OpenAI 和 xAI 在 2026 年的比较,不能用“谁更强”一刀切。更可靠的做法是先判断工作负载:如果你需要成熟的公开 API、GPT-5.5 级别的推理或编码、Responses API 状态管理、托管工具、组织权限和企业运维,OpenAI 通常是第一站;如果你需要 Grok 4.3 的成本/上下文窗口、OpenAI 兼容的迁移入口、X/搜索分析、Grok Build 编码、图像视频或语音路线,xAI 值得先做 proof;如果答案依赖 GPT-5.6,先确认组织是否获批预览资格。
| 先测路线 | 适合场景 | 上线前必须核验 |
|---|---|---|
| OpenAI 先测 | 公开 GPT-5.5、复杂推理/编码、Responses API、托管工具、企业账号和审计控制。 | 模型可用性、价格行、缓存、长上下文、工具费用、服务层级、账号控制。 |
| xAI 先测 | Grok 4.3 成本/上下文、OpenAI 兼容迁移、X/搜索、Grok Build、媒体或语音任务正好匹配。 | xAI 模型 ID、工具费用、Batch/Priority 行为、策略收费、媒体/语音路线、支持 owner。 |
| GPT-5.6 只在获批后测试 | 组织已经有 Sol/Terra/Luna 预览权限,且能承受 preview 风险。 | 访问资格、模型名、价格、缓存行为、端点支持、回退到 GPT-5.5 的方案。 |
| 两家都测 | 成本、延迟、工具行为、策略拒绝或人工复核决定真实成本。 | 同一批 prompt、同一数据、重试、工具调用、拒绝调用、日志、有效结果率。 |
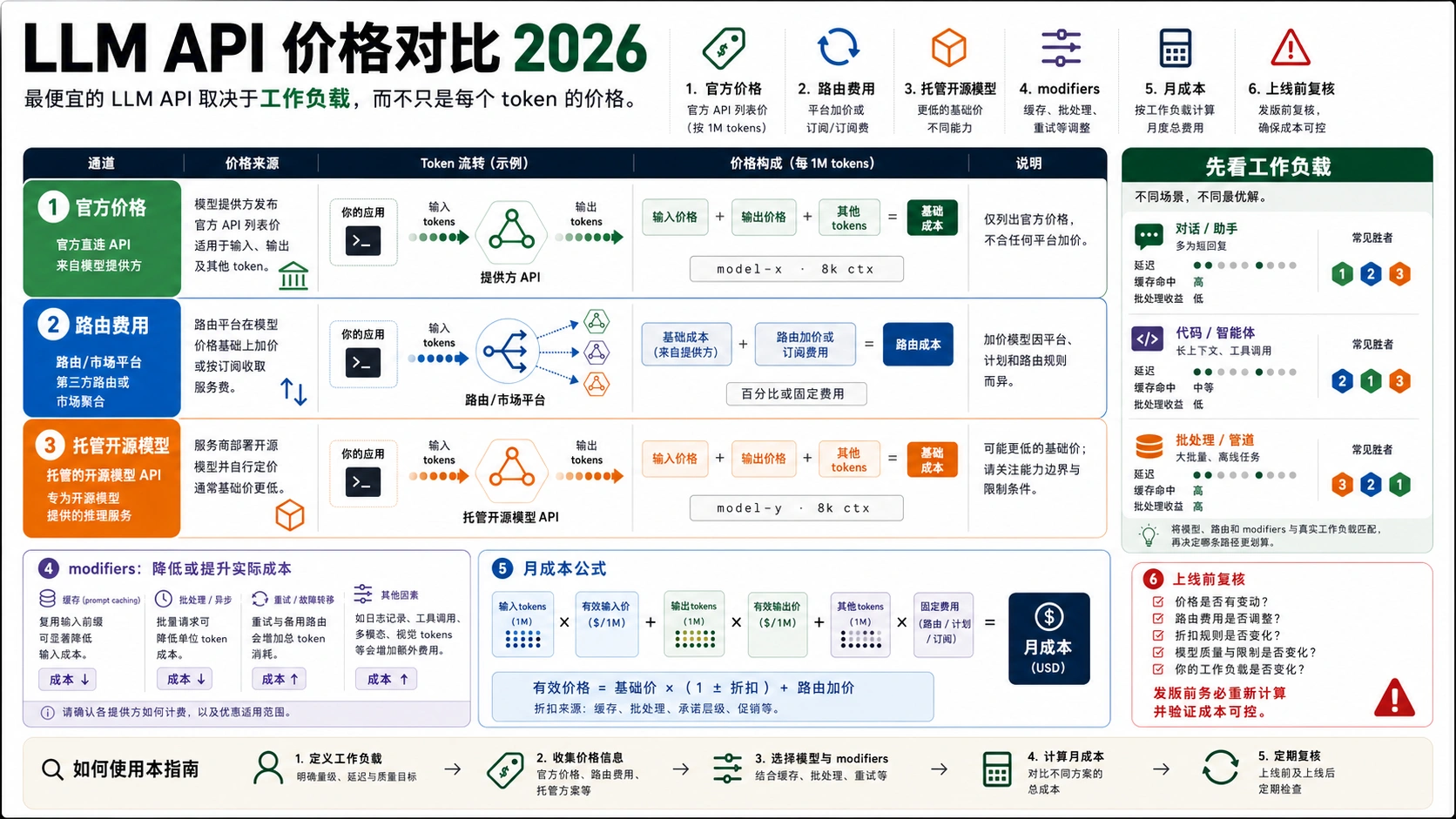
停止线:不要只按 token 单价选供应商。上线前要把缓存、长上下文、工具、服务层级、重试、策略拒绝、支持 owner 和有效输出成本一起算进去。
先看访问资格和工作负载,不要先看最大模型名
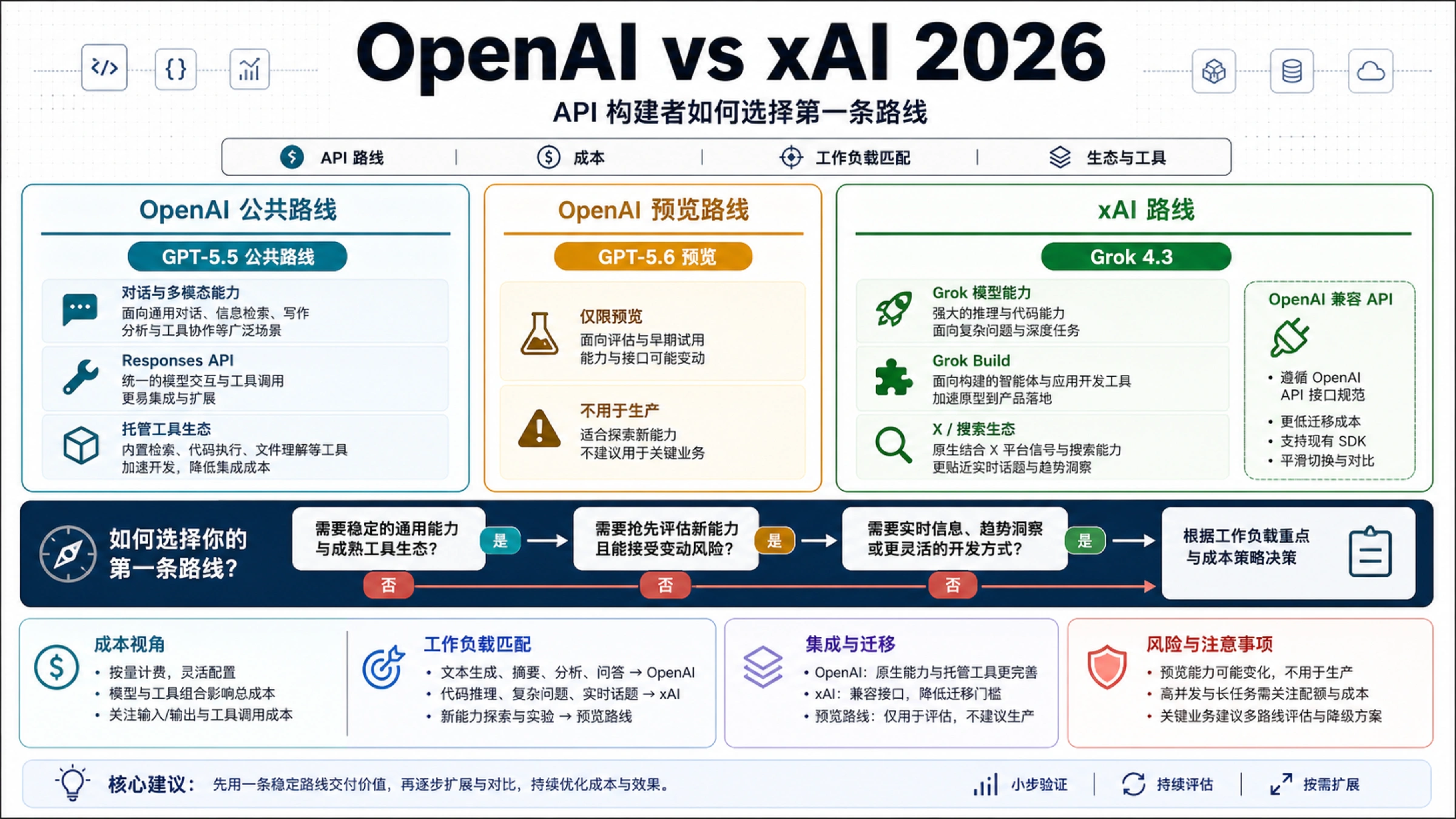
OpenAI 和 xAI 不是一组简单的“旗舰模型对旗舰模型”。OpenAI 这边要先拆公开路线和预览路线。2026 年 7 月 2 日核验的 OpenAI 官方模型页仍把 GPT-5.5 放在复杂推理和编码的公开基线位置,而 GPT-5.6 Sol、Terra、Luna 是面向 selected organizations 的 limited preview。也就是说,GPT-5.6 可以进入获批团队的评估计划,但不应该被普通公开 API 规划当作默认路线。
