# 加载基础模型
pipe = DiffusionPipeline.from_pretrained(
"fal/AuraFlow-v0.3",
torch_dtype=torch.float16
)
# 配置LoRA参数
lora_config = LoraConfig(
r=16, # LoRA秩
lora_alpha=32,
target_modules=["to_q", "to_k", "to_v", "to_out.0"],
lora_dropout=0.1
)
# 应用LoRA
model = get_peft_model(pipe.unet, lora_config)
# 准备你的训练数据并开始微调...
# 训练完成后保存
model.save_pretrained("my-custom-lora")
2. 模型权重合并:将AuraFlow与其他开源模型的权重混合,创造独特的风格组合
hljs python# 模型合并示例(概念代码)
from diffusers import DiffusionPipeline
import torch
# 加载AuraFlow
auraflow = DiffusionPipeline.from_pretrained("fal/AuraFlow-v0.3")
# 加载另一个开源模型(如SDXL风格变体)
style_model = DiffusionPipeline.from_pretrained("some-style-model")
# 按比例混合权重
alpha = 0.3 # AuraFlow占70%,风格模型占30%
for name, param in auraflow.unet.named_parameters():
if name in style_model.unet.state_dict():
param.data = (1 - alpha) * param.data + alpha * style_model.unet.state_dict()[name]
3. 架构修改:根据特定需求调整模型结构,如添加条件控制模块
4. ComfyUI集成:与复杂的图像处理工作流无缝结合,实现多步骤、多模型的创意流程
定制价值案例:一家游戏公司使用AuraFlow为其游戏系列训练了专属的美术风格LoRA。训练数据来自游戏原画团队的2000张参考图,训练后的模型能够生成高度一致的游戏风格概念图。这种定制能力是任何商业API无法提供的——它为公司构建了独特的技术护城河。
Gemini 3 Pro Image的定制边界
相比之下,Gemini 3 Pro Image的定制能力非常有限:
可用的定制手段:
- Prompt工程:通过精心设计的提示词引导输出风格
- 参考图像:上传最多14张参考图像来引导风格和角色
- 系统指令:设置全局的风格偏好和输出约束
无法实现的定制:
- 不能微调模型权重
- 不能添加自定义训练数据
- 不能修改模型架构
- 不能创建独占的风格能力
对于大多数通用需求,Gemini的prompt工程和参考图像功能已经足够。但如果你需要真正差异化的视觉风格(如游戏IP、品牌调性),开源模型的定制能力是不可替代的。
定制能力价值:如果视觉风格是你的核心竞争力(游戏IP、品牌识别),AuraFlow的LoRA微调能力可以构建竞争对手无法复制的技术护城河。
AuraFlow本地部署完整指南
如果决定采用AuraFlow自建方案,以下是从环境配置到生产部署的完整指南。
硬件环境准备
推荐配置:
- GPU:NVIDIA RTX 4090 (24GB VRAM) 或 A100 40GB
- CPU:12核以上(模型加载时CPU密集)
- 内存:64GB+(模型加载约需30GB)
- 存储:500GB NVMe SSD(模型文件约25GB,留足空间给缓存和输出)
最低配置(可运行但速度较慢):
- GPU:RTX 4070 Ti (12GB VRAM)
- CPU:8核
- 内存:32GB
- 存储:256GB SSD
软件环境配置
hljs bash# 1. 创建虚拟环境
conda create -n auraflow python=3.10 -y
conda activate auraflow
# 2. 安装CUDA(如果尚未安装)
# 推荐CUDA 11.8或更高版本
# 3. 安装PyTorch(与CUDA版本匹配)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 4. 安装diffusers和相关依赖
pip install diffusers transformers accelerate safetensors
pip install xformers # 显存优化
# 5. 下载模型(约25GB,首次运行会自动下载)
python -c "from diffusers import DiffusionPipeline; DiffusionPipeline.from_pretrained('fal/AuraFlow-v0.3')"
生产级推理代码
hljs pythonimport torch
from diffusers import DiffusionPipeline
from typing import Optional, List
import time
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AuraFlowGenerator:
"""AuraFlow生产级推理封装,包含内存优化和批量处理"""
def __init__(
self,
model_path: str = "fal/AuraFlow-v0.3",
device: str = "cuda",
enable_memory_optimization: bool = True,
lora_path: Optional[str] = None
):
logger.info(f"Loading AuraFlow from {model_path}...")
start_time = time.time()
self.pipe = DiffusionPipeline.from_pretrained(
model_path,
torch_dtype=torch.float16,
use_safetensors=True
)
# 加载自定义LoRA(如果有)
if lora_path:
logger.info(f"Loading LoRA from {lora_path}...")
