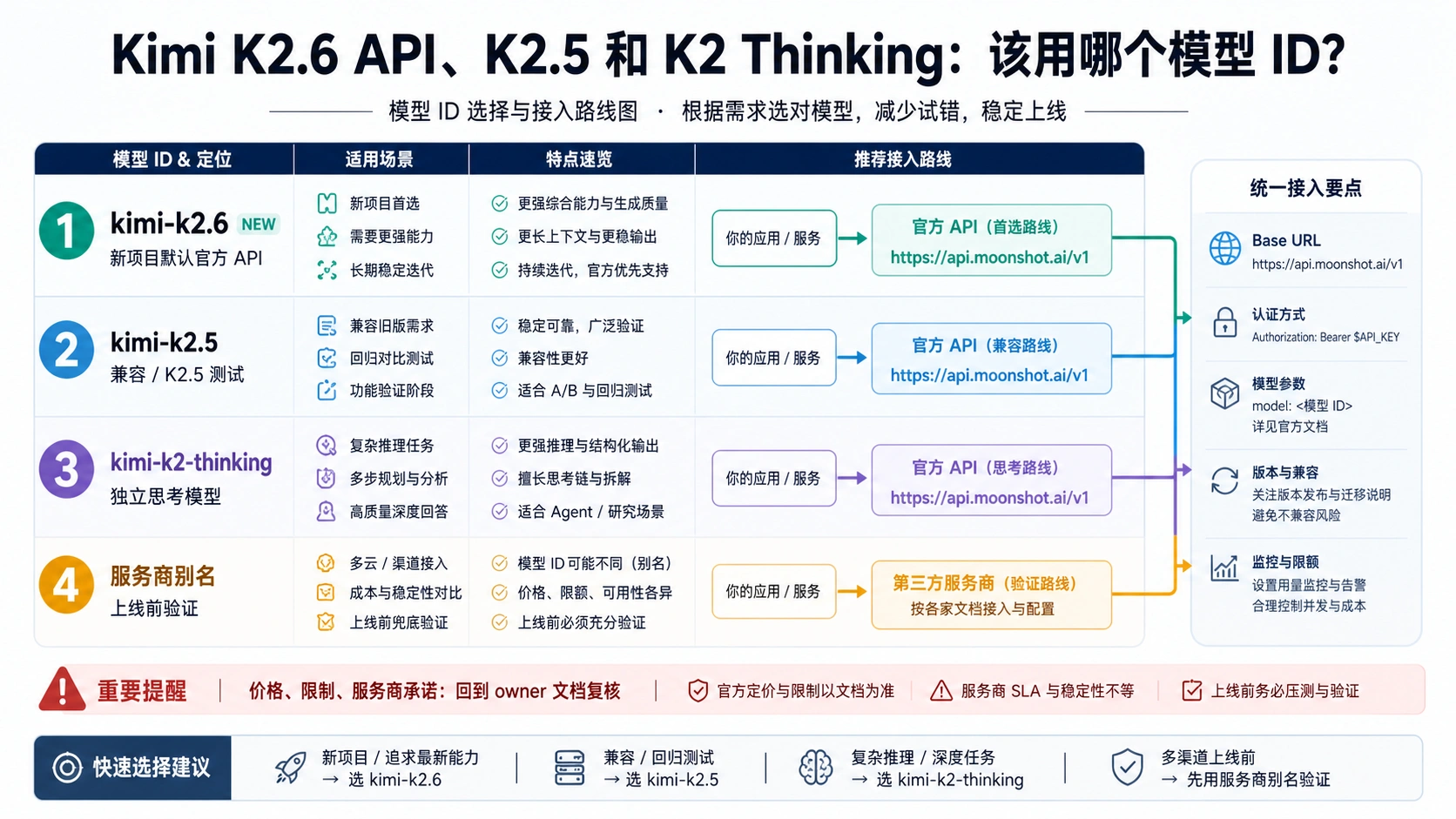
新接官方 Kimi API 时,第一行代码优先写 kimi-k2.6。只有在你要复现实验、保留旧评测、验证 K2.5 行为时,才继续使用 kimi-k2.5;只有在你明确需要旧的专用 thinking 模型时,才把 kimi-k2-thinking 放进 model 字段。第三方平台、云厂商接入口、视频里的免费 API 教程和社区别名可以作为线索,但它们不能替代 Kimi/Moonshot 官方模型列表。
中文开发者最容易混在一起的不是“有没有 API”,而是三个问题:当前官方模型 ID 是什么;Thinking 到底是一个模型名,还是请求里的推理行为;某个 provider 页面写的别名是否等于官方模型。生产代码要先把这三个问题拆开,否则团队会把一个能跑通的演示误当成长期 API 合同。

| 你的真实需求 | 优先使用 | 为什么 | 上线前必须复核 |
|---|---|---|---|
| 新建官方 Kimi API 集成 | kimi-k2.6 | 官方 K2.6 快速开始使用的当前模型 ID | 模型列表、价格、上下文、账号额度和参数行为 |
| 保留 K2.5 对比或兼容测试 | kimi-k2.5 | K2.5 仍是独立模型,不是 K2.6 的拼写错误 | 这个测试是否真的依赖 K2.5 行为 |
| 调用旧的专用 thinking 模型 | kimi-k2-thinking | 这是独立模型 ID,不是 K2.6 的 thinking 开关 | reasoning 输出、工具调用字段和 max tokens |
| 试第三方或免费入口 | provider 自己的别名 | 只能证明该入口提供了某种路由 | 价格、限制、模型身份、数据条款和免费证明 |
先决定模型 ID,而不是先找“最新版 K2”
Kimi K2 系列的公开名称很容易让人误读。Kimi K2.6 API 像是一个产品入口,Kimi K2.5 像是旧版本,Kimi K2 Thinking 又像是推理增强模式。可是 API 请求不会接受一个模糊家族名。它要的是精确模型字符串、base URL、账号权限、请求参数和响应字段。
对新的官方 API 项目来说,最干净的默认值是 kimi-k2.6,官方 K2.6 quickstart 走的是 OpenAI 兼容客户端形态,base URL 为 https://api.moonshot.ai/v1。这并不意味着仓库里所有 K2 字符串都要一键替换;它只说明“新项目想调用当前官方 Kimi 模型”时,不应该从旧字符串开始。
kimi-k2.5 的意义在于兼容和对照。比如你已有一套 K2.5 评测基线、需要和旧结果保持可比、或者 provider 尚未给出 K2.6 对应路线,那么 K2.5 仍然可以保留。它不是“错了的 K2.6”,而是另一条明确路线。问题在于,很多项目没有写清楚为什么还用 K2.5,最后让默认模型停留在旧配置里。
kimi-k2-thinking 又是第三条路线。它是专用模型 ID,不能随手写成 kimi-k2.6-thinking,也不能把 K2.6 的 thinking 行为等同于这个旧模型名。只要代码里出现 thinking,文档就应该说明这是模型 ID、请求参数、还是响应处理逻辑。
官方 API 路线是模型身份的责任方
如果你要写生产文档、预算表、SDK 示例或内部 runbook,模型身份先回到官方 API。第三方页面可以帮助发现入口,但它们不负责 Kimi 官方模型列表、价格、上下文窗口、参数支持和长期可用性。
