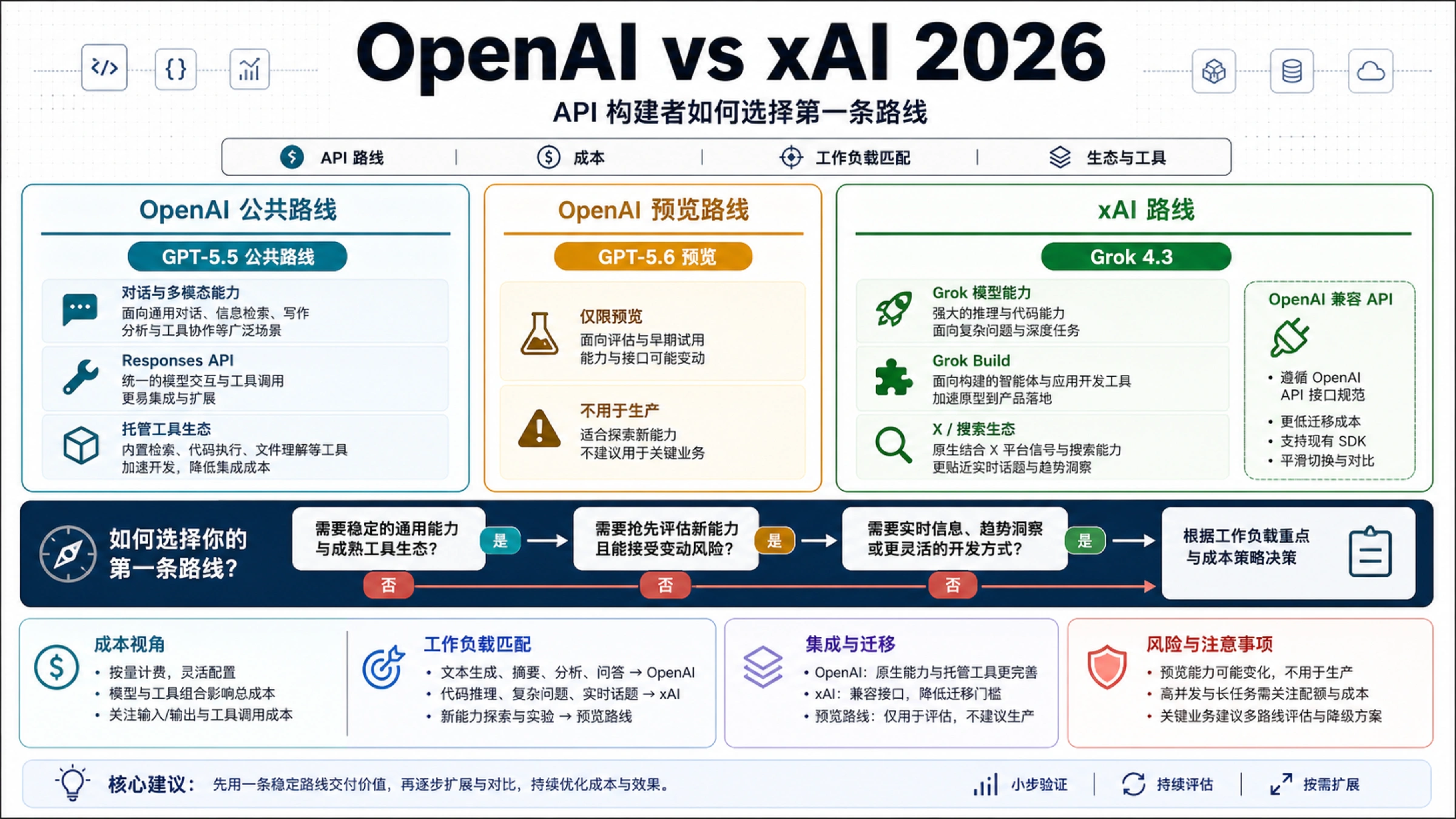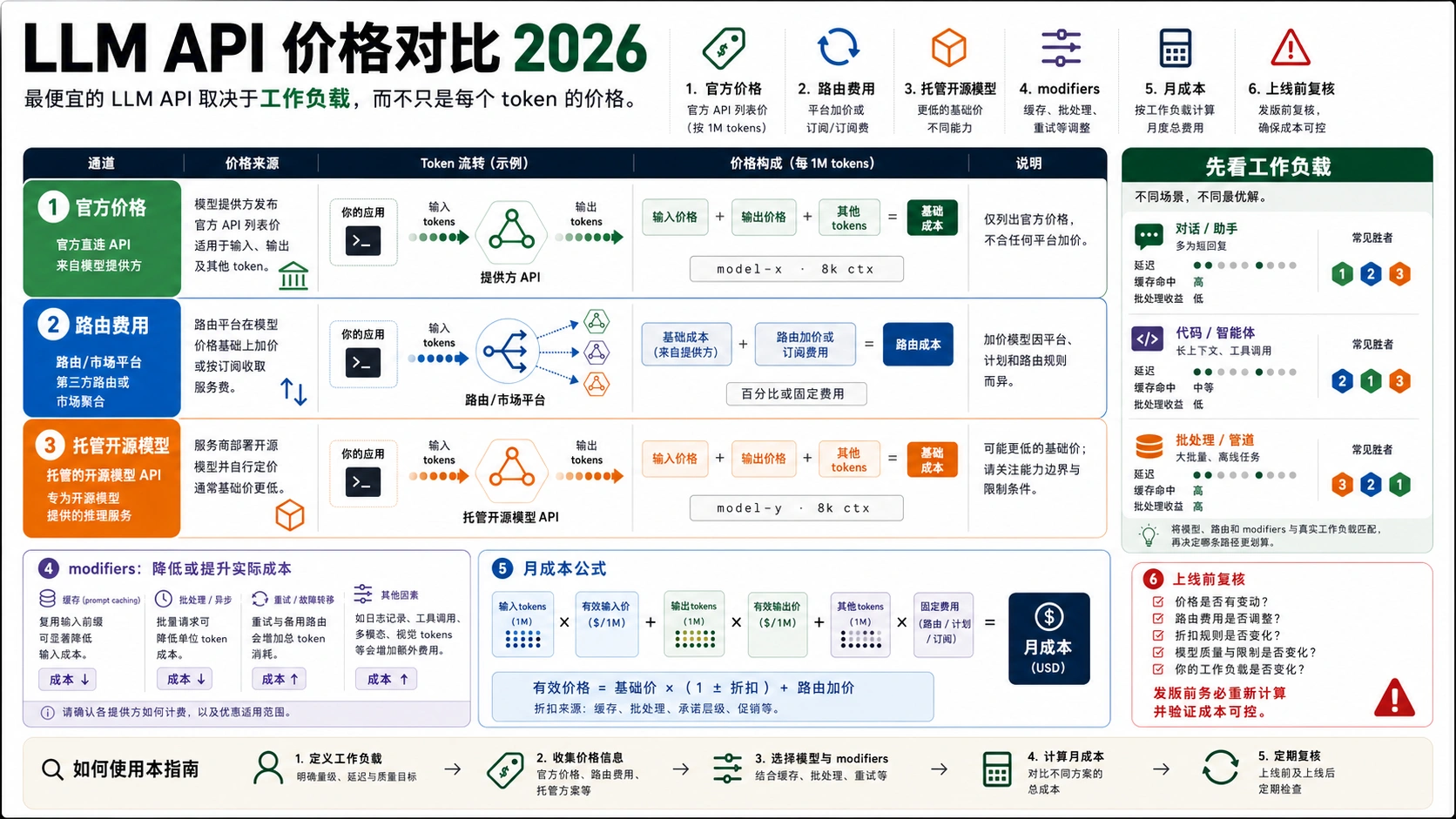
截至 2026 年 7 月 2 日,LLM API 的低价不能只看输入 token 单价。真正该比较的是同一工作负载下的可接受结果成本:输入、缓存命中、输出、工具或搜索费用、router 平台费、失败重试和人工复核都要算进去。 开发者需要的不只是实时价格表,还要知道哪一行价格由谁拥有、适用于哪条调用路线,以及什么时候必须回到官方页面复核。官方直连价格、托管开源模型价格和 router 经济模型要先拆开,才能避免把不同合同混成一个排行榜。
| 价格路线 | 适用场景 | 当前证据怎么用 |
|---|---|---|
| 官方直连 API | 需要官方支持、账单、数据路线和模型条款 | OpenAI、Anthropic、Gemini、DeepSeek、Mistral、xAI 只能由各自官方页拥有直连价格。 |
| 托管开源模型 API | 不自建 GPU,也想低价调用 open-weight 模型 | Groq-hosted GPT OSS、Llama、Qwen 是 Groq 服务价格,不是模型作者官方 API 价格。 |
| Router 或 marketplace | 一个 key 做模型切换、fallback 或多供应商测试 | OpenRouter 这类页面拥有平台费、请求限制和路由行为,不拥有底层 provider 的官方价格。 |
先用这个公式排除假便宜:
月度 API 成本 = 未缓存输入 + 缓存输入 + 输出 + route/tool/search/request 费用 + 重试开销 - batch/cache 节省
批量抽取、客服问答、coding agent、长上下文分析、合规工作流和离线 batch 的赢家可能完全不同。上线前要重新查 model availability、preview 标签、缓存和 batch 折扣、free-tier 规则、data residency uplift、router fee 与 deprecation 日期。
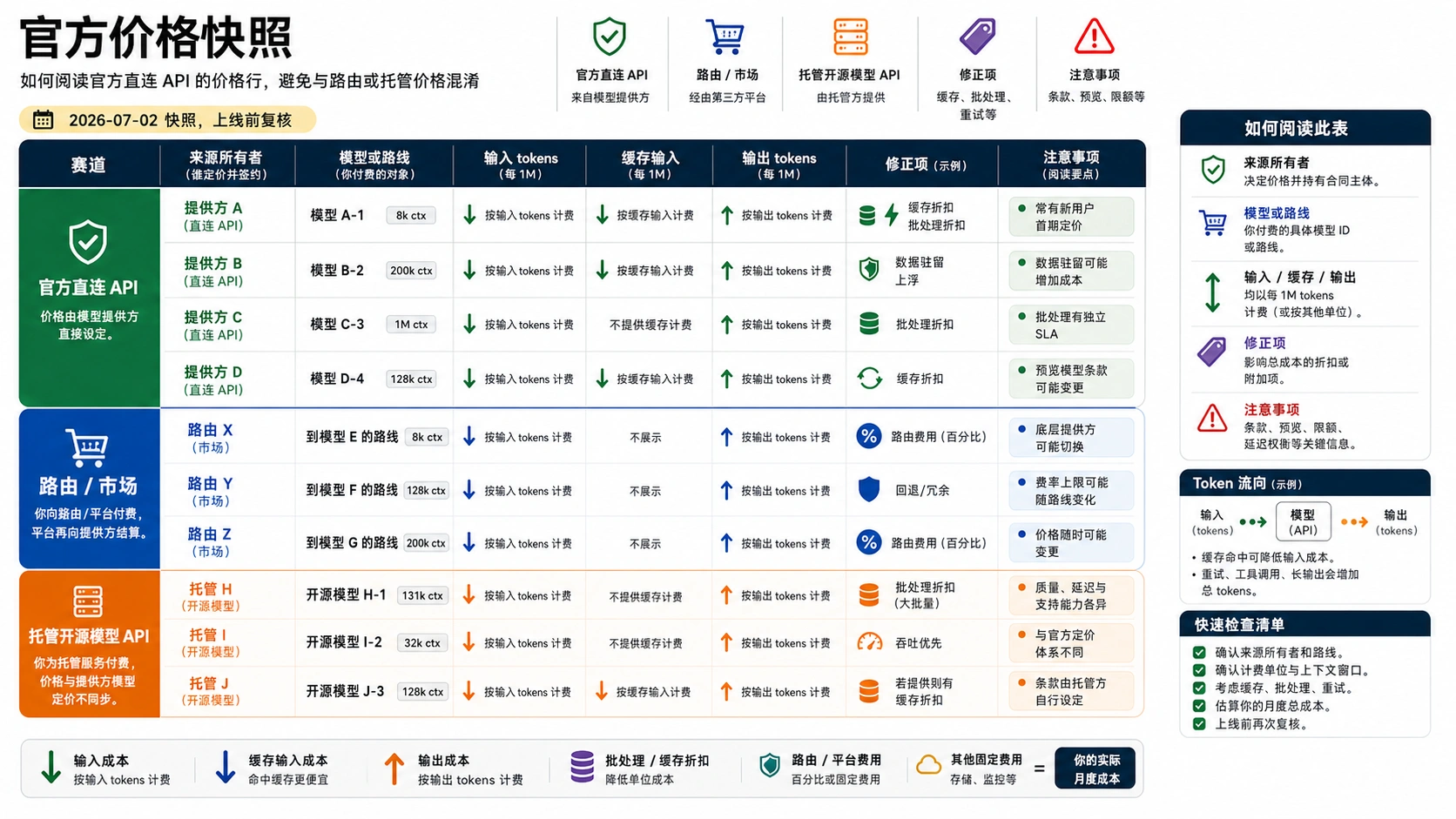
官方直连 API 价格快照
下面的表只作为 2026-07-02 的 owner-labeled 起点,不是永久榜单。单位除非另写,都是 USD / 1M tokens。输入、缓存输入和输出分开列,因为输出密集型产品经常让便宜输入价失效。
| Owner 与路线 | 2026-07-02 代表行 | 输入 | 缓存输入 | 输出 | 必须放在旁边的 caveat |
|---|---|---|---|---|---|
