截至 2026 年 7 月 2 日,OpenAI 直连 Standard 路由下的 o4-mini 价格是每 100 万输入 token 1.10 美元、每 100 万缓存输入 token 0.275 美元、每 100 万输出 token 4.40 美元。这个数字只是估算起点,因为隐藏推理 token 也按输出计费,Batch、Flex、Priority 会改变路由价格,而新的 GPT-5.x 推理模型已经成为很多新工作负载的优先测试对象。
| 你要判断什么 | 先看哪一行 | 实际含义 |
|---|---|---|
| 普通直连接口成本 | Standard: $1.10 输入 / $0.275 缓存输入 / $4.40 输出 | 用于同步调用和常规预算表。 |
| 可异步处理的批量任务 | Batch: $0.55 输入 / $2.20 输出 | 适合离线评测、回填、批量分类,不适合实时聊天。 |
| 低优先级在线任务 | Flex: $0.55 输入 / $0.138 缓存输入 / $2.20 输出 | 是服务层选择,不是所有账户和场景的默认价格。 |
| 高优先级处理 | Priority: $2.00 输入 / $0.50 缓存输入 / $8.00 输出 | 不要把这一行当作普通 Standard 价格。 |
| 名字相近的高价行 | Deep Research、微调、Azure、第三方 provider | 这些是不同合同,不能混进 OpenAI direct 估算。 |
停止规则很简单:先把新输入、缓存输入、可见输出和隐藏推理 token 分开估算,再决定 o4-mini 是否真的便宜。已有评测通过的旧路由可以保留;新推理任务应并测 GPT-5.4 mini 或 GPT-5.5;抽取、分类、格式化和路由任务应先尝试更便宜的非推理模型。
现在的 o4-mini 是什么
OpenAI 模型文档仍然列出 o4-mini,模型 ID 是 o4-mini,快照是 o4-mini-2025-04-16。它属于推理模型,定位是速度快、成本相对低,适合编码、数学、视觉推理和需要短链路推理的任务。但同一页也说明它已经被 GPT-5 mini 接替,所以更准确的说法是:o4-mini 仍可用于已经验证过的路由,但不应自动成为新项目的默认起点。
中文开发者最容易遇到的混淆是把 o4-mini、GPT-4o mini、GPT-5 mini、GPT-5.4 mini 和 o4-mini-deep-research 放进同一张价格表。它们不是同一个模型,也不共享同一条账单合同。成本表、日志、用量看板和代码里的 model 字段必须写精确 ID,否则后续排查会把错误价格、错误质量和错误限额归到同一个名字上。