xAI 的陷阱相反。很多中文结果会把 xAI 简化成“Grok 更便宜”,但官方路线并不是一行文字模型。xAI 模型页在同日显示 Grok 4.3 是默认文本路线,Grok Build 是编码模型,Grok Imagine 面向图像和视频,Grok Voice 面向语音,还要单独看搜索、代码执行、Batch 和 Priority。若工作负载需要 X/搜索信号或想用 OpenAI 风格 SDK 快速试迁移,xAI 的第一轮测试很合理;若工作负载依赖托管工具、长期状态、组织治理和更成熟的公开生态,OpenAI 更稳。
实际问题不是哪个公司更先进,而是哪条路线拥有你的工作负载。公开客户应用、企业内控、复杂工具链和长期支持通常先看 OpenAI;成本敏感的长上下文摘要、X/搜索分析、部分编码或媒体/语音实验可以先看 xAI;所有把 GPT-5.6 写进路线图的团队,都应该先做访问资格检查。
中文开发者团队还要避免把“可调用”误认为“可替换”。如果现有系统已经把权限、日志、失败重试、客户支持和账单归因绑在 OpenAI 组织账号上,xAI 的兼容 SDK 只能降低第一版 proof 的改造成本,不能自动继承这些生产约束。反过来,如果团队当前只是用一个轻量文本端点做摘要或提取,且没有深度依赖 OpenAI 托管工具,那么 Grok 4.3 的低价和长上下文可能值得更早进入候选。先画出调用链、工具链、账单链和支持链,再决定哪家先测,比只看模型名更接近真实上线决策。这个顺序也能减少后期因为权限、日志或支持边界不清而返工,更适合真实上线。
只想看 OpenAI 内部模型分流,可以读 OpenAI 模型路线图。只想看 xAI 内部模型选择,可以读 Grok 模型路线指南。OpenAI 与 xAI 的交叉选择要继续围绕“先测哪家”和“哪条路线负责结果”展开。
价格比较:token 单价只是第一行
如果只看标准文本 token 行,xAI 很有吸引力。2026 年 7 月 2 日核验的 OpenAI 官方价格页列出 GPT-5.5 标准短上下文为每 100 万输入 token 5 美元、缓存输入 0.50 美元、输出 30 美元。xAI 的 Grok 4.3 官方模型页列出每 100 万输入 token 1.25 美元、输出 2.50 美元,并给出 100 万上下文窗口。对高吞吐、少工具、结果验收简单的文本任务,这个差距很真实。
