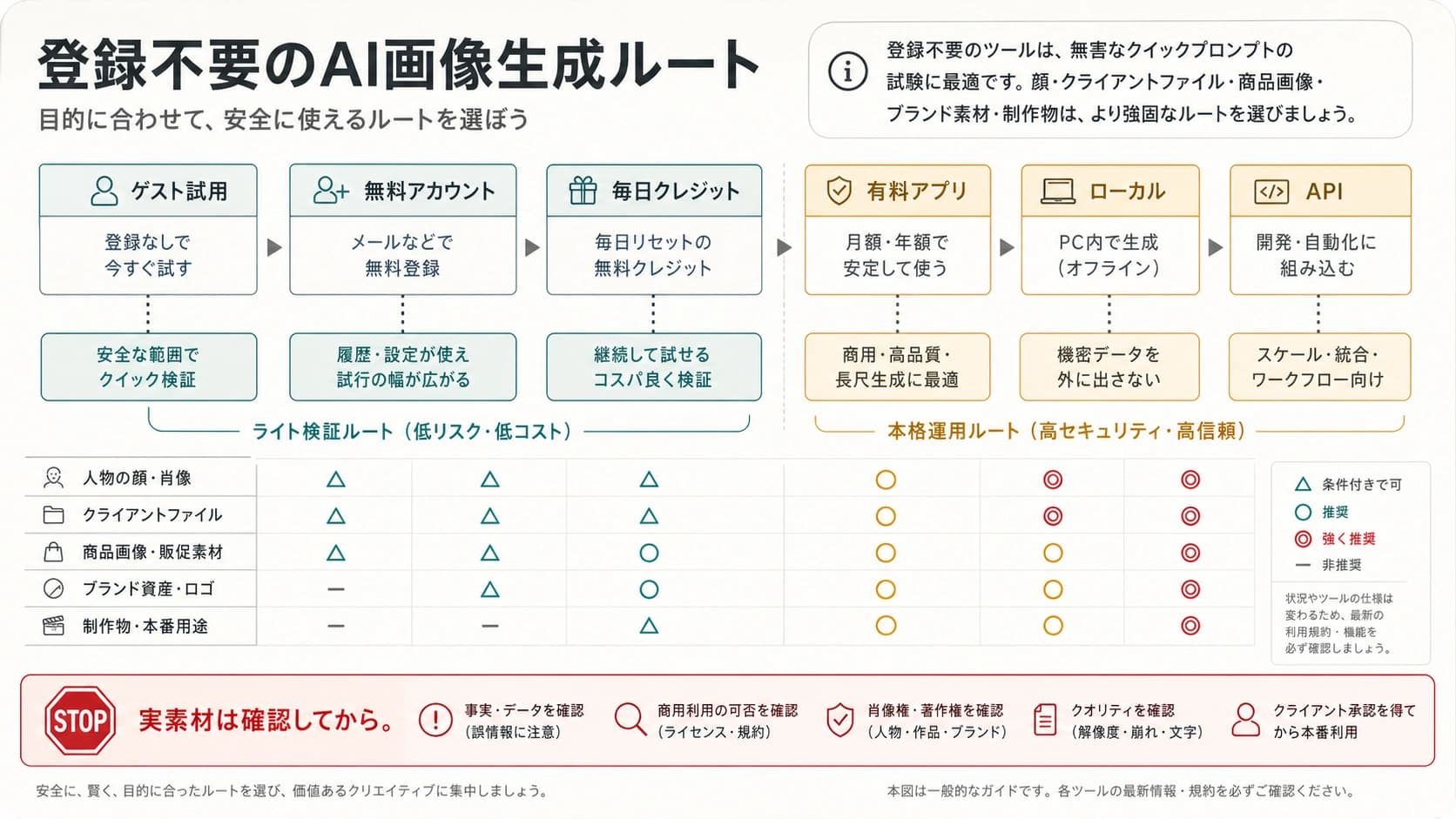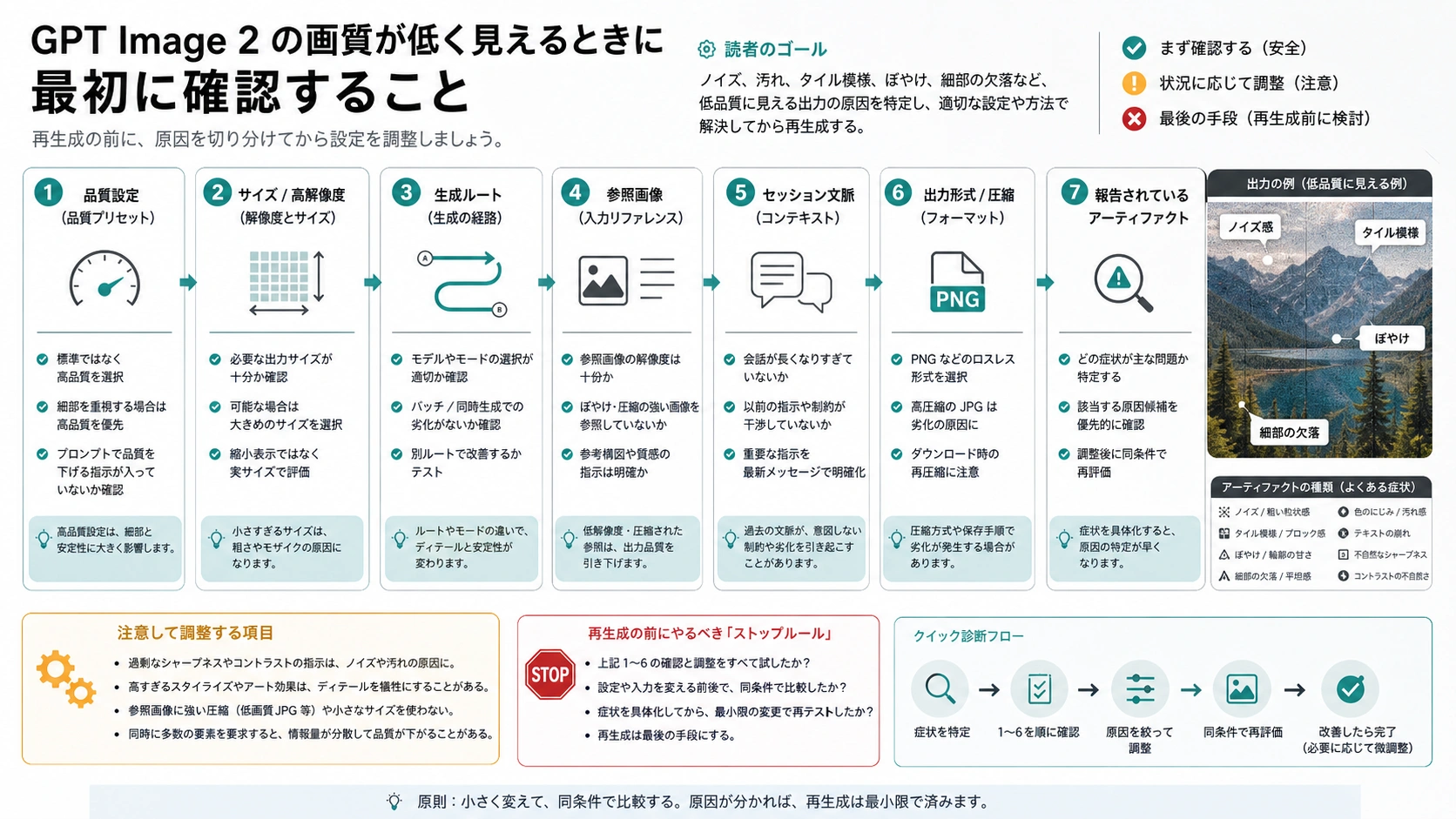
GPT Image 2の出力がぼやける、汚れる、ノイズが乗る、同じ模様が敷き詰められる、編集したら元画像より悪くなる。そう見えたときは、まずプロンプトを増やすより、quality、size、生成ルート、参照画像、会話の文脈、保存後の圧縮を切り分けます。
最初に見る分岐はこれです。
| 見えている症状 | 先に確認するもの | 最初の処置 | 根拠にするもの |
|---|---|---|---|
| 全体が甘い、細部が出ない | quality、size、保存後の圧縮 | mediumまたはhighで同条件の比較を作る | OpenAIの設定情報 |
| 汚れ、ノイズ、繰り返し模様が出る | 新しいチャット、新しいAPI request、参照画像なし | 汚れていない文脈で一度再現する | ユーザー報告と自分の再現 |
| 画像から画像の編集で劣化する | 参照画像、mask、前の出力、長い会話 | 参照を外すか、きれいなベース画像に戻す | 同じルートでの比較 |
| 大きい画像ほど粗が見える | 目標サイズ、縦横比、元ファイル | 元画像を保存し、実際の表示サイズで見る | サイズ仕様とローカル確認 |
| 特定の入口だけ悪い | ChatGPT、Image API、Responses API、ラッパー | promptとmodelを固定し、入口だけ変える | 同一promptのルート比較 |
停止ラインも先に決めます。元ファイルを保存していない、mediumまたはhighの比較を見ていない、汚れや繰り返し模様をクリーンな文脈で再現していない。その状態では最終素材として承認しません。再現するなら、prompt、model、quality、size、route、時刻、元画像を残します。
「低い品質設定」と「見た目が悪い」を分ける
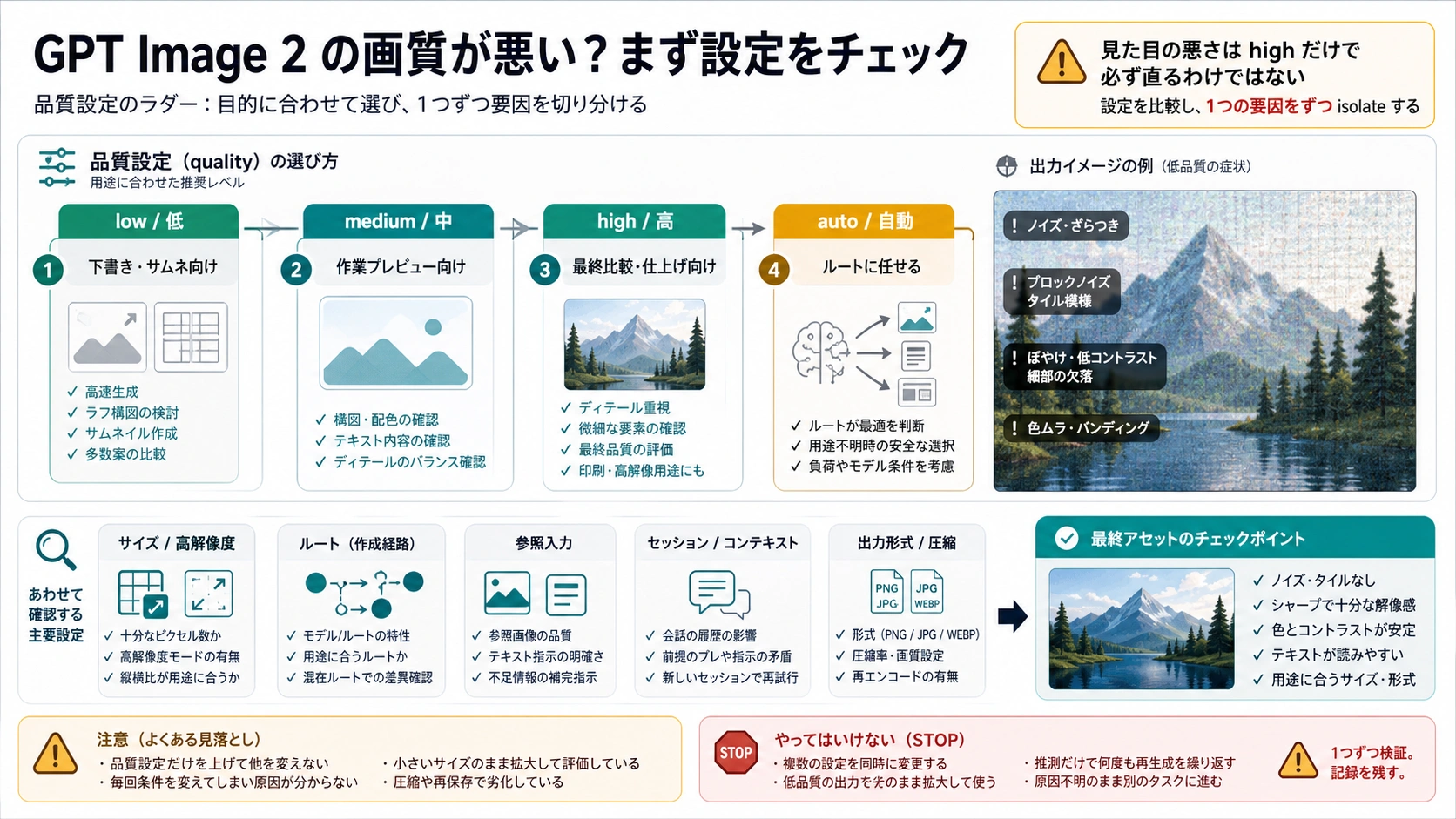
日本語で低画質と言うと、二つの問題が混ざります。一つはAPIやツールの設定としてのlowです。quality: "low"は草案、サムネイル、早い検討のための設定で、最終のバナー、商品画像、ポスター、UIボードをそのまま承認する設定ではありません。