一个最小调用应该把路线暴露出来:
hljs tsimport OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.KIMI_API_KEY,
baseURL: "https://api.moonshot.ai/v1",
});
const response = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Summarize the routing risk in this Kimi setup." },
],
});
console.log(response.choices[0]?.message);
这个示例故意保持很小。先证明账号、key、base URL 和模型 ID 在官方路线能工作,再加入工具调用、多模态输入、长上下文、代理封装或 provider 转发。这样一来,如果同样请求在第三方平台失败,你能判断故障属于官方模型合同,还是 provider 的别名、账单、限流、功能封装或区域策略。
截至 2026 年 5 月 8 日,官方平台把 K2.6 与 K2.5 都列为 256K 上下文多模态模型,并显示 K2.6 价格为 cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok,K2.5 价格为 cache hit $0.10/MTok、input $0.60/MTok、output $3.00/MTok。这些是带日期的路线责任方事实,不应写成永远有效。任何影响预算、合同或对外宣传的价格、额度、上下文和可用性,都要在使用当天重新确认。
不要把 K2 Thinking 和 thinking 模式混为一谈

处理 Kimi K2 Thinking 时,开发者常常真正想问的是“我该填哪个模型 ID,才能得到推理能力”。这里必须分两层看:
| 层级 | 它是什么 | 对代码有什么影响 |
|---|---|---|
kimi-k2-thinking | 一个旧的专用 K2 thinking 模型 ID | 需要在 model 字段中明确选择 |
| K2.6 / K2.5 的 thinking 行为 | 当前模型路线上的请求与响应处理问题 | 需要正确处理 reasoning 内容、工具调用和 token 预算 |
thinking 指南的重要性不只是告诉你“模型会思考”。更实际的地方在于响应可能包含 reasoning_content,工具调用链路可能要求把 reasoning 内容保留下来,流式输出、temperature 建议和 max token 设置也会改变调试结果。如果你的 wrapper 会丢掉非标准字段、压缩中间消息,或者在下一轮工具调用前没有回放必要字段,模型看起来就会比实际能力弱。
所以,生产代码不要只问“Thinking 是否更强”。更好的问题是:当前调用的模型 ID 是什么;thinking 行为是关闭、开启、默认还是专用模型;客户端是否保留 reasoning 字段;工具调用消息是否按官方指南回放;max token 是否足够支撑推理路线。把这些写清楚,比在标题里堆 K2 Thinking 更有价值。
这也是为什么 provider 页面里的新别名要谨慎。有些页面会把 thinking 作为模型名的一部分,有些会把它做成平台选项,有些只是教程作者的表达。只要它不是官方模型列表中的字符串,就不能直接写进官方路线代码。
旧 K2 字符串需要迁移规则,不需要一刀切替换