| OpenAI 直接 API,Standard | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Standard、Batch、Flex、Priority 是不同计费合同;区域处理端点可能另有数据驻留加价。 |
| OpenAI 直接 API,Standard | gpt-5.4-mini | $0.75 | $0.075 | $4.50 | 适合作为较低成本 OpenAI 路线的候选,不代表所有任务都最便宜。 |
| OpenAI 直接 API,Standard | gpt-5.5 | $5.00 | $0.50 | $30.00 | 只有质量收益能抵消输出成本时才进入候选。 |
| Anthropic 直接 API | Claude Sonnet 5 intro row | $2.00 | 按缓存路线区分 | $10.00 | intro 价格写明到 2026-08-31;之后公开行为是 $3.00 输入、$15.00 输出。 |
| Anthropic 直接 API | Claude Haiku 4.5 | $1.00 | 按缓存路线区分 | $5.00 | cache write、cache hit、Batch、Fast mode、data residency 都可能改变账单。 |
| Google Gemini Developer API | gemini-3.1-flash-lite,付费 Standard | $0.25 文本/图像/视频,$0.50 音频 | $0.025 文本/图像/视频,$0.05 音频 | $1.50 | Free Tier 可用于测试,但生产预算应按付费项目和数据条款另算。 |
| Google Gemini Developer API | gemini-3.5-flash,付费 Standard | $1.50 | $0.15 | $9.00 | Google Search 或 Maps grounding 超过包含额度后可能增加查询费用。 |
| Google Gemini Developer API | gemini-3.1-pro-preview,付费 Standard | $2.00 <= 200k,$4.00 > 200k | $0.20 <= 200k,$0.40 > 200k | $12.00 <= 200k,$18.00 > 200k | prompt 长度会改变价位,preview 状态也要复核。 |
| DeepSeek 直接 API | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | deepseek-chat 和 deepseek-reasoner 映射到 V4 Flash 模式,并计划在 2026-07-24 弃用。 |