但真实预算很少停在第一行。OpenAI GPT-5.5 长上下文价格、272K 输入以上的倍率、Batch/Flex 半价和 Priority 溢价都会改变账单。xAI 也一样:Batch 可能降低 token 成本,Priority 是 2 倍标准 token 费,Web Search、X Search、Code Execution、文件和 collections search 都是额外工具账单。中文语境里常见“性价比”判断,如果没有把这些第二张账单纳入,容易把试用价格误判成生产成本。

| 成本项 | OpenAI 要问什么 | xAI 要问什么 |
|---|---|---|
| 基础 token | 实际可用的是 GPT-5.5、GPT-5.4 mini/nano,还是获批 GPT-5.6 preview? | Grok 4.3 是否足够,还是要 Grok Build、媒体、语音、Batch 或 Priority? |
| 缓存输入 | 重复上下文能否缓存,适用哪一行价格? | 这条路线是纯 token、工具重、媒体重还是语音重? |
| 长上下文 | prompt 是否跨过 GPT-5.5 长上下文或倍率阈值? | Grok 4.3 的 100 万上下文能否减少检索、重试和人工复核? |
| 工具 | web search、file search、容器或托管工具是否进入答案? | Web Search、X Search、Code Execution、文件和 collections 是否进入答案? |
| 服务层级 | Batch、Flex、standard、Priority 哪个才是真路线? | Batch 的延迟能不能接受,Priority 是否把 token 成本翻倍? |
| 被拒绝或无效输出 | 哪类策略、审核或拒绝会造成重试? | xAI 价格页说明违反使用准则的请求仍可能收费,因此策略适配要进成本模型。 |
更有用的指标是有效输出成本,而不是输入 token 单价。有效输出成本包括用户真正采用的输出、被丢弃的输出、修复工具行为的重试、策略阻断后的重跑,以及日志、人工复核和工程排障时间。