もう一つは、結果の見た目が悪いことです。輪郭がぼやける、質感が汚い、背景に粒状ノイズが残る、同じパターンが敷き詰められる、文字や細部がつぶれる、参照画像の圧縮跡が編集後も残る。この場合、qualityだけを上げても直らないことがあります。
もし実際にlowで生成していたなら、まずそれを草案として扱います。同じprompt、同じsize、同じ参照画像、同じrouteのままmediumを一度作ります。mediumで十分きれいなら、原因は主にquality設定です。mediumでも同じ汚れが出るなら、設定ではなくアーティファクトや文脈の診断に進みます。
最初からmedium、high、autoを使っていた場合も、すぐに「もっと高画質に」「もっと鮮明に」と書き足すのは遅い対応です。size、保存形式、参照画像、編集範囲、長い会話、ツール側の既定値、公開時の圧縮を先に見ます。生成直後は正常で、公開後だけ悪くなることもあります。
quality、size、保存後のファイルを確認する
一番早い確認は、実際に送られた設定を見ることです。Image APIやResponses APIの画像ツールならrequest bodyを記録します。ChatGPTで手作業をしている場合は、少なくとも新しいチャットか、参照画像を使ったか、長い会話の続きか、ダウンロードした元ファイルがあるかを記録します。
sizeはqualityと別の軸です。解像度を上げると、細部が増えるだけでなく、文字、肌、髪、UI罫線、反復模様、反射の粗も見えやすくなります。高解像度だから必ずきれいになるのではなく、高解像度だから失敗が目立つこともあります。
保存後の圧縮も分けます。生成した元画像、CMSに上げた画像、SNSやチャットツールで再圧縮された画像を同じものとして扱わないでください。元画像はきれいなのに公開ファイルだけぼやけるなら、モデルではなく変換、リサイズ、WebP/JPEG設定、CDNのサムネイル処理、CSS表示サイズを直すべきです。
