2026年7月2日時点で、OpenAI direct の Standard 価格における o4-mini は、入力 100万トークンあたり $1.10、キャッシュ入力 100万トークンあたり $0.275、出力 100万トークンあたり $4.40 です。ただし実際の請求はこの三つだけでは決まりません。見えない推論トークンは出力として課金され、Batch や Flex は別の運用条件を持ち、新しい reasoning ワークロードでは GPT-5.x 系との比較が必要です。
| 知りたいこと | 最初に見る行 | 実務上の意味 |
|---|---|---|
| 通常の direct API 費用 | Standard: 入力 $1.10 / キャッシュ $0.275 / 出力 $4.40 | 同期推論の基本見積もりに使う。 |
| 非同期の大量処理 | Batch: 入力 $0.55 / 出力 $2.20 | 24時間枠を受け入れられる処理だけに使う。 |
| 低優先度のオンライン処理 | Flex: 入力 $0.55 / キャッシュ $0.138 / 出力 $2.20 | 利用可能性と運用条件を確認するサービス tier。 |
| 優先処理 | Priority: 入力 $2.00 / キャッシュ $0.50 / 出力 $8.00 | 通常見積もりに混ぜない高コスト行。 |
| 似た名前の別契約 | Deep Research、fine-tuning、Azure、provider | base o4-mini とは別に管理する。 |
o4-mini を安いと判断する前に、新規入力、キャッシュ入力、可視出力、推論トークンを分けて見積もります。既存 eval で勝っている lane は維持できます。新規 reasoning は GPT-5.4 mini や GPT-5.5 と比較し、抽出・分類・整形・ルーティングは非推論モデルを先に試します。
現在の o4-mini の位置づけ
OpenAI のモデルページでは、o4-mini は reasoning モデルとして掲載され、モデル ID は o4-mini、スナップショットは o4-mini-2025-04-16 です。高速で比較的安い reasoning、coding、visual task 向けの位置づけですが、後継モデルも明記されています。つまり、新規開発の既定値ではなく、検証済み用途で使う候補として読むのが安全です。
日本語の情報では o4-mini と GPT-4o mini、GPT-5 mini、GPT-5.4 mini、o4-mini-deep-research が混ざりやすいです。名前が似ていても価格行も性能前提も違います。コード、ログ、ダッシュボード、見積もりシートには正確な model ID を残すべきです。
価格だけでモデルを残すか決めると失敗します。品質、再試行、出力長、推論トークン、レイテンシ、修正コストまで含めた一つのワークフロー費用を見る必要があります。小さい単価のモデルでも、失敗率が高ければ総額は上がります。
日本語では「トークン」と「token」の両方が使われますが、本文では概念を揃えておくとチーム内の見積もりがずれません。
GPT-4o mini の安い価格と o4-mini の reasoning 価格は別物です。比較表では model family を先に分けてください。
使用ログに reasoning tokens が出ない形で集計していると、短い回答が高くついた理由を説明できません。
本番で o4-mini を残すなら、価格表とは別に request class、平均新規入力、キャッシュ率、可視出力、推論トークン、retry rate、人手修正率を記録します。単価が低くても、推論が長い、再試行が多い、出力が長い、という理由で総額が上がるからです。