如果一个旧系统已经用 o4-mini 跑过稳定评测,继续保留这条路由是合理的。问题不在于模型是否还存在,而在于它是否仍然用更少的总成本完成同一个读者或用户任务。总成本要包含失败重试、人工修复、推理 token、长上下文和输出长度,而不只是价格表里的输入单价。
中文环境里还要注意 provider 页面和镜像页面。它们可能展示人民币换算、充值赠送、代理稳定性或不同模型池,这些内容有采购价值,但不应改写 OpenAI direct 的官方行。
如果团队把 ChatGPT 订阅、API 账单和第三方通道混在一个预算表里,最容易误判的是“每月固定费用”和“按 token 后付费”的边界。o4-mini 是 API token 计费问题,不是 ChatGPT Plus 或 Team 套餐问题。
真正适合写入监控看板的字段包括 model、service_tier、input_tokens、cached_input_tokens、output_tokens、reasoning_tokens、retry_count 和 request_class。只有这些字段齐全,价格行才有意义。
把 o4-mini 放进生产路由时,预算表不能只写单价,还要写每个请求类别的平均输入、缓存命中比例、可见输出、推理 token、失败重试和人工修复。这样才能发现真正的成本来源:有时是 prompt 太长,有时是 reasoning budget 过宽,有时是一个低质量模型反复重试导致总价高于大模型。
评测时建议至少保留三组样本:稳定旧任务、边界困难任务和不需要推理的负样本。稳定旧任务用来判断 o4-mini 是否还能保留;困难任务用来判断是否需要 GPT-5.5;负样本用来证明某些抽取、分类和格式化工作应离开推理模型。没有负样本,团队容易把所有问题都送进推理模型。
预算沟通也要拆层:OpenAI direct 行解决技术估算,Batch/Flex/Priority 解决处理方式,Azure 或 provider 解决采购路线,ChatGPT 订阅解决人工使用场景。把这些写进同一行会让团队误以为某个价格数字同时代表模型能力、支付方式、可用地区和稳定性。
上线后应设置两个告警:一是 reasoning tokens 占 output-side tokens 的比例突然升高,二是 cached input 占比突然下降。前者通常说明任务变难、提示词失控或模型在内部循环;后者通常说明稳定前缀被改坏、schema 位置移动或请求拼接方式改变。这两个信号比单纯看日账单更早暴露问题。