入口が設定を正しく扱っているかも見ます。ChatGPT、Image API、Responses API image tool、外部ラッパーは同じGPT Image 2という名前を出していても、prompt rewrite、既定のquality、入力画像の扱い、圧縮、再試行、後処理が違う場合があります。同じpromptで入口だけを変えないと、比較にはなりません。
チーム作業では、生成設定を素材管理に残すと後の会話が短くなります。誰が、どの入口で、どのqualityとsizeで、元ファイルをどこに置き、公開前に何を変換したのか。これがないと、デザイン側は元画像、開発側は圧縮後の画像、運用側はサムネイルを見て別々の問題を話してしまいます。
新しい文脈で一度だけ再現する
mediumやhighでも悪い場合、次はプロンプトを長くする前に文脈を消します。古い会話、失敗した画像、参照スクリーンショット、途中の修正、不要なスタイル指示は、次の画像に残ることがあります。見た目は「モデルが汚い」のに、原因は前の文脈ということがよくあります。
ChatGPTでは新しいチャットを開きます。何度も失敗した同じスレッドで続けるのではなく、最小限のpromptだけを置きます。同じ内容で新しいチャットのほうがきれいなら、前のスレッドが画質の一部を悪化させていました。以後は旧スレッドで粘らず、新しい文脈へ移します。
APIでは、参照画像なしの新しいrequestを作ります。model、quality、size、核となるpromptだけを残します。その後で参照画像を戻します。参照画像を戻したときだけ汚れるなら、原因はpromptの短さではありません。参照画像のノイズ、圧縮跡、照明、エッジ、mask、不要な画風が引き継がれています。

外部ラッパーでは、可能なら直接扱えるルートと比較します。prompt、model、quality、size、縦横比を固定し、入口だけ変えます。ラッパーだけ悪いなら、その入口の既定値、圧縮、モデルマッピング、prompt改変、後処理の証拠です。GPT Image 2全体の証拠ではありません。
クリーンな再現は、修正よりも先に価値があります。同じprompt、参照画像なし、model: "gpt-image-2"、quality、size、route、時刻、元ファイル。これだけ残れば、設定変更、ルート比較、サポートへの報告、次の検証が具体的になります。