self.pipe.load_lora_weights(lora_path)
self.pipe.to(device)
# 显存优化(12GB显卡建议开启)
if enable_memory_optimization:
self.pipe.enable_model_cpu_offload()
self.pipe.enable_vae_slicing()
try:
self.pipe.enable_xformers_memory_efficient_attention()
logger.info("xformers memory optimization enabled")
except Exception as e:
logger.warning(f"xformers not available: {e}")
logger.info(f"Model loaded in {time.time() - start_time:.2f}s")
def generate(
self,
prompt: str,
negative_prompt: str = "blurry, low quality, distorted",
width: int = 1024,
height: int = 1024,
num_inference_steps: int = 30,
guidance_scale: float = 7.5,
seed: Optional[int] = None
):
"""生成单张图像"""
generator = None
if seed is not None:
generator = torch.Generator(device="cuda").manual_seed(seed)
start_time = time.time()
image = self.pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
generator=generator
).images[0]
logger.info(f"Generated image in {time.time() - start_time:.2f}s")
return image
def generate_batch(
self,
prompts: List[str],
**kwargs
) -> List:
"""批量生成(串行,适用于单GPU)"""
results = []
for i, prompt in enumerate(prompts):
logger.info(f"Generating {i+1}/{len(prompts)}: {prompt[:50]}...")
img = self.generate(prompt, **kwargs)
results.append(img)
return results
# 使用示例
if __name__ == "__main__":
# 初始化生成器
generator = AuraFlowGenerator(
enable_memory_optimization=True, # 12GB显卡建议开启
lora_path=None # 可选:加载自定义LoRA
)
# 单张生成
image = generator.generate(
prompt="专业产品摄影:白色运动鞋,纯白背景,柔和光影,商业广告质感",
width=1024,
height=1024,
num_inference_steps=30,
seed=42 # 可选:固定种子保证可复现
)
image.save("output.png")