| DeepSeek 直接 API | deepseek-v4-pro | $0.435 cache miss | $0.003625 cache hit | $0.87 | 官方页还列出 1M 上下文与最大输出;上线前仍需测延迟和质量。 |
| Mistral 官方价格 | Mistral Large 示例 | $2.00 | 公开 FAQ 未列 | $6.00 | Mistral 说明 API 价格同时计算输入和输出,Batch 有 50% 折扣。 |
| xAI 模型文档 | Grok 4.3 | $1.25 | 未列 | $2.50 | coding 场景另看 Grok Build 0.1;语音、图像、视频是不同单位。 |
托管开源模型和 router 也可能更便宜,但合同不同:
| 路线 owner | 行或合同 | 价格信号 | 使用方式 |
|---|---|---|---|
| Groq 价格 | openai/gpt-oss-20b hosted by Groq | $0.075 uncached input,$0.0375 cached input,$0.30 output | 作为 GroqCloud 托管服务价使用,而不是模型作者官方价格。 |
| Groq 价格 | openai/gpt-oss-120b hosted by Groq | $0.15 uncached input,$0.075 cached input,$0.60 output | 适合作为高量 open-model 任务的便宜首测,仍要测质量和延迟。 |
| OpenRouter 价格 | Pay-as-you-go plan | 5.5% platform fee,400+ models,70+ providers | 这是 router 合同,不是底层模型官方价格。 |
| OpenRouter 价格 | Free plan | 50 requests/day,free-model access | 可探索,不是生产权益。 |
如果你的候选模型不在表中,不要直接照搬第三方表。回到 owner 页面,把模型 ID、路线、单位、检查日期和 caveat 补到同一个格式里,再计算成本。
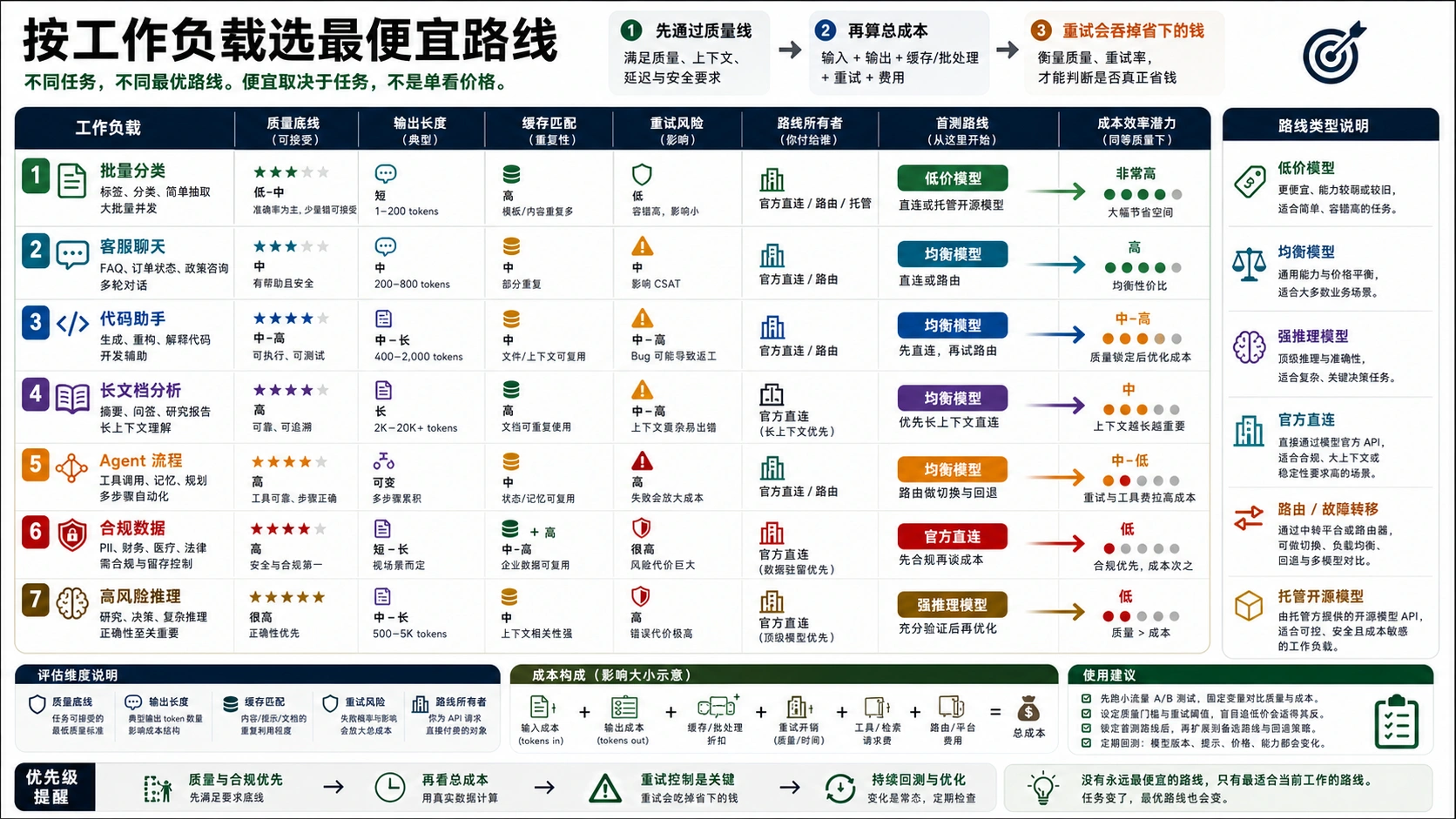
按工作负载找便宜路线
便宜模型只有在同一任务上达到可接受质量时才算赢。因此第一轮 shortlist 应该从工作负载出发,而不是从 provider 出发。
| 工作负载 | 先测这些候选 | 为什么可能便宜 | 停止规则 |
|---|---|---|---|