同じスレッドを使わざるを得ない場合も、まず範囲を小さくします。参照画像を外し、構図変更と文字修正と高解像度化を同時に頼まない。主体と背景だけを確認し、質感が戻るかを見る。この確認は完成品を作る作業ではなく、古い文脈が影響しているかを見る作業です。
汚れ、ノイズ、繰り返し模様が残る場合
GPT Image 2の出力について、汚れた質感、同じ模様、灰色の膜、圧縮されたようなノイズ、画像から画像への編集劣化が語られることがあります。OpenAIが特定の原因を説明していない限り、それは報告されている症状として扱います。公式に確認されたモデル全体の不具合とは書かないほうが安全です。
見るべきなのは、どこで症状が出るかです。参照画像を使った編集だけで出るなら、ベース画像とmaskを疑います。公開後だけで出るなら、元画像と圧縮後の画像を比べます。大きいサイズだけで出るなら、小さめのmasterを承認してから、ネイティブ高解像度、アップスケール、別ルートを選びます。
| 症状 | 先にすること | まだしないこと |
|---|---|---|
| 無関係なpromptでも灰色の膜が出る | 新しいmedium生成、参照画像なし | prompt集に頼る |
| 特定の編集で模様が敷かれる | 参照画像やmaskを替える | 汚れたベース画像を編集し続ける |
| 公開後だけぼやける | 元ファイルと公開ファイルを比較 | 先にモデルを疑う |
| 大きいサイズだけ粗い | 小さいmasterで構図を承認 | ネイティブ4Kを最初から前提にする |
| 一つの入口だけ悪い | 同じpromptで別ルートを比較 | 入口の問題をモデル全体の問題にする |
すべての失敗を低画質と呼ばないことも重要です。手の形、文字の誤り、構図のずれ、ブランド色、余計な物体はprompt制御や編集範囲の問題です。ノイズ、圧縮ブロック、繰り返し模様、汚れた膜、参照画像の残りは画質診断に寄せます。症状名が違えば、次の修正も違います。
ChatGPT、Image API、Responses API、外部ラッパーを分ける
ChatGPTは手作業の探索に向いています。少ない枚数を比べる、参照画像を軽く試す、方向性を見るには便利です。ただし底のパラメータは見えにくいので、新しいチャット、短いprompt、きれいな参照画像、元ファイル保存、手動比較が中心になります。