模型路线:OpenAI 公开线、GPT-5.6 预览线和 xAI Grok 分支
OpenAI 的公开路线足够宽。GPT-5.5 是复杂推理和编码的公开 API 基线,GPT-5.4 mini 与 nano 更适合低延迟和低成本分支。GPT-5.5 支持文本和图像输入、文本输出、大上下文,以及 Responses、Chat Completions、Batch 等端点。对从原型走到生产的团队,这比押注一个未普遍开放的 preview 名称更稳。
GPT-5.6 必须用另一种语气处理。Sol、Terra、Luna 的 preview 价格和缓存规则值得获批组织评估,但对普通公开 API 读者,正确写法是“获批才测,生产有 GPT-5.5 回退”。如果销售页、预算、PRD 或架构文档把 GPT-5.6 当成默认能力,却没有账号级访问证明,就会在上线前暴露风险。
xAI 的默认文本路线从 Grok 4.3 开始。它有 100 万上下文,支持 agentic tool calling 和 non-reasoning mode,官方价格低于 GPT-5.5 标准文本行。Grok Build 则要放到编码任务里单独评估,不能把所有 xAI 工作都推给 coding model。客服摘要、RAG 回答、结构化抽取先测 Grok 4.3;编码助手或代码库代理要直接测 Grok Build,再比较可接受 patch、工具轨迹、重试次数和 review 时间。
媒体和语音也不能从文本价格推断。Grok Imagine、Grok Voice、OpenAI 图像/音频/实时路线都有自己的输出标准、费用和接口行为。需要图像、视频或语音时,先做独立 route proof,再决定是否和文本主路线共用供应商。
API 兼容:请求形状熟悉,不等于供应商等价
xAI quickstart 展示了用 OpenAI Python 或 JavaScript client 配置 xAI base URL 和 xAI API key 的方式,也展示 Responses API 和图像生成示例。这个兼容入口对已有 OpenAI 风格代码很有价值:团队可以先用较少改造做概念验证。
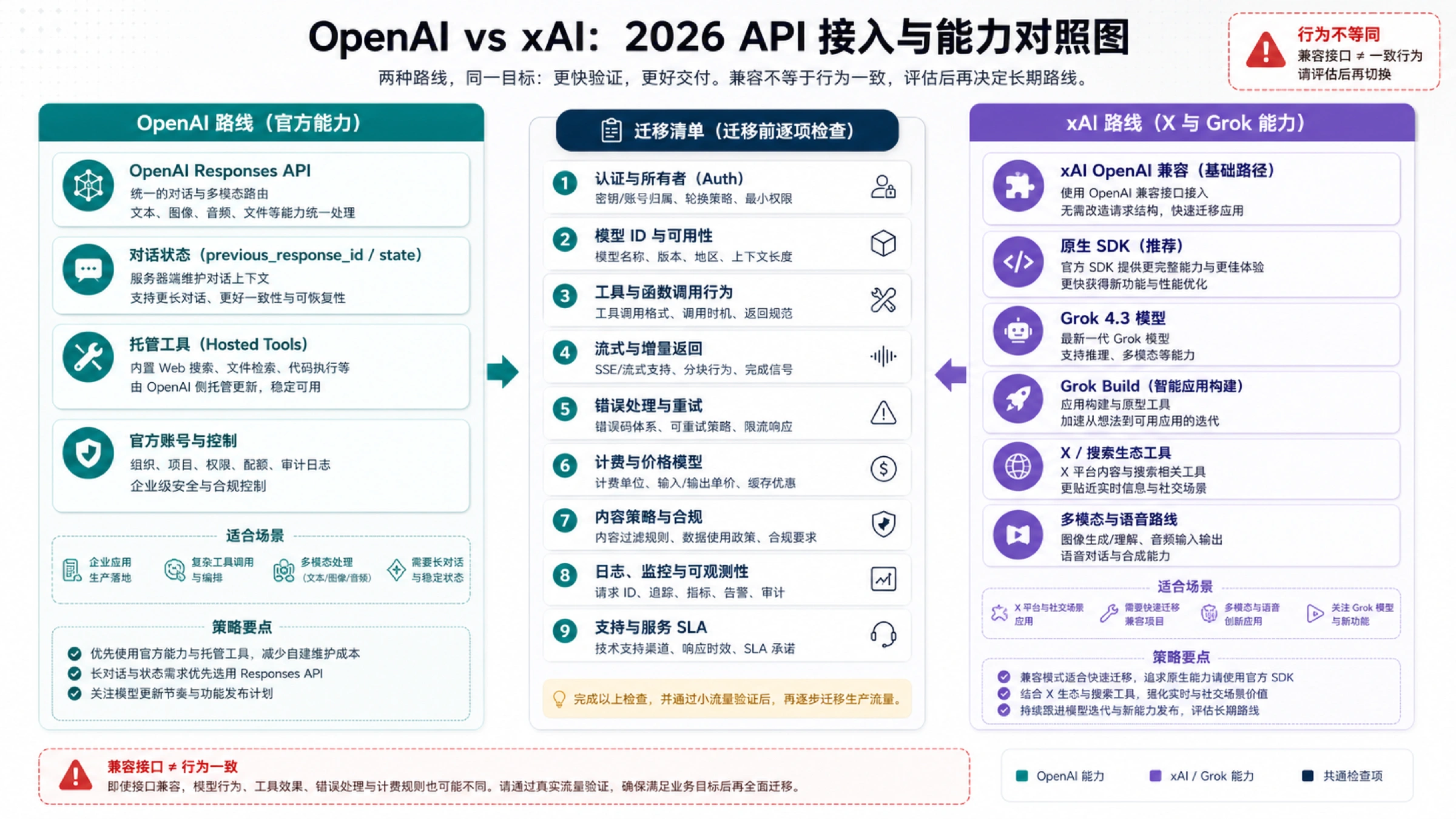