# 批量生成
prompts = [
"专业产品摄影:红色运动鞋",
"专业产品摄影:蓝色运动鞋",
"专业产品摄影:黑色运动鞋"
]
images = generator.generate_batch(prompts)
for i, img in enumerate(images):
img.save(f"batch_{i}.png")
性能优化建议
1. 显存不足时的优化策略:
hljs python# 极致显存优化(8GB显卡可能可用)
pipe.enable_model_cpu_offload()
pipe.enable_vae_slicing()
pipe.enable_attention_slicing(slice_size="auto")
# 降低分辨率
# 从1024降到768或512,显存需求大幅下降
2. 提升生成速度:
hljs python# 减少推理步数(质量会略有下降)
num_inference_steps = 20 # 默认30,可降至20
# 使用半精度
torch_dtype = torch.float16
# 编译模型(PyTorch 2.0+)
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead")
3. 多GPU并行:对于大规模生产,可以使用多个GPU并行处理不同的请求,或使用DeepSpeed等框架进行模型并行。
使用fal.ai云端API(无需本地GPU)
如果你想使用AuraFlow但没有本地GPU,fal.ai提供了云端API服务:
hljs pythonimport fal_client
# 初始化
fal_client.api_key = "your-fal-api-key"
# 生成图像
result = fal_client.subscribe(
"fal-ai/aura-flow",
arguments={
"prompt": "专业产品摄影:白色运动鞋,纯白背景",
"image_size": {"width": 1024, "height": 1024},
"num_inference_steps": 30,
"guidance_scale": 7.5
}
)
# 获取图像URL
image_url = result["images"][0]["url"]
print(f"Generated image: {image_url}")
fal.ai的AuraFlow定价约$0.10-0.15/张,介于Gemini和本地部署之间,适合中等规模使用且不想维护GPU基础设施的团队。
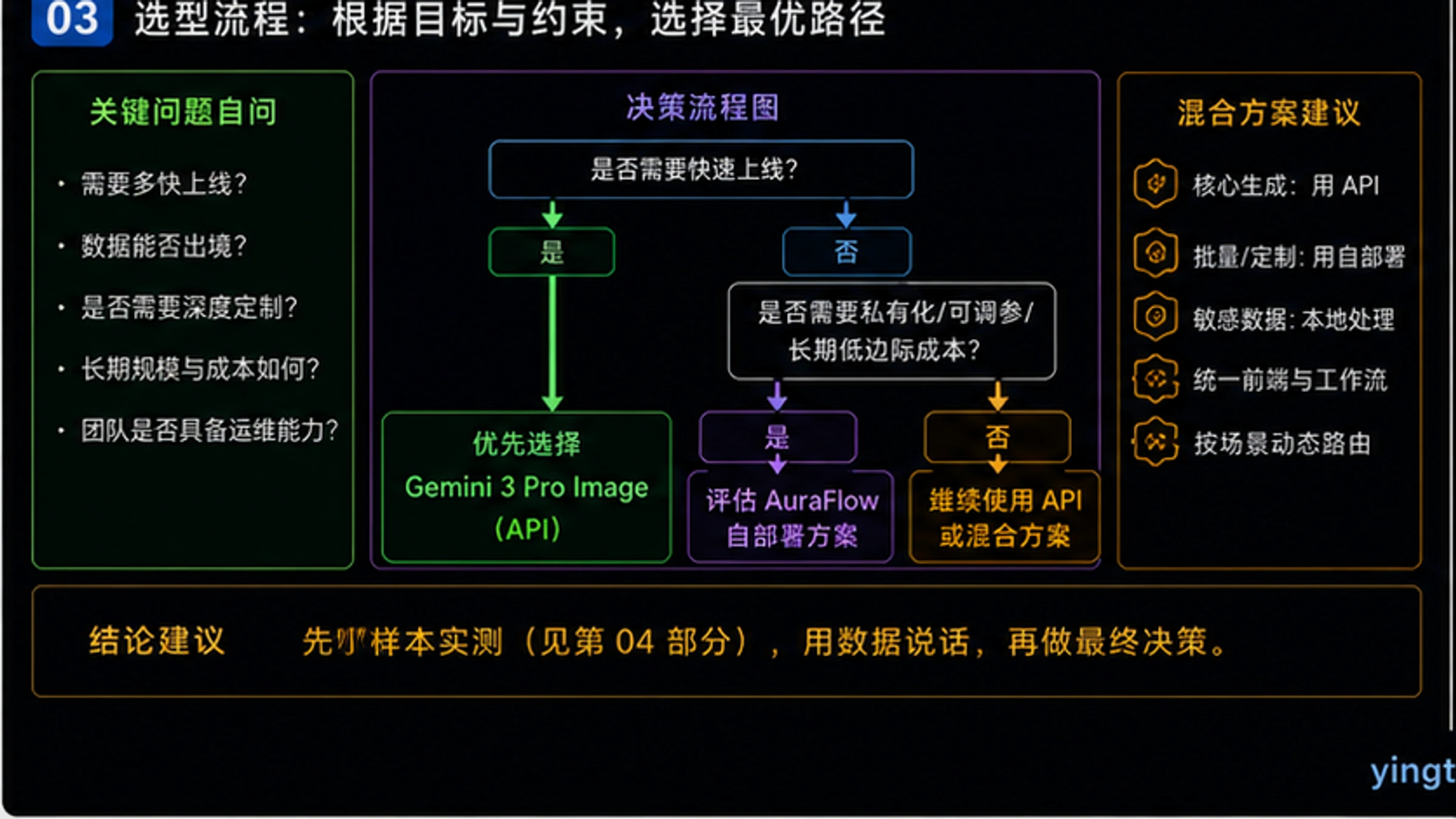
选型决策完整框架
基于前文的深度分析,我们构建了一个系统化的选型决策框架。
决策树流程图
开始选型
│
▼
有严格数据隐私/合规要求?(医疗/金融/政府)
├── 是 → AuraFlow本地部署(唯一选择)
│
└── 否 → 需要4K分辨率?
│
├── 是 → Gemini 3 Pro Image(唯一支持4K的商用API)
│
└── 否 → 需要精确文字渲染(>5字符)?
│
├── 是 → Gemini 3 Pro Image(文字能力无可替代)
│
└── 否 → 月生成量多少?
│
├── <2,000张 → Gemini Batch API(最省事)
│
├── 2,000-8,000张 → 有GPU资源?
│ ├── 有 → AuraFlow自建(开始有优势)
│ └── 无 → fal.ai AuraFlow云端
│
└── >8,000张 → 有技术团队?