eval set は三つに分けると判断しやすくなります。既存の安定タスクは o4-mini を維持できるかを見るため、境界の難しいタスクは GPT-5.5 へ上げるべきかを見るため、推論不要の負例は非推論モデルへ逃がせる範囲を確認するために使います。
費用説明では、OpenAI direct の token 行、Batch/Flex/Priority の運用 route、Azure や provider の調達条件、ChatGPT subscription を分けてください。これらを同じ列に入れると、モデル選択の問題なのか、支払い経路の問題なのか、prompt 設計の問題なのかが判断できなくなります。
運用後のアラートは、reasoning tokens の割合が急に上がることと、cached input の割合が急に下がることを見ます。前者は task complexity や prompt 失敗のサイン、後者は安定 prefix や schema 配置が壊れたサインになりやすいです。
移行実験は平均費用だけで見ない方が安全です。長い context、短い output、tool call、retry が多いケース、cache hit が高いケースを分けて測ります。o4-mini は全体平均では負けても、特定 lane ではまだ最も安定していることがあります。
月次の振り返りでは失敗した呼び出しも費用に入れます。成功した最終回答だけを見ると、retry に隠れた入力、出力、推論トークンが消えます。推論モデルでは失敗呼び出しも十分に高くつくため、成功回答ベースの見積もりは保守的ではありません。
新モデルへ置き換える条件は、同じ eval set で品質が落ちないこと、retry rate が増えないこと、reasoning tokens の平均と p95 が説明できること、latency が許容内であること、月次費用または失敗率が改善すること、といった測定可能な形にします。
古い lane を削除するときも、評価点数、代表的な失敗例、費用分布、代替モデルが勝った理由、切り替え日を残します。後で費用や品質が揺れたとき、原因がモデル移行なのか、traffic mix や prompt 変更なのかを切り分けられます。
キャッシュの振り返りも残します。どの prefix が安定しているか、どの schema を動かしてはいけないか、どの動的フィールドを後ろへ送るかを書いておくと、prompt の小さな整理で cached input の利点を失う事故を避けられます。
費用の帰属は request class ごとに行います。coding repair、短い分類、長い policy 付き判定、visual reasoning、tool routing は、同じ o4-mini でも入力構造と失敗率が違います。合算平均だけを見ると、どの用途を別モデルへ移すべきか判断できません。
eval の結果は価格表と同じ場所に置かない方が読みやすくなります。価格表は事実、eval は自社環境の観測、router は運用方針です。三つを分けておけば、公式価格が変わったときも、モデル品質が変わったときも、変更すべき層をすぐ見つけられます。
公式の o4-mini 価格行

価格ページは official direct の出発点です。Standard、Batch、Flex、Priority を分け、Deep Research、fine-tuning、Azure、外部 provider は別契約として扱います。
| ルート | 入力 / 1M | キャッシュ入力 / 1M | 出力 / 1M |
|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 |
Batch o4-mini | $0.55 | 個別行なし | $2.20 |
Flex o4-mini | $0.55 | $0.138 | $2.20 |