兼容不等于等价。xAI 仍然拥有模型行为、工具支持、价格、策略处理、日志、支持、模型 ID 和可用性;OpenAI 仍然拥有托管工具、Responses 语义、账号控制、服务层级和模型生命周期。一个文本请求成功,只能证明请求形状能跑,不能证明 streaming 事件、工具调用结构、文件处理、错误码、重试逻辑、策略结果或账单行为相同。
| 迁移检查 | 为什么重要 |
|---|---|
| 认证和账单 owner | key、组织、账单账号和支持路径都会换。 |
| 模型 ID | 兼容 SDK 仍然要使用供应商拥有的模型名。 |
| 工具行为 | web、X、文件、代码、托管工具和容器没有统一合同。 |
| streaming 和状态 | 多轮状态、事件结构和响应增量可能不同。 |
| 错误和重试 | 为 OpenAI 写的 retry 逻辑可能在 xAI 上过度重试或隐藏可计费失败。 |
| 日志和审计 | 生产成本包括可观测性和治理流程。 |
| 策略行为 | 被拒绝、被阻断或敏感请求会影响输出率和支出。 |
如果目标是降低迁移摩擦,xAI 的 OpenAI 兼容路线值得优先测。如果目标依赖精确工具语义、托管文件、企业控制或长期运维行为,OpenAI 应该保留在第一轮候选。
最佳使用场景:先测哪一家
供应商比较必须落到工作负载。榜单和 benchmark 只能告诉你该调查什么,不能替你算有效输出成本。
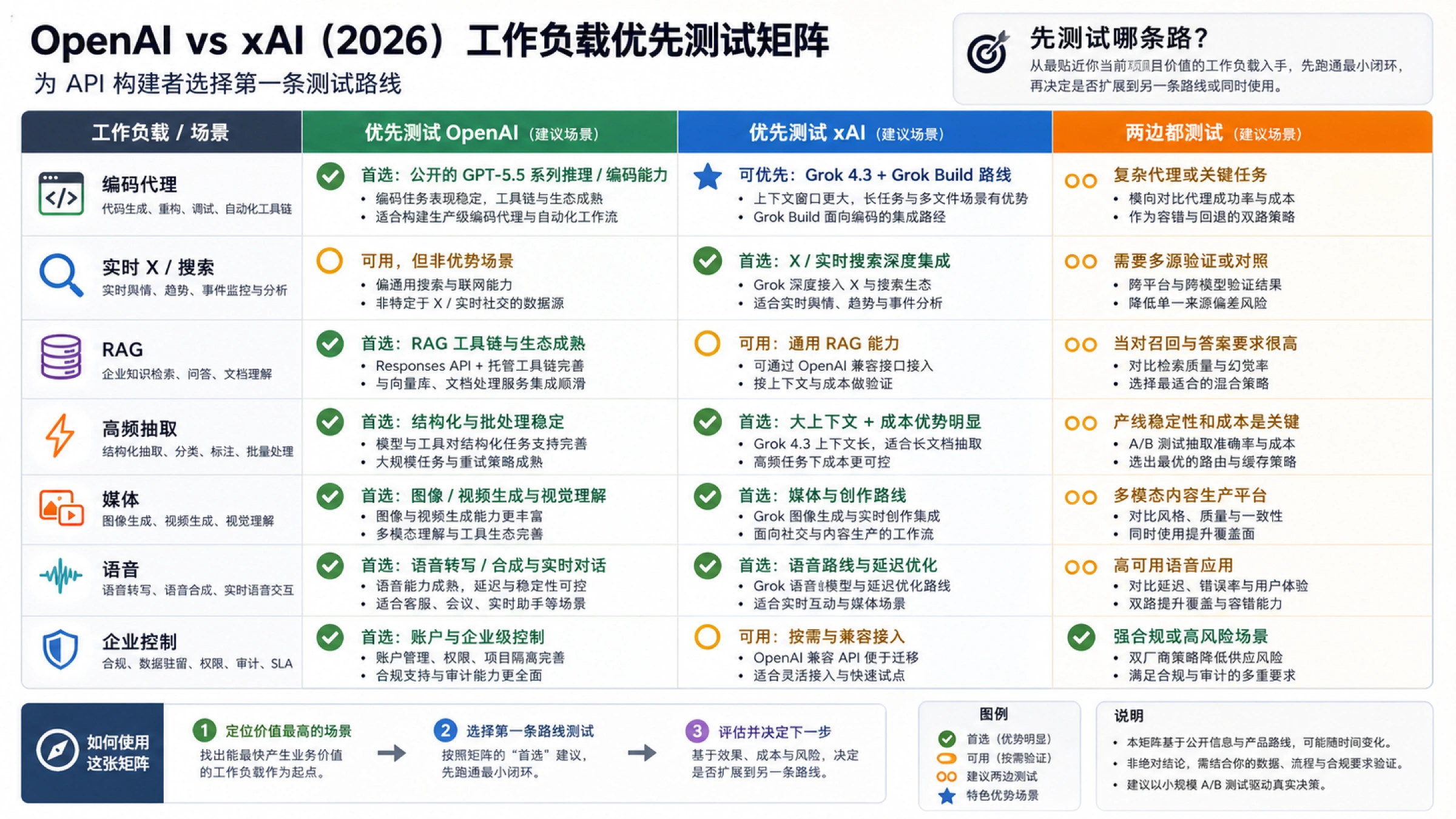
| 工作负载 | 先测 OpenAI | 先测 xAI | 常常两家都测 |
|---|---|---|---|
| 编码代理 | 需要 GPT-5.5 公开推理、成熟工具流、状态和企业运维。 | Grok Build 或 Grok 4.3 能以更低有效输出成本完成 repo 任务。 | review 时间、patch 接受率、工具轨迹决定真实成本。 |
| 实时 X/搜索分析 | 已依赖 OpenAI web/tooling,或需要 OpenAI 托管工具链。 | X Search 或 xAI 搜索工具是答案核心。 | 同时需要广义 web 背景和 X-native 信号。 |
| RAG 与企业搜索 | 需要 OpenAI 文件/搜索/账号控制。 | Grok 4.3 上下文和价格能减少检索复杂度。 | 长上下文、检索质量和拒绝行为都会影响可接受结果。 |