迁移实验不要只跑一次平均成本。应按请求类别分别采样:高上下文请求、短输出请求、工具调用请求、失败重试请求和高缓存命中请求。o4-mini 可能在某一类里仍然最合适,也可能只是在平均值里看起来便宜。分组之后才能把它保留在真正有优势的 lane,而不是全量删除或全量保留。
预算复盘时还要把失败请求纳入账单。很多团队只统计成功答案的 token,却忽略被重试覆盖的失败调用。对于推理模型,这会低估真实成本,因为失败调用仍可能消耗输入、输出和推理 token。把失败和重试写进月度模型账单,比单看价格表更接近真实现金流。
如果要把 o4-mini 换成新模型,迁移条件应写成可验证语句:同一 eval set 上质量不下降、retry rate 不上升、平均 reasoning tokens 可解释、p95 延迟可接受、月度估算低于当前 lane 或带来足够的失败率下降。只有这些条件成立,替换才是工程决策,而不是追新。
删除旧 lane 也要保留回滚证据:旧模型的评测分数、典型失败样本、成本分布、替代模型的胜出原因和生效日期。这样后续账单或质量波动时,团队能判断是模型迁移导致,还是流量构成、prompt 或产品需求改变导致。
缓存命中复盘也应写进发布记录:哪些前缀稳定、哪些 schema 不应移动、哪些动态字段必须放在后段。否则一次看似无害的 prompt 重排,就可能让 cached input 优势消失,使 o4-mini 的真实成本突然接近更高档模型。
官方 o4-mini 价格行
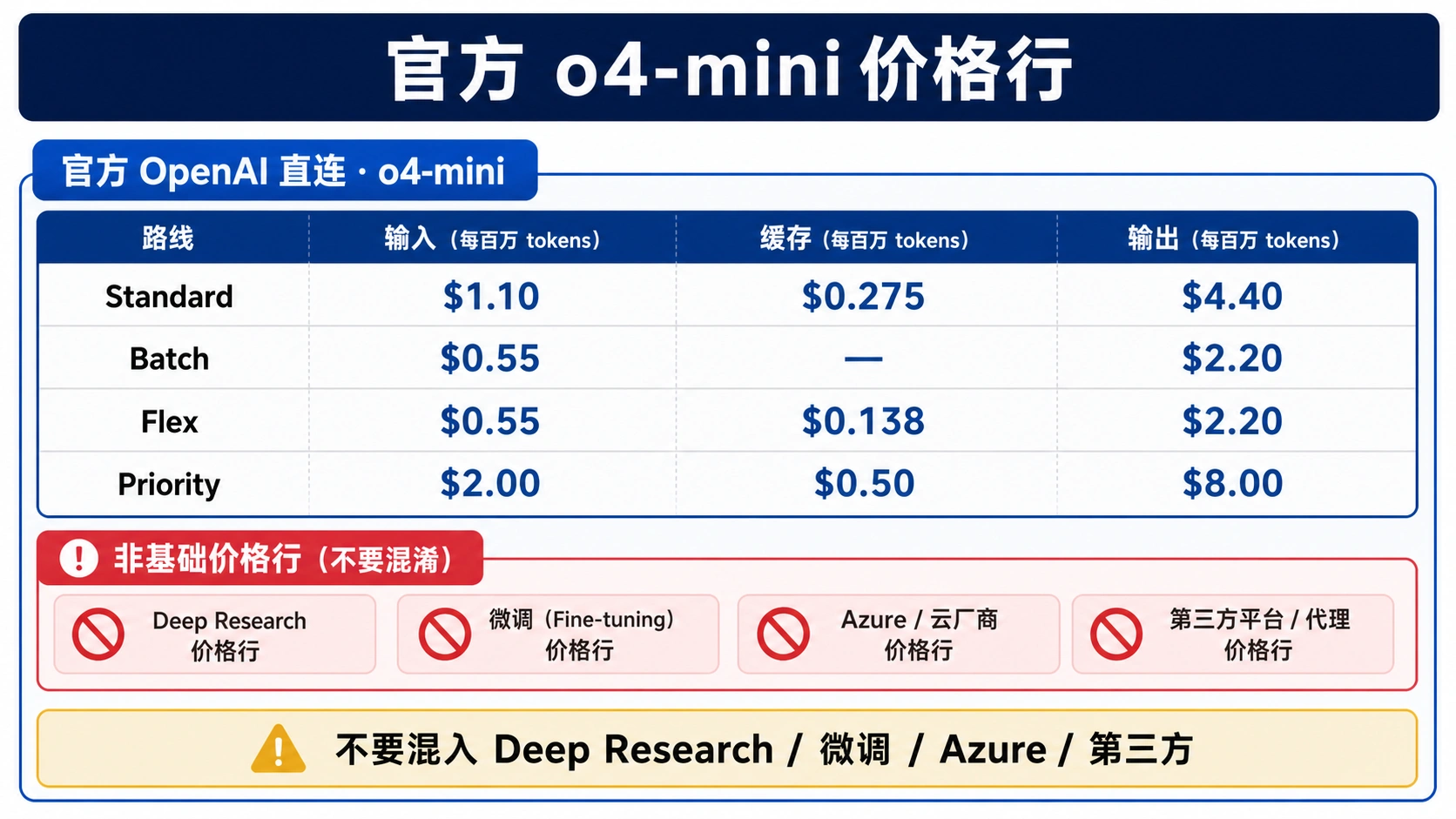
OpenAI 的 API pricing 页面是价格源头。阅读时先把 base model、service tier、专项模型和 provider 合同拆开。中文资料里经常把 Priority 或 Deep Research 的高价行贴到普通 o4-mini 上,这会把预算直接算错。
| 路由 | 输入 / 1M | 缓存输入 / 1M | 输出 / 1M |
|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 |
Batch o4-mini | $0.55 | 未单列 | $2.20 |
Flex o4-mini | $0.55 | $0.138 | $2.20 |
Priority o4-mini | $2.00 | $0.50 | $8.00 |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 |
如何估算一次真实请求
