Gemini 3 Deep Think模式完全指南:原理、配置与最佳实践
深入解析Gemini 3 Deep Think深度思考模式的工作原理、API配置方法、性能基准对比及成本优化策略。包含Python/JS代码示例,助你掌握Google最强推理模型。

Google在Gemini 3系列中引入的Deep Think模式代表了大语言模型推理能力的重大突破。这一模式通过并行探索多个假设路径,在复杂数学、科学推理和逻辑问题上实现了远超传统模型的表现。在Humanity's Last Exam测试中达到41%的准确率,在ARC-AGI-2测试中更是以45.1%的成绩领先GPT-5.1两倍以上。
对于开发者和技术决策者而言,理解Deep Think的工作原理、正确配置API参数、以及在合适的场景中使用这一能力,将直接影响AI应用的质量和成本效益。本指南将从技术原理到实战代码,系统性地解析Deep Think模式的方方面面,帮助你充分利用这一强大的推理引擎。

Gemini 3 Deep Think模式核心解析
Deep Think是Gemini 3系列模型的高级推理模式,它通过并行探索多个假设路径来解决复杂问题,在数学、科学和逻辑推理任务上实现了突破性表现。
传统大语言模型在处理问题时采用线性推理方式,从输入直接生成输出,中间过程相对简单。Deep Think模式则根本性地改变了这一范式,它模拟人类专家面对难题时的思考方式:不急于给出答案,而是先提出多个可能的解题路径,对每条路径进行深入验证,最终选择最可靠的方案。
这种方法在Google官方公告中被描述为"advanced parallel reasoning"(高级并行推理)。具体而言,当你向Deep Think提交一个复杂数学问题时,模型内部可能同时探索代数方法、几何方法、数值方法等多条路径。每条路径都会进行多步推导,遇到矛盾或不一致时会回溯修正。最终,模型综合各路径的验证结果,选择最可靠的答案输出。
与普通模式相比,Deep Think的核心区别在于思考深度和资源消耗。普通模式追求快速响应,适合简单问答和日常对话;Deep Think则愿意花费更多时间和计算资源进行深度推理,因此更适合需要严谨分析的复杂任务。根据官方文档,Deep Think模式下的首token延迟可能达到普通模式的数倍,但输出质量显著提升。
目前,Deep Think功能在Gemini 3 Pro和Gemini 3 Flash两个模型上可用。Gemini 3 Pro的Deep Think能力更强,适合最复杂的推理任务;Gemini 3 Flash则在保持较强推理能力的同时,提供更快的响应速度和更低的成本,适合需要平衡质量与效率的场景。
Deep Think技术原理:并行假设与思维链
Deep Think采用System 2慢思考架构,同时测试多个解题假设,选择最优路径,类似人类专家的深度分析过程。
心理学家Daniel Kahneman提出的双系统理论将人类思维分为两种模式:System 1是快速、直觉的反应,而System 2是缓慢、深思熟虑的分析。传统大语言模型主要模拟System 1,而Deep Think则专门设计用于激活System 2式的深度推理。