| 高量抽取 | Batch/Flex、mini/nano 或缓存让 OpenAI 足够便宜。 | Grok 4.3 基础价和 Batch 折扣降低有效输出成本。 | 输出校验、错误处理和策略阻断比 token 行更重要。 |
| 图像和视频 | 已使用 OpenAI 媒体 API 或需要 OpenAI 产品栈。 | Grok Imagine 正好拥有目标媒体路线。 | 用户可接受输出标准决定结果。 |
| 语音 | 需要 OpenAI realtime/audio 行为和既有工具。 | Grok Voice 质量、延迟和价格匹配产品。 | 延迟、打断、音色和转写准确率都要测。 |
| 监管或企业工作 | 账号控制、治理、支持和内部批准最关键。 | xAI 路线已被同一治理流程批准且可审计。 | 风险评审要求双供应商韧性或 fallback。 |
双供应商架构也有价值。OpenAI 可以负责复杂工具链、治理重请求和客户可见 fallback,xAI 可以负责成本敏感长上下文摘要、X/搜索分析或特定编码/媒体/语音任务。前提是先定义日志、成本上限、fallback、策略审查和支持 owner。
成本测算工作表
上线前先跑一个小型工作表,不要只复制价格页。选 20 到 50 个代表性任务,覆盖简单、困难、边界和会失败的请求。把同一批任务分别跑过 GPT-5.5 standard、可接受延迟下的 Batch/Flex、Grok 4.3、编码任务里的 Grok Build,以及需要搜索工具的 xAI 路线。
记录输入 token、输出 token、缓存资格、长上下文阈值、工具调用、重试、策略阻断和失败输出。标记的是“可采用输出”,不是“API 200”。再用当前 token 行、工具行和服务层级倍率计算请求成本、有效输出成本和运维成本。提示词、检索、工具或模型变更后要重算。
这个表不需要复杂,但必须分清三件事:请求成本是供应商账单;有效输出成本是每个可用结果的真实支出;运维成本是便宜路线失败更多、日志更弱或支持 owner 不清时出现的人工和工程时间。
还要把“便宜但不可控”的风险写进预算。一个低 token 单价路线如果需要更多 prompt 修补、更多人工审核、更复杂的 fallback、更多日志对账,最后可能比标价更高。相反,一个单价更高的路线如果能稳定通过工具调用、减少重试、让审计和支持更清楚,产品层面的单位成本可能更低。团队应该为每个供应商记录同一组指标:成功调用率、被采用输出率、平均人工处理时间、失败后恢复方式、支持联系人和账单归属。只有这些指标齐全,OpenAI 与 xAI 的价格比较才不是静态表格,而是能指导真实路由的生产预算。