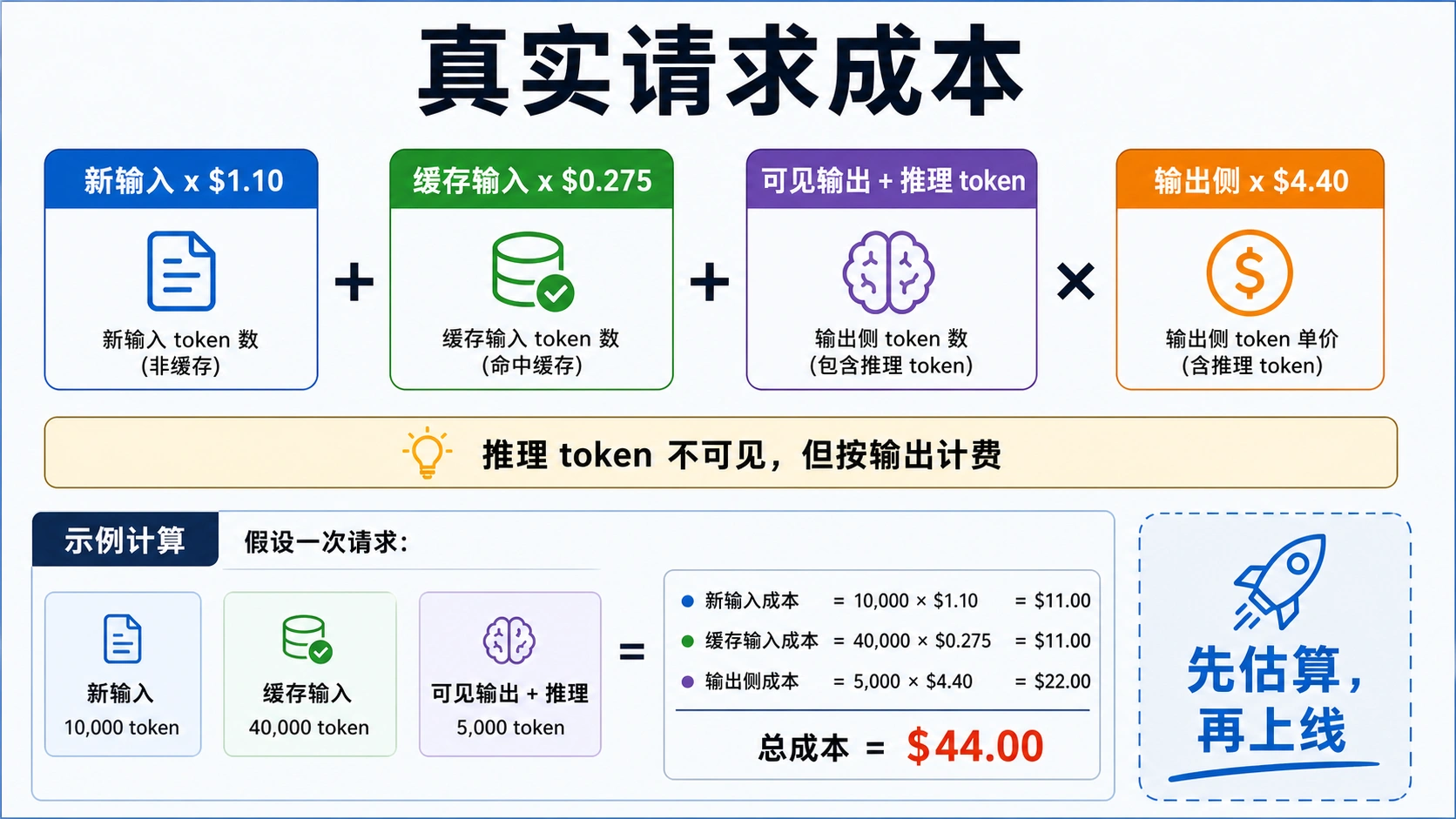
hljs textcost = 新输入 / 1,000,000 * 1.10 + 缓存输入 / 1,000,000 * 0.275 + (可见输出 + 推理 token) / 1,000,000 * 4.40
Standard 路由可以用一个工作公式估算:新输入 token 按 1.10 美元每百万计费,缓存输入按 0.275 美元每百万计费,可见输出和隐藏推理 token 相加后按 4.40 美元每百万计费。推理 token 不会出现在最终答案里,但 OpenAI 的 reasoning 文档说明它们属于输出侧账单,也会占用上下文预算。
举例:一次请求有 10,000 个新输入 token、没有缓存输入、2,000 个可见输出 token、3,000 个推理 token。输入部分是 0.011 美元,输出侧是 5,000 / 1,000,000 * 4.40 = 0.022 美元,单次估算约 0.033 美元。看起来不高,但如果每天重复几十万次,推理 token 的波动就会变成预算风险。
再看长 prompt 场景:80,000 个输入 token 中有 60,000 个命中缓存,只有 20,000 个是新输入;输出 5,000 token,推理 10,000 token。新输入约 0.022 美元,缓存输入约 0.0165 美元,输出侧约 0.066 美元,单次约 0.1045 美元。这个例子说明,缓存降低了长提示词成本,但不能抵消无限制推理和长输出。
什么时候继续用 o4-mini
o4-mini 最适合保留在已经有评测数据的位置:代码修复建议、短逻辑判断、可验收的数学推理、视觉分析、轻量规划、路由器中的第二层判断。只要它在这些任务上质量稳定、失败率可控、输出长度短,继续使用就比追逐新模型更务实。
保留并不等于停止比较。评测集至少要记录正确率、延迟、可见输出长度、推理 token、重试率、人工修复率和下游失败成本。更便宜的单价可能被更多推理 token 和更多重试吃掉;更贵的模型也可能因为一次完成任务而降低总账单。
生产路由里可以把 o4-mini 作为一个有边界的 lane,而不是全局默认模型。比如保留给结构清晰、答案长度可控、失败代价低的推理任务;把高难规划、复杂代码修复、长链路推理交给 GPT-5.5;把抽取和格式化交给非推理模型。
什么时候切换模型
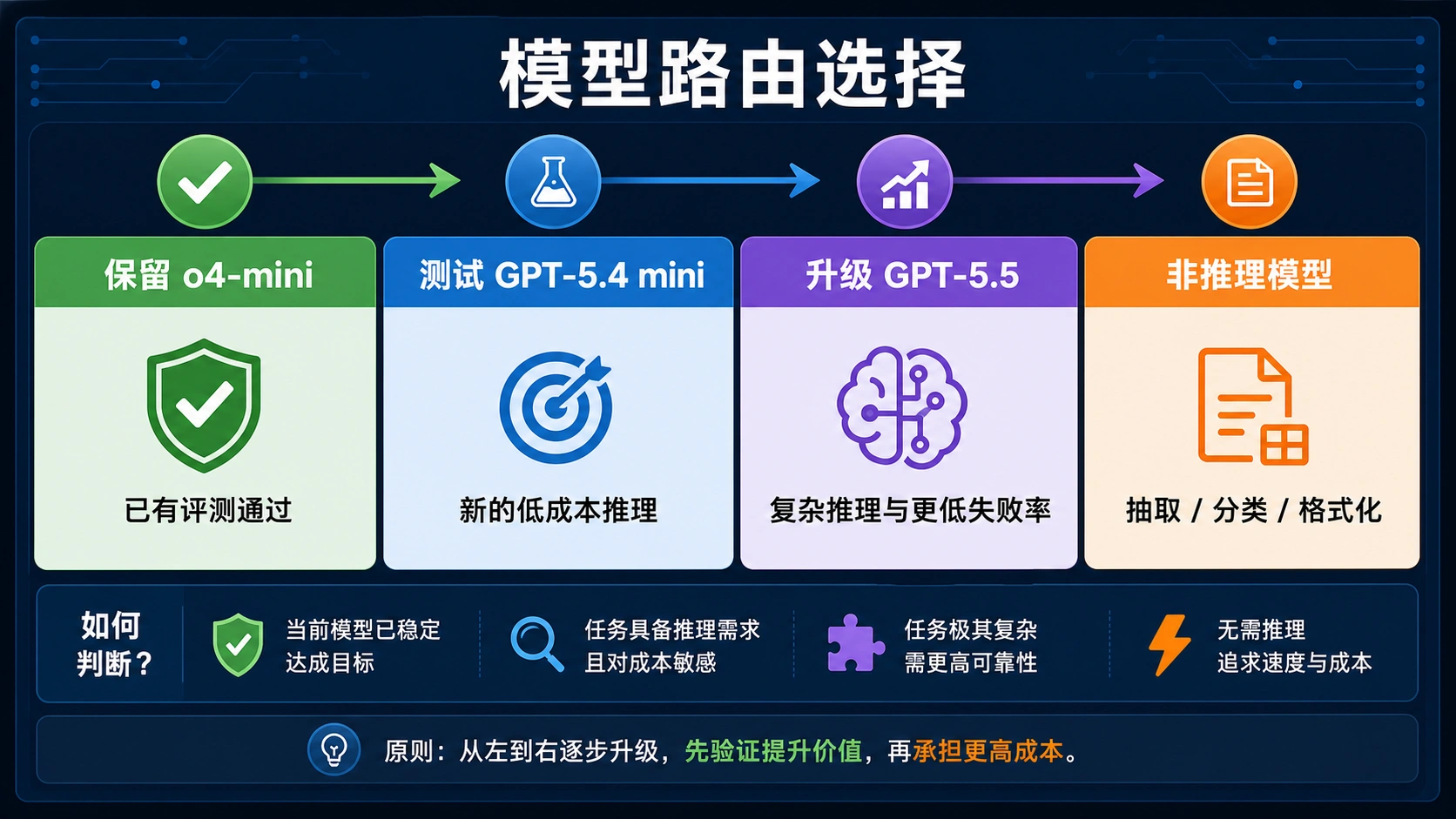
新推理任务应先测试当前推荐的 GPT-5.x 路线。成本敏感任务可以并测 GPT-5.4 mini 和 o4-mini;高难推理、复杂规划、编码修复和低容错任务应测试 GPT-5.5。不要因为 o4-mini 有低价标签就跳过新模型评测。