| 批量抽取、分类、清洗 | DeepSeek V4 Flash、Gemini 3.1 Flash-Lite、Groq GPT OSS 20B、OpenAI GPT-5.4-nano | 输入和输出低价都重要,因为通常能用标签或校验器测质量。 | 统计 false positive、retry、人审率后再上线。 |
| 客服机器人和 FAQ | Gemini 3.1 Flash-Lite、OpenAI GPT-5.4-mini/nano、Claude Haiku 4.5、DeepSeek V4 Pro | 输出比例中等,重复 policy/context 可以吃缓存收益。 | 如果升级人工和幻觉变多,最低 token 价不是最低成本。 |
| Coding assistant 或 agentic tool use | Claude Sonnet 5、OpenAI GPT-5.4/GPT-5.5、xAI Grok Build、Gemini 3.5 Flash | 失败会制造重试、回滚和开发者时间成本。 | 用同仓库 eval、tool-call 成功率和 rollback 成本决策。 |
| 长上下文分析 | Gemini Pro/Flash 长上下文、DeepSeek V4 1M context、Grok 4.3 | 一次大调用可能比 chunking + retrieval 便宜。 | 跨过上下文价位或涉及 cache storage 时重新算。 |
| 合规、敏感或企业工作流 | 官方直连 API 或签约云路线 | 账单、数据处理、审计、支持和 region 可能比低价更重要。 | 不要只因 router token 行低就迁移。 |
| 离线 batch | OpenAI Batch、Google Batch、Mistral Batch、Groq Batch | 异步任务通常有折扣。 | batch 不是低延迟路线,确认完成窗口和输出获取。 |
月度成本工作表
真实账单从 token mix 开始,不从单行价格开始。每个候选都要用同一组输入、输出、缓存、工具费用和失败率估算。
- 每月未缓存输入 tokens。
- 每月缓存输入 tokens 或 cache-hit rate。
- 每月输出 tokens,包括 provider 计为 output 的 reasoning/thinking tokens。
- 工具、搜索、request、route 或 platform fee。
- retry 和 fallback overhead。
- batch 或 cache 节省。
- 输出不合格时的人审或失败成本。
| 场景 | 候选路线 | Token mix | 简单月度 token 成本 | 解读 |
|---|---|---|---|---|
| 批量数据清洗 | Groq GPT OSS 20B | 100M 输入,10M 输出 | $10.50 | 托管开源模型能过校验时非常便宜。 |