Image APIは開発者の診断に向いています。gpt-image-2、quality、size、input image、保存ファイルを明示でき、再現しやすいからです。パラメータを一つだけ変える検証も組みやすくなります。
Responses API image toolは、画像生成をアシスタントの一連の流れに入れるときに便利です。ただし品質調査では、周囲のassistantがpromptを書き換えたり、前の会話を加えたり、tool optionを自動で選んだりする可能性があります。問題が出たら、最小のimage callに落として確認します。
外部ラッパーは、ルート情報が見えるときだけ比較対象にします。model mapping、quality対応、size対応、圧縮、prompt rewrite、再試行、後処理を確認してください。見えない場合、その結果はラッパーの評価であって、第一方モデルの評価ではありません。
診断後に本当にモデルを変えるか判断するなら、GPT Image 2 vs Nano Banana Proでルートを比べます。費用や提供入口が問題なら、GPT Image 2 APIの低コストルートに分けます。低画質の切り分けと、モデル選定や料金判断は混ぜないほうが判断が速くなります。
高解像度は万能の修正ではない
低画質に見えると、すぐ4Kやアップスケールに寄せたくなります。しかし解像度、quality、ファイル圧縮は別のレイヤーです。大きくすると見えなかった失敗が見えることもあります。UIボード、細い文字、商品エッジ、髪、布、反射、繰り返し模様は特にそうです。
ネイティブ高解像度が不安定なら、まず小さめのmasterをmediumまたはhighで作ります。構図、主体、光、文字、主要な質感を確認してから、ネイティブ高解像度、アップスケール、別のproduction routeを決めます。最初から大きくして失敗を繰り返すと、コストも時間も増えます。