不需要推理的任务应直接绕开 o4-mini。字段抽取、分类、摘要格式化、JSON 清洗、元数据补全和路由预筛通常更适合便宜的非推理模型。用推理模型做确定性小任务,常见结果是质量没有明显提升,账单却被输出侧推理 token 拉高。
| 工作负载 | 先测模型 | 原因 |
|---|---|---|
已有 o4-mini lane 通过评测 | 继续 o4-mini 并复测 | 已有生产基线,先不要无证据替换。 |
| 新的低成本推理 | GPT-5.4 mini 与 o4-mini 并测 | 新模型可能有更好的质量/成本。 |
| 复杂规划、代码修复、低失败率 | GPT-5.5 | 更高单价可能用更少重试换回成本。 |
| 抽取、分类、格式化、路由 | 非推理模型 | 推理 token 通常不增加价值。 |
真正有用的成本控制
第一根成本杠杆是 prompt caching。把稳定系统指令、schema、长政策、工具说明和重复上下文放在前缀,避免每次请求都改动它们。请求里的用户输入、临时筛选条件和短期状态放在后面,这样可缓存前缀才更稳定。
max_output_tokens 不是只限制最终可见文字。对推理模型来说,它覆盖可见输出和推理 token。如果设置太低,模型可能把预算花在推理上而来不及给出可用答案;如果设置太高,隐藏推理成本可能持续膨胀。监控时要同时看 visible output 和 reasoning token。
Batch 是成本杠杆,但不是实时接口。它适合离线评测、夜间批量处理、日志回填、批量分类和内容审核队列。Flex 适合可以接受低优先级处理的在线任务。Priority 则是付费加速,不应该出现在普通预算的默认列。
如果阻塞点是 429 或配额,优先看 OpenAI API rate limit 指南;如果问题是 key、账单或试用状态,先看 OpenAI API key free trial 指南。
常见错误
不要把微调或强化微调价格当作 base inference 价格。训练小时、数据共享设置、调优模型推理和普通 Standard 调用是不同账单面。
不要把 o4-mini-deep-research 当成普通 o4-mini。名字相近,但用途和价格行不同。预算表应先写实际 model ID,再写路由。
不要把 Azure 或第三方 provider 的价格当成 OpenAI direct。它们可能包含地区、部署、限额、代理、支持和结算方式差异。它们可以是有效采购路线,但不是 OpenAI direct 价格证据。