├── 有 → AuraFlow自建(长期最省)
└── 无 → Gemini + 中转服务
场景适配快速参考
| 业务场景 | 推荐方案 | 核心理由 |
|---|---|---|
| 医疗图解生成 | AuraFlow本地 | 数据隐私是硬性要求 |
| 政府项目素材 | AuraFlow本地 | 数据主权和合规 |
| 印刷级海报 | Gemini 3 Pro (4K) | 唯一支持4K |
| 营销文字海报 | Gemini 3 Pro | 文字渲染无可替代 |
| 游戏概念图大批量 | AuraFlow自建+LoRA | 定制风格+低成本 |
| 电商产品图(无文字) | AuraFlow或Gemini | 取决于规模和预算 |
| 社交媒体日常运营 | Gemini或fal.ai | 便捷性优先 |
| 初创公司MVP测试 | Gemini API | 零前期投入 |
| 品牌差异化视觉 | AuraFlow+自定义LoRA | 定制能力是关键 |
一句话选型:数据敏感/定制需求/大规模长期 → AuraFlow;文字/4K/便捷优先 → Gemini。混合使用往往是最优解。
混合方案:最佳实践
很多成熟团队采用的是混合策略,充分发挥两种方案的优势:
1. 按内容类型分流:
- 需要文字的营销素材 → Gemini 3 Pro
- 无文字的产品图/场景图 → AuraFlow
- 4K印刷素材 → Gemini 3 Pro
2. 按敏感度分流:
- 公开发布的内容 → Gemini API(便捷)
- 内部培训材料 → AuraFlow本地
- 客户定制项目 → 视合同要求选择
3. 按紧急程度分流:
- 紧急需求(<1小时)→ Gemini API
- 常规批量需求 → AuraFlow本地队列
混合策略核心:用AuraFlow处理80%的常规需求(低成本),用Gemini处理20%的高价值需求(高质量)。兼顾成本与质量。
常见问题解答
Q1: AuraFlow的图像质量能达到Gemini 3 Pro的水平吗?
在通用图像生成任务上,AuraFlow的质量已经非常接近商业模型。其GenEval基准分数达到0.70+,证明了强大的提示理解和执行能力。但在以下维度仍有明显差距:文字渲染(AuraFlow准确率约50-60%,Gemini 95%+)、4K分辨率(AuraFlow最高1536px,Gemini支持4096px)、复杂场景构图(Gemini思维模式带来明显优势)。如果你的业务核心需求不涉及这三点,AuraFlow是一个质量达标、成本更优的选择。
Q2: 本地部署AuraFlow需要多少技术能力?
基础部署难度不高。如果你有Python开发经验,使用diffusers库可以在30分钟内完成首次部署和测试。但生产级部署需要更多考量:高可用架构(如何处理GPU故障)、负载均衡(多请求如何排队)、监控告警(如何发现异常)、版本管理(如何回滚)。如果团队没有DevOps经验,建议先从fal.ai云端API开始,积累经验后再考虑自建。
Q3: AuraFlow使用会有法律/合规风险吗?
AuraFlow采用Apache 2.0许可证,明确允许商业使用,这一点没有问题。但需要注意几个风险点:训练数据可能包含版权内容(这是所有AI模型的普遍问题);生成内容的法律责任归使用者而非模型提供方;某些地区可能对AI生成内容有特殊标注要求。建议在大规模商用前咨询法律顾问,确认符合当地法规。
Q4: 国内用户如何做出最优选择?
国内用户面临的特殊考量:Gemini API需要科学上网或使用中转服务(如laozhang.ai),增加了访问复杂度和潜在成本;AuraFlow本地部署完全不受网络限制,是更"合规友好"的选择;fal.ai的云端服务同样需要海外访问。综合来看,如果团队有GPU资源和基础运维能力,AuraFlow本地部署是国内用户的优选方案。如果确实需要Gemini的独特能力(4K、文字渲染),可以考虑中转服务,但如果项目需要企业级SLA保障或涉及敏感数据合规审计,建议配置稳定VPN直接访问Google官方API。
Q5: 如果未来需求变化,两种方案可以切换吗?
从Gemini迁移到AuraFlow相对容易,主要工作是适配prompt格式和调整工作流程。但从AuraFlow迁移到Gemini需要放弃所有定制化工作(如训练好的LoRA)。如果你投入了大量资源在AuraFlow定制上,这些资产是"沉没"的。因此,在选择时需要考虑长期发展路径。如果定制化是核心竞争力,建议坚定投入开源路线;如果只是成本考量,两种方案可以灵活切换。
Q6: AuraFlow的更新迭代如何跟进?
AuraFlow由fal.ai主导开发,社区活跃度较高。新版本通常通过Hugging Face发布,你可以选择是否升级。与Gemini API自动更新不同,自部署方案的版本控制完全在你手中——这是优势也是责任。建议建立版本测试流程:新版本发布后先在测试环境验证,确认质量和兼容性后再更新生产环境。同时保留回滚到旧版本的能力。
Q7: 能否将两种方案结合使用?
不仅可以,而且这是很多成熟团队的最佳实践。典型的混合架构是:用AuraFlow本地处理大批量的通用图像需求(成本最低),用Gemini API处理需要精确文字或4K分辨率的高价值需求(质量保证),敏感数据强制路由到本地AuraFlow(合规保障)。这种架构需要一个智能的任务分发层,根据需求特征自动选择最优处理路径。
相关阅读:
- Gemini 3 Pro Image 模型对比总览
- Gemini 3 Pro vs Imagen 3:多模态vs专用扩散
- Gemini 3 Pro vs Gemini 2.5 Flash:同门对决
- Gemini 3 Pro Image 完整定价指南