| 批量数据清洗 | DeepSeek V4 Flash | 100M cache-miss 输入,10M 输出 | $16.80 | 直连 DeepSeek owner row,价格低,但仍要测质量和延迟。 |
| 批量数据清洗 | OpenAI GPT-5.4-nano | 100M 输入,10M 输出 | $32.50 | OpenAI 兼容性或质量更好时值得测。 |
| 批量数据清洗 | Gemini 3.1 Flash-Lite | 100M 文本输入,10M 输出 | $40.00 | cache 或 Batch 可降低,但不要把 Free Tier 当生产预算。 |
| 输出密集 chatbot | Groq GPT OSS 20B | 20M 输入,20M 输出 | $7.50 | 输出也低,但 open-model 质量必须验证。 |
| 输出密集 chatbot | DeepSeek V4 Flash | 20M cache-miss 输入,20M 输出 | $8.40 | 输出便宜;要测 hallucination 和升级成本。 |
| 输出密集 chatbot | OpenAI GPT-5.4-nano | 20M 输入,20M 输出 | $29.00 | 输出成本主导,只有任务质量更好时才值得。 |
| 输出密集 chatbot | Gemini 3.1 Flash-Lite | 20M 文本输入,20M 输出 | $35.00 | 生态适配或质量减少重试时可进入 shortlist。 |
再加入真实 modifier:如果 OpenAI GPT-5.4-nano 的重复 system prompt 有 40% 变成 cached input,这部分会从 $0.20/M 降到 $0.02/M。Gemini 3.1 Flash-Lite 如果能跑 Batch,付费 input 从 $0.25/M 降到 $0.125/M,output 从 $1.50/M 降到 $0.75/M。OpenRouter 路线如果收 5.5% platform fee,就要先把 routed model spend 乘以 1.055 再和直连账单比。
最后用每个成功任务的价格收口:
每个完成任务成本 = 月度路线总成本 / 可接受任务数量
如果便宜路线完成率 94%,较贵路线完成率 99.5%,那缺掉的 5.5% 会变成 retries、fallbacks、人审、support ticket 或坏输出。

直连 API、Router、托管开源模型还是自托管?
直连 API 和 router 解决的是不同 ownership 问题。直连 provider 更适合需要官方支持、账单清晰、数据路线、企业控制和 incident 诊断的场景。