不要只用可见输出估算。隐藏推理 token 是输出侧成本的一部分,短答案也可能有高推理开销。
上线前检查清单
- 确认代码和日志里的模型 ID 是
o4-mini,不是 GPT-4o mini、GPT-5 mini 或o4-mini-deep-research。 - 普通同步调用使用 Standard 行估算;Batch、Flex、Priority 单独列。
- 把新输入和缓存输入分开记录,避免把缓存 token 当成额外请求。
- 把可见输出和推理 token 相加后再套输出单价。
- 用评测集并测 GPT-5.4 mini、GPT-5.5 和更便宜的非推理模型。
- 如果问题其实是限额或 429,先看 OpenAI API rate limit;如果问题是 key 或账单状态,先检查 API key/free trial 路径。
常见问题
o4-mini 当前 API 价格是多少?
截至 2026 年 7 月 2 日,OpenAI direct Standard 行是每 100 万输入 token 1.10 美元、缓存输入 0.275 美元、输出 4.40 美元。Batch、Flex、Priority、Deep Research、微调、Azure 和第三方 provider 都要分开看。
推理 token 会收费吗?
会。对推理模型来说,隐藏推理 token 按输出 token 计费。估算时要用可见输出加推理 token,而不是只看最终答案长度。
缓存输入是不是把 prompt 算两次?
不是。缓存输入是当前输入中命中可复用前缀的部分,按缓存单价计费。总输入里没有命中的部分才按新输入价格算。
Batch 一定更便宜吗?
Batch 的输入和输出单价更低,但它是异步路线,有 24 小时完成窗口。实时聊天和用户同步操作不适合。
Flex 和 Batch 一样吗?
不一样。Flex 是低优先级服务层,Batch 是异步批处理。两者都可能降成本,但操作约束不同。
o4-mini 已经过时了吗?
OpenAI 文档仍列出 o4-mini,并说明它被 GPT-5 mini 接替。这意味着新任务应测试新模型,不等于已有稳定路由必须立刻删除。
应该选 o4-mini 还是 GPT-5.4 mini?
如果任务需要低成本推理,应并测两者。已有 o4-mini 评测通过可以保留;新任务更适合从当前 mini 推理路线开始测试。
月度预算怎么估?
先估一次请求的新输入、缓存输入、可见输出和推理 token,再乘以请求量、重试率、失败率、Batch/Flex 占比和可能的 Priority 使用比例。