官方模型列表对旧 kimi-k2 系列有 retirement note,但这条信息不能被过度解释。旧 kimi-k2-* 字符串需要检查,并不等于 K2.5 或 K2.6 不存在;也不等于所有历史配置都应该机械替换成 K2.6。
更稳的迁移方式是先扫位置,再判断意图:
| 检查位置 | 要找什么 | 推荐动作 |
|---|---|---|
| 环境变量 | KIMI_MODEL、MODEL_ID、provider alias | 先确认路线责任方,再替换 |
| SDK wrapper | 默认模型和隐藏 fallback | 把默认模型显式化,并记录日志 |
| 评测脚本 | K2.5、K2 Thinking benchmark label | 若测试依赖旧行为,则保留并标注原因 |
| provider 配置 | 平台自己的别名或模型路径 | 单独映射,不要当成官方 ID |
| 文档示例 | “latest K2”“K2 API”这类模糊说法 | 改成精确模型字符串和检查日期 |
这套规则的核心是“新官方集成默认 K2.6,已有测试保留意图,旧字符串做路线核对”。如果你只做全局替换,可能会破坏历史评测;如果你完全不动,可能让新功能继续使用已经不该默认使用的模型。迁移应该让每一条 K2 字符串都有理由,而不是让代码继续继承模糊配置。
第三方和免费 API 说法只能按入口验证

第三方 provider 不是没有价值。它们可能提供更熟悉的控制台、边缘运行环境、统一账单、OpenAI 兼容端点、低门槛试用、区域可用性或现成示例。问题是,provider 能证明“这个平台给了一个入口”,不能自动证明“官方 Kimi API 合同就是这样”。
验证时至少分六层:
| 说法 | 应该看谁 | 为什么 |
|---|---|---|
| 模型身份 | provider 文档加官方 Kimi 文档 | provider alias 不一定等于官方 model ID |
| 价格和账单 | provider 自己的价格页 | 单价、赠金、最低消费和计费方可能不同 |
| 上下文与限制 | provider model card 或 dashboard | 托管路线可能有不同 practical limit |
| 工具、视觉、JSON、流式 | provider capability docs | 功能封装可能和官方路线不一致 |
| 数据政策 | provider 条款和产品文档 | 官方模型身份不回答数据处理问题 |
| 免费 API | route owner 的当前页面 | 免费、无限、不封号、稳定承诺变化很快 |
如果视频标题说“免费 Kimi K2.6 API”,把它当作待验证线索,而不是证据。如果某个平台把模型写成自己的路径或别名,你可以在平台代码里使用它,但内部文档仍应写清楚它意图映射到哪个官方模型、哪些事实属于平台、哪些事实属于 Kimi/Moonshot。
生产环境最忌讳的是把“我能在一个教程里跑通”改写成“官方长期保证免费可用”。免费额度、限速、模型覆盖、失败是否扣费、稳定性、退款和账号风险都属于会变化的 claims。没有当前路线责任方证据,就不要写进正文、销售材料或客户承诺。
Kimi 能否替代 Claude 是另一个问题
很多人评估 K2.6,是因为看到它被拿来和 Claude Code、Opus 或其他代码工作流比较。这是合理的兴趣,但不是同一个决策。模型 ID 路线只回答“我要调用哪个 Kimi 模型字符串、走哪个 API owner、怎么处理 thinking 和 provider 别名”。替代 Claude 的问题还要比较代码代理能力、工具调用、延迟、失败恢复、仓库理解、成本、评测集和实际工作流。