Router 适合模型切换、fallback、流量比较和统一接口。OpenRouter 的 5.5% platform fee、free-plan request limit 和 routing 行为要进入成本模型;它不能替代 OpenAI、Anthropic 或 Google 的官方直连价格。
托管开源模型 API 处在中间。Groq 拥有自己的服务价格、可用模型、速率限制和延迟特征。openai/gpt-oss 标签不等于 OpenAI 官方 API price。
自托管只有在规模、数据本地化、硬件和运维能力都成立时才进入比较。否则所谓免费权重会隐藏 GPU 利用率、serving、monitoring、security patch 和 on-call 成本。
会让简单价格表失真的计费因素
第一陷阱是输出比例。总结、客服和报告生成经常让 output 花费超过 input,所以只看 input 单价会误导。
第二是缓存。OpenAI、Google、Anthropic、DeepSeek、Groq 的 cache 语义不同,有的区分 cache hit/miss,有的还有 storage 费用。重复 policy-heavy prompt 和一次性 QA 是两种账单。
第三是 Batch。OpenAI、Google、Mistral、Groq 都有某种 batch economics,但它适合异步抽取、eval generation 和 enrichment,不适合实时 chat。
第四是 tool 与 search 费用。Web search、Google grounding、compound tools、router-side features 可能让 token 只是账单的一部分。
第五是 preview、intro、tier threshold 和 deprecation。Anthropic intro row 有结束日期,Gemini Pro Preview 受 prompt length 影响,DeepSeek alias 有弃用日期。简单表格省略这些 caveat,就不是成本计划。
最后是 retry overhead。便宜模型如果平均 1.3 次才产出合格答案,就要按 1.3 次算。
Provider 备注
OpenAI 的 pricing page 是 OpenAI direct API token rows 的 owner,并把 Standard、Batch、Flex、Priority 分开。它也提示 AWS Bedrock 和区域数据处理可能是不同账单。