上线前重查清单
价格、模型可用性和 preview 权限变化很快。任何公开推荐或生产路由上线前,都要重新核验:
| 重查项 | OpenAI owner 来源 | xAI owner 来源 |
|---|---|---|
| 模型可用性 | OpenAI API models 和模型页 | xAI model list 和模型页 |
| preview 状态 | GPT-5.6 help 或 launch 页面 | xAI beta 或特殊路线说明 |
| token 价格 | OpenAI pricing | xAI pricing |
| 缓存和长上下文 | OpenAI pricing/model pages | xAI model/pricing pages |
| 工具价格 | OpenAI tool/pricing pages | xAI tool/pricing pages |
| Batch/Priority/Flex | OpenAI 服务层级文档 | xAI pricing endpoint notes |
| API 形状 | OpenAI Responses docs | xAI quickstart/API reference |
| 媒体和语音 | OpenAI image/video/audio docs | xAI Imagine/Voice docs |
| provider 列表 | 只证明 provider 路线 | 只证明 provider 路线 |
第三方计算器可以帮助规划,但不能替代官方事实。如果 provider gateway 显示某个模型,而一方官方文档或你的账号没有显示,那条路线的账单、日志、支持和数据合同属于 provider。
常见问题
xAI 一定比 OpenAI 便宜吗?
不一定。标准文本 token 行上,Grok 4.3 比 GPT-5.5 便宜很多;但 OpenAI 的缓存、Batch/Flex、小模型、托管工具和运维适配会改变最终成本。xAI 的工具调用、Priority、媒体、语音、重试和策略阻断也会改变最终成本。应该比较有效输出成本。