サイズや4Kそのものが主題なら、GPT Image 2の4Kサイズ確認に進んでください。低画質の診断では、同じ欠陥が大きいサイズだけで出るのか、どのサイズでも出るのかを見ます。後者なら、resolutionよりroute、context、reference、exportを疑います。
最終確認は実際の利用場所で行います。スマホの小さなpreviewで良く見えても、LPのhero、広告素材、ストア画像、印刷、アプリ画面では粗が出ることがあります。用途のサイズで見て、初めて承認判断ができます。
公開前の受け入れチェック
最後の確認は、派手なpromptではなく、単純なチェックリストです。
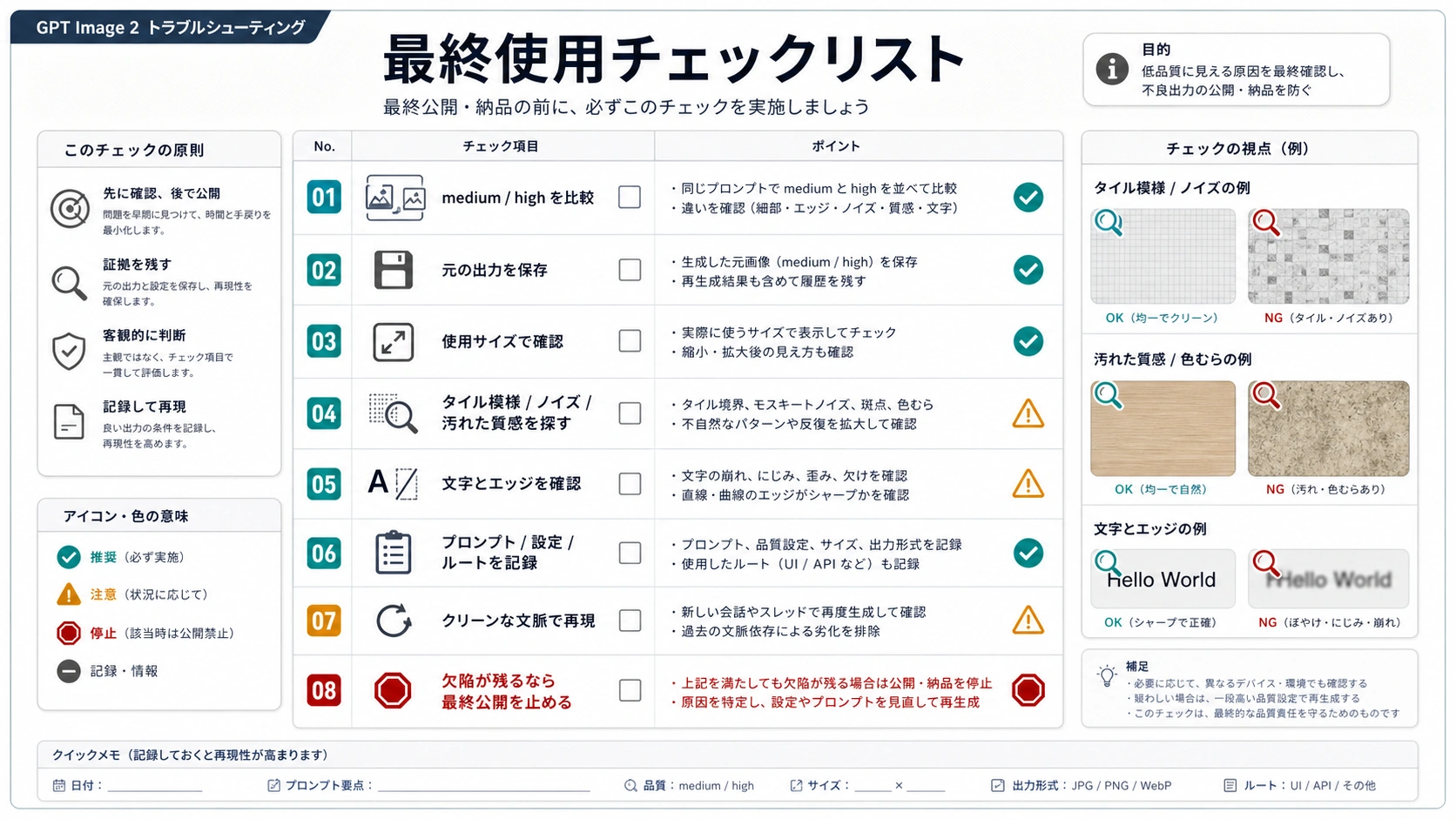
| チェック | 合格条件 |
|---|---|
| 元ファイルを保存 | 圧縮、アップロード、CMS変換前のoriginalがある |
| 設定を記録 | model、route、quality、size、参照画像、編集状態が分かる |
| medium/highを比較 | 最終承認前にnon-low出力を見ている |
| 目標サイズで確認 | 実際の表示または印刷サイズで見ている |
| アーティファクトを確認 | ノイズ、汚れ、繰り返し模様、エッジ、文字を見ている |
| クリーン再現を試行 | 持続する欠陥を新しいチャットまたはAPI requestで確認している |
| 停止ラインを適用 | クリーン再現で壊れる素材をfinalにしない |
この手順は面倒な儀式ではありません。汚れた文脈で生成を繰り返すことと、小さいpreviewだけで公開してしまうことを防ぎます。どちらも後で直すほうが高くつきます。
早すぎる結論を避ける
一つの入口で悪い画像が出ただけで、GPT Image 2が全体的に壊れているとは言えません。まず制御できる変数を見ます。quality、size、参照画像、会話履歴、Image API、Responses API、ラッパー、保存後の圧縮、高解像度分岐。このどれかを一つずつ切り分けます。
quality: "high"も万能ではありません。最終比較には使うべきですが、参照画像の汚れ、長いチャット、圧縮、入口側の後処理までは消せません。