Anthropic 的 pricing page 拥有 Claude direct API rows,也拥有 cache write、cache hit、Batch、Fast mode、data residency 的解释。如果问题是 API 与订阅座席对比,应看 Claude API pricing versus subscription。
Google Gemini pricing page 拥有 Gemini Developer API rows,并把 Gemini 3.5 Flash、3.1 Flash-Lite、3.1 Pro Preview、image models、search grounding、Batch、Free Tier 分开。如果问题是免费额度,看 Gemini API free tier。
DeepSeek 官方页现在展示 deepseek-v4-flash 和 deepseek-v4-pro,并说明旧 deepseek-chat、deepseek-reasoner 映射到 V4 Flash mode 且计划弃用。
Mistral 的公开页面足以引用计价方式、Mistral Large 示例和 50% Batch discount;不要在没有官方证据时补其他 model row。
xAI docs 指向 Grok 4.3 和 Grok Build 0.1。语音、图像、视频单位不要混进 text-token 表。
Groq 是托管开源模型服务路线。它的价格是 GroqCloud serving 的官方价格,而不是模型作者的官方直连价格。
OpenRouter 是 router/marketplace 路线。需要模型切换、fallback、logs 或统一 key 时可用,但不要把它的 row 写成底层 provider 官方价格。
上线前复核清单
| 检查项 | 要记录什么 |
|---|---|
| 价格 owner | 官方 provider、托管 provider、router、cloud marketplace 或 self-host。 |
| 模型 ID | 精确 model string,是否 alias、preview、dated version 或 deprecation path。 |
| Token mix | input、cached input、output、reasoning/thinking tokens、平均输出比例。 |
| 路线费用 | platform fee、request fee、search/tool fee、cache storage、data residency、cloud marketplace uplift。 |
| 质量阈值 | pass rate、retry rate、fallback rate、人审率和失败输出成本。 |
| 延迟和限制 | RPM、TPM、context limit、batch window、timeout 和 status behavior。 |