Priority o4-mini | $2.00 | $0.50 | $8.00 |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 |
実際のリクエスト費用を見積もる

hljs textcost = new_input / 1,000,000 * 1.10 + cached_input / 1,000,000 * 0.275 + (visible_output + reasoning_tokens) / 1,000,000 * 4.40
Standard の計算は、新規入力を $1.10、キャッシュ入力を $0.275、可視出力と推論トークンの合計を $4.40 で 100万単位に割って足します。推論トークンは表示されませんが、出力側として課金され、context budget も消費します。
例として 10,000 新規入力、0 キャッシュ、2,000 可視出力、3,000 推論トークンなら、入力は $0.011、出力側は $0.022、合計は約 $0.033 です。短い回答でも hidden reasoning が増えれば、月次費用に大きく影響します。
長い prompt ではキャッシュの効果が大きくなります。80,000 入力のうち 60,000 がキャッシュなら、新規入力は 20,000 だけです。しかし 5,000 可視出力と 10,000 推論トークンは出力側単価で計算します。キャッシュは強いですが、推論の暴走までは救いません。
o4-mini を使い続ける場面
o4-mini は、既に eval で合格している lane に向いています。コードレビューの補助、短い論理判定、数学チェック、画像を含む軽量推論、router の二段目判断など、出力範囲が管理できる場面では十分に実用的です。
維持する場合も、再評価は必要です。正答率、レイテンシ、可視出力、推論トークン、retry rate、手直し率、下流エラーを比較します。単価が安いモデルが、長い推論と再試行で高くなることは珍しくありません。
本番 router では、o4-mini を限定された lane として扱うのが堅いです。難しい計画や複雑な修正は GPT-5.5、低コスト reasoning は GPT-5.4 mini との比較、抽出や整形は非推論モデルへ分けます。
モデルを切り替える場面
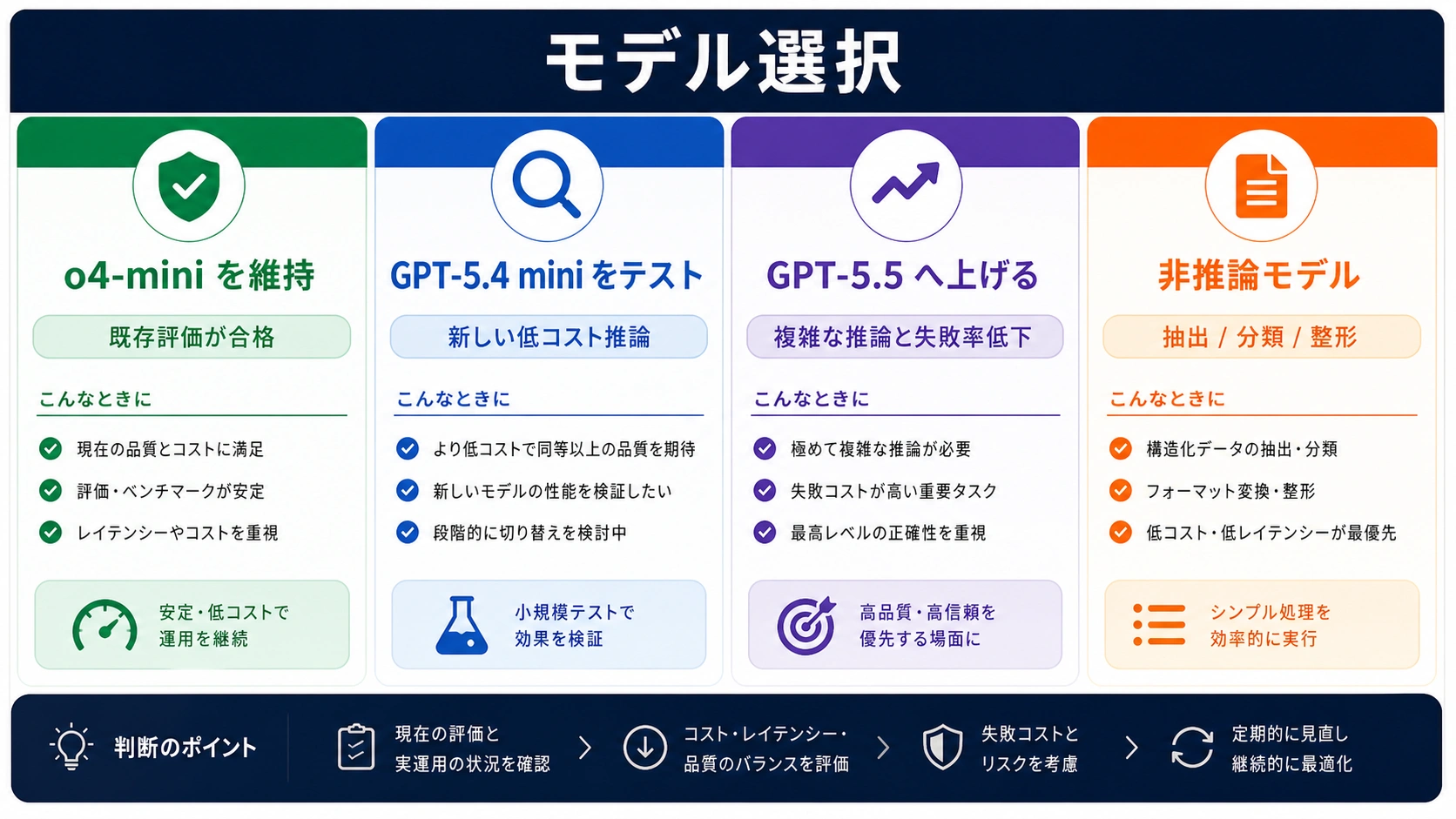
新規 reasoning 機能では、現在の GPT-5.x 系の候補を先に比較します。GPT-5.4 mini は低コスト reasoning の比較軸、GPT-5.5 は複雑さと失敗率を下げる候補です。o4-mini は既存基準として残せますが、最初から勝者にしない方が安全です。
抽出、分類、JSON 整形、メタデータ補正、router prefilter は reasoning を必要としないことがあります。その場合、安い非推論モデルの方が費用も挙動も読みやすくなります。
| ワークロード | 最初に試すモデル | 理由 |
|---|---|---|
既存の o4-mini lane が eval 合格 | o4-mini を維持して再評価 | 既存基準を残しながら比較できる。 |
| 新しい低コスト reasoning | GPT-5.4 mini と o4-mini | 新モデルが quality per dollar で勝つ可能性がある。 |
| 複雑な計画やコード修復 | GPT-5.5 | 再試行削減が費用を回収することがある。 |
| 抽出、分類、整形、ルーティング | 非推論モデル | 推論トークンが価値を足さない場合が多い。 |
効くコスト制御