無料ツールや外部サービスの一枚で、公式ルートが良いか悪いかを決めないでください。無料体験、ブラウザ上のテスト、API課金、プロバイダのクレジット、ログイン不要の生成は別の条件です。無料または無制限の入口は GPT Image 2無料ルート、公式APIの無料枠は GPT Image 2 API無料枠 に分けて確認します。
FAQ
quality: "low"が低画質の原因になりますか?
なります。lowは草案、サムネイル、早い比較向けです。最終素材ではmediumまたはhighを比較してください。medium/highでもクリーンな文脈で汚れや繰り返し模様が残るなら、別の診断です。
いつもhighを使えばいいですか?
いいえ。初期案はlow、作業用previewはmedium、最終比較や高価値素材はhighが自然です。問題が参照画像、会話履歴、圧縮、ラッパー設定にある場合、highだけでは直りません。
新しいチャットで良くなるのはなぜですか?
古い指示、失敗画像、参照画像、修正履歴、不要なスタイル文脈が消えるからです。同じpromptで新しいチャットのほうがきれいなら、古い会話が品質に影響していました。
汚れ、ノイズ、繰り返し模様はどう扱うべきですか?
まず報告されているアーティファクト症状として扱います。参照画像を外し、新しいチャットまたは新しいAPI requestでmedium/highを比較し、元ファイルを保存します。第一方の説明がない限り、公式なモデル全体の原因とは書きません。
4Kにすれば直りますか?
直る場合もありますが、悪化して見える場合もあります。高解像度は文字、エッジ、繰り返し模様、肌や髪の失敗を見えやすくします。まず小さめのmasterを承認し、その後で4Kやアップスケールを決めます。
Image APIはChatGPTより診断しやすいですか?
開発者の診断では、はい。Image APIはmodel、quality、size、入力画像、出力ファイルを記録しやすいです。ChatGPTは探索には便利ですが、内部設定や会話文脈が完全には見えません。
品質問題を報告する前に何を保存しますか?
元画像、prompt、model label、route、quality、size、参照画像、mask、時刻、新しいチャットまたは新しいAPI requestで再現したかを保存します。複数回書き換えた後のスクリーンショットだけでは弱いです。