| 数据路线 | retention、training use、region、enterprise terms、audit needs。 |
| 花费控制 | hard cap、alerts、project budgets、tenant attribution 和 rollback route。 |
常见问题
现在最便宜的 LLM API 是什么?
高量简单文本任务里,Groq GPT OSS 20B 这类托管开源模型或 DeepSeek V4 Flash 这类低价直连 row 看起来最便宜。但真正的最便宜路线,是把输出比例、cache、batch、retry、route fee 和质量阈值都算完后仍然胜出的路线。
OpenAI 比 Claude 或 Gemini 便宜吗?
取决于模型和任务。OpenAI GPT-5.4-nano/mini 可作为低成本 OpenAI 候选;Claude Sonnet 5 可能在 coding 或 agentic 质量上抵消高价;Gemini 3.1 Flash-Lite 可能适合 Google 生态内高量任务。
应该用 OpenRouter 这类 router 吗?
当模型切换、fallback、单一账户或多 provider 比较能节省工程时间时可以用。把 5.5% platform fee、free-plan request limit 和路由行为加入成本模型。
Free tier 能用于生产吗?
通常不能。free tier 适合探索和低风险 prototype,生产需要可预测 quota、账单 owner、数据条款、支持路径和 spend controls。
为什么输出价格这么重要?
很多 provider 的 output token 比 input token 贵几倍。chatbot、agent、report generator 可能主要花在输出上。
cache 和 batch 会怎样改排名?
cache 帮助重复 prompt、shared policy context、长文档和稳定 prefix;batch 帮助可等待的离线任务。只有工作负载真实匹配折扣条件时,它们才会改赢家。
第三方 LLM 价格表可信吗?
可以用来发现模型和 UX 需求,但 final pricing 要回官方 owner。router 和 hosted-provider 页面只拥有自己的路线经济模型。
多久要更新一次 LLM API 价格对比?
每次生产决策前和每次发布 refresh 前都要重查。model name、preview status、deprecation、free tier、cache rule、batch discount 和 router fee 都会变化。