Prompt caching は最初に見るべきコスト制御です。安定した system instruction、schema、policy、長い reference block を前に置き、リクエストごとに変わる内容を後ろへ移します。
max_output_tokens は可視テキストだけの上限ではありません。推論モデルでは reasoning と visible output の合計に効きます。低すぎると答えが出る前に止まり、高すぎると hidden output cost が増えます。
Batch は非同期にできる処理のコストを下げます。Flex は低優先度で許容できる処理に限ります。Priority は高くなるので、通常見積もりの列とは分けるべきです。
429 や quota が問題なら OpenAI API rate limit ガイド を先に見ます。key、billing、trial state が問題なら OpenAI API key free trial ガイド から確認します。
避けたい誤読
fine-tuning/RFT の行を base inference として使わないでください。training hour、tuned-model inference、data-sharing 条件は別です。
o4-mini-deep-research を通常の o4-mini として読まないでください。似た名前でも用途と価格が違います。
Azure や provider 価格を OpenAI direct 価格として貼り付けないでください。地域、契約、deployment、サポート、通貨換算が異なります。
可視出力だけで見積もらないでください。推論トークンは見えなくても出力として課金されます。
本番前チェックリスト
- コードとログの model ID が
o4-miniであることを確認する。 - 通常 direct は Standard 行で見積もり、Batch/Flex/Priority は別列にする。
- 新規入力とキャッシュ入力を分ける。
- 可視出力と推論トークンを足して出力側単価をかける。
- GPT-5.4 mini、GPT-5.5、非推論モデルを同じ eval set で比較する。
- rate limit が問題なら OpenAI API rate limit、key や billing が問題なら API key free trial の手順を確認する。
よくある質問
o4-mini API の現在価格は?
2026年7月2日時点の OpenAI direct Standard は、入力 $1.10、キャッシュ入力 $0.275、出力 $4.40 / 100万トークンです。
推論トークンは課金されますか?
はい。見えない推論トークンは output tokens として課金されます。
キャッシュ入力は二重計算ですか?
いいえ。現在の入力のうち再利用できる前方部分が cached rate で計算されるだけです。
Batch は安いですか?
単価は低いですが非同期処理です。リアルタイム UI には向きません。
Flex と Batch は同じですか?
違います。Flex は低優先度 service tier、Batch は async route です。
o4-mini は deprecated ですか?
文書では掲載が続き、後継も示されています。新規用途は比較が必要ですが、検証済み lane を即削除する意味ではありません。
GPT-5.4 mini とどちらを使うべきですか?
低コスト reasoning なら同じ eval で比較します。新規なら GPT-5.4 mini を先に試す価値があります。
月額費用はどう見積もりますか?
一回の fresh input、cached input、visible output、reasoning tokens を計算し、volume、retry、route share と合わせます。