GPT-5.6 是否已经是 OpenAI API 的普遍可用路线?
截至 2026 年 7 月 2 日核验的官方材料,不是。OpenAI 把 GPT-5.6 Sol、Terra、Luna 描述为 selected organizations 的 limited preview。公开规划应以 GPT-5.5 作为复杂工作负载基线,除非你的组织已经有明确预览权限。
xAI API 是否可以兼容 OpenAI SDK?
xAI 文档展示了用 OpenAI 风格 SDK 和 https://api.x.ai/v1 调用的方式,这能降低迁移摩擦。但模型 ID、工具、价格、策略、日志、支持和可用性仍然属于 xAI。生产前要测 streaming、工具调用、错误、重试和账单。
编码代理该选哪家?
需要成熟 Responses 流程、托管工具、企业控制和 GPT-5.5 公开推理时,先测 OpenAI。Grok Build 或 Grok 4.3 能以更低有效输出成本完成代码任务时,先测 xAI。严肃编码代理要比较可接受 patch、review 时间、工具轨迹和失败恢复。
实时搜索或 X 数据该选哪家?
如果答案核心是 X Search 或 xAI 搜索工具,xAI 值得先测。如果工作流已依赖 OpenAI web、文件/搜索工具或更广的 Responses 流程,OpenAI 值得先测。需要广义 web 和 X-native 信号时,做双供应商 proof。
初创公司是否应该同时用 OpenAI 和 xAI?
可以,但要有清晰路由。OpenAI 可以处理复杂工具链、治理请求和客户可见 fallback;xAI 可以处理长上下文摘要、X/搜索分析、部分编码、媒体或语音任务。双供应商上线前要定义日志、成本上限、fallback 和支持 owner。
provider 或 gateway 价格能替代官方价格吗?
不能。provider 页面只证明 provider 路线,不证明一方官方的可用性、价格、支持和生命周期。第一方比较表应优先使用 OpenAI 和 xAI owner 来源。
最稳妥的默认建议是什么?
需要成熟公开 API 生态和账号控制时先测 OpenAI;需要 Grok 4.3 成本/上下文、X/搜索、编码、媒体、语音或 OpenAI 兼容迁移时先测 xAI;GPT-5.6 只在获批预览时测试;最终按有效输出成本决定。