边界可以这样写:
- 选择 Kimi 模型字符串时,先使用模型 ID 路线表。
- 判断 Kimi 是否能替代 Claude 工作流时,单独做同题 benchmark。
- 使用 provider 时,先确认 provider route,再比较模型能力。
- 写生产文档时,同时写官方模型 ID 和 route owner。
这条边界能避免一个常见捷径:因为看到 benchmark 热度,就把代码里的模型字符串换成一个还没验证过的别名。对 API 集成来说,路由正确性先于舆论热度。
上线前把核对表写进仓库
Kimi K2 系列不是一次性选择。更可靠的做法是把模型 ID、route owner、检查日期和停止规则写进仓库或 runbook,让后续维护者知道当前配置为什么存在。
| 字段 | 好的生产记录 |
|---|---|
| 官方目标模型 | kimi-k2.6、kimi-k2.5 或 kimi-k2-thinking,并写明理由 |
| API owner | Kimi/Moonshot 官方 API,或具体 provider route |
| Base URL | 官方 https://api.moonshot.ai/v1,或 provider endpoint |
| 检查日期 | 模型列表、价格、上下文和额度的检查日期 |
| Thinking 行为 | off、on、default,或专用模型路线 |
| Reasoning 处理 | 客户端是否保留 reasoning_content |
| Provider caveat | 别名、账单、限制、能力和数据条款 |
| 停止规则 | 没有 route-owner 证据,不写免费、无限、保证、稳定性和不封号承诺 |
这张表看起来很朴素,但它能避免最贵的隐性错误:上线几周后没人知道当前模型是因为官方推荐、历史兼容、provider 限制,还是某个教程复制过来的默认值。
FAQ
现在新项目是不是直接用 kimi-k2.6?
如果你走官方 Kimi API,并且没有明确的 K2.5 兼容、旧 thinking 模型或 provider alias 需求,答案是是。新项目先从 kimi-k2.6 开始,然后再按价格、上下文、额度和参数行为复核。
kimi-k2-thinking 等于 K2.6 的 thinking 模式吗?
不等于。kimi-k2-thinking 是独立模型 ID。K2.6 或 K2.5 的 thinking 行为要看当前请求设置和响应处理,不应该凭想象拼出新的模型名。
Kimi K2.5 还值得测试吗?
值得,但前提是测试需要 K2.5 行为、历史基线或 provider 兼容。它不应该成为新官方 API 集成的默认值,除非你能写清楚为什么不用 K2.6。
免费 Kimi K2.6 API 能用于生产吗?
只有在 route owner 清楚证明免费范围、限制、数据条款、模型身份和可用性时,才可以低风险试用。没有当前证据时,不要把免费、无限、不封号、退款、稳定性或保证类说法写进生产承诺。
旧的 kimi-k2 配置应该怎么处理?
检查环境变量、SDK wrapper、评测脚本、provider 配置和文档示例。每个旧字符串都先判断意图:新官方路线改到 K2.6;K2.5 评测保留;专用 thinking 路线保留 kimi-k2-thinking;provider 别名单独映射并写明 owner。