思维链(Chain of Thought)机制是Deep Think的核心技术基础。模型在生成最终答案之前,会产生大量的内部推理token,这些token记录了模型的思考过程。根据官方技术文档,这些thinking tokens虽然不直接展示给用户,但会计入计费,因为它们代表了模型实际进行的计算工作。
Deep Think的独特之处在于并行假设探索。与传统的单一思维链不同,Deep Think同时维护多个假设分支。以解决一道竞赛数学题为例,模型可能同时探索以下路径:假设A使用代数恒等式变换,假设B尝试构造辅助函数,假设C采用数值逼近验证。每个假设都会独立推进,遇到矛盾时自动放弃,成功时记录验证结果。最终,模型综合所有成功路径的置信度,选择最可靠的答案。
这种架构直接继承自Google DeepMind在AlphaProof和AlphaGeometry项目中的成功经验。这些系统在国际数学奥林匹克竞赛中达到了金牌水平,证明了并行搜索与深度推理结合的有效性。Deep Think将这一能力整合到通用语言模型中,使其能够处理更广泛的问题类型。
从实现角度看,Deep Think的推理过程可以通过thought summaries(思考摘要)部分展示。设置include_thoughts=true后,API会返回模型的思考过程概要。这对于理解模型的决策逻辑、调试异常输出非常有价值。需要注意的是,返回的是摘要而非完整的内部推理链,完整的thinking tokens出于安全和商业考虑不对外公开。
性能基准测试:数据说话
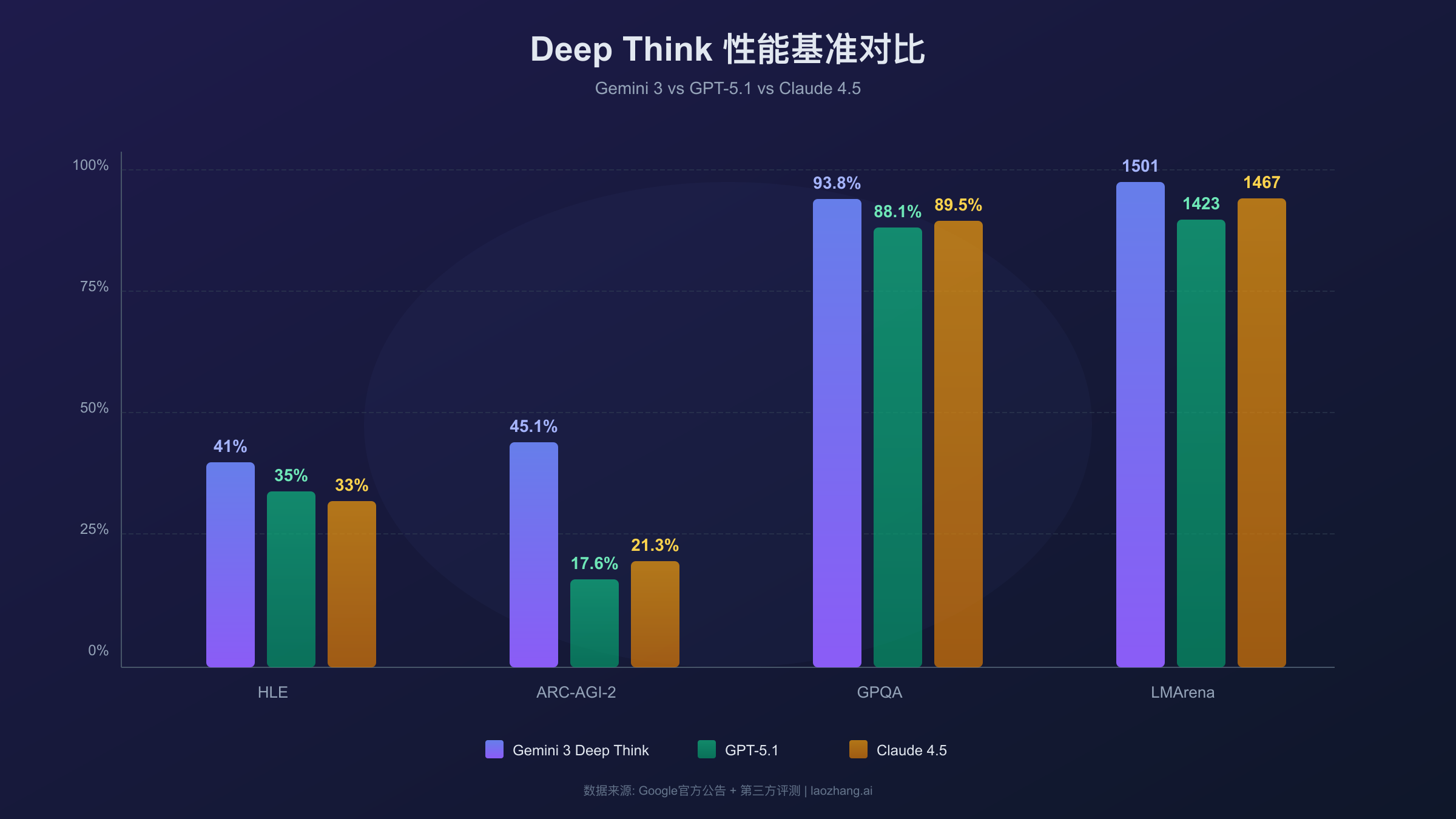
Deep Think在Humanity's Last Exam达到41%(行业最高),ARC-AGI-2达到45.1%(GPT-5.1的2.5倍),GPQA Diamond达到93.8%接近满分。
性能数据是评估AI模型能力最客观的标准。以下是Deep Think在主流基准测试中的表现,数据来源于Google官方公告和第三方评测机构:
| 基准测试 | Deep Think得分 | GPT-5.1得分 | Claude 4.5得分 | 说明 |
|---|---|---|---|---|
| Humanity's Last Exam | 41.0% | - | - | 行业最高,无工具辅助 |
| ARC-AGI-2 | 45.1% | 17.6% | 21.3% | 抽象推理,2.5倍领先 |
| GPQA Diamond | 93.8% | 88.1% | 89.5% | 科学知识问答 |
| LMArena Elo | 1501 | 1423 | 1467 | 首破1500分 |
Humanity's Last Exam是由AI安全研究者设计的极限测试,包含数学、物理、编程等领域的最难问题。41%的得分看似不高,但考虑到这是无工具辅助的纯推理结果,已经代表了当前AI的天花板水平。作为参考,该测试对人类专家的平均挑战性也相当高。
ARC-AGI-2测试抽象视觉推理能力,要求模型识别图案规律并进行外推。Deep Think的45.1%得分比GPT-5.1的17.6%高出近2.6倍,这一差距展示了并行假设探索在抽象推理任务上的显著优势。这类任务恰恰是传统语言模型的弱项,因为它们需要真正的"理解"而非模式匹配。
GPQA Diamond是研究生水平的科学问答测试,涵盖物理、化学、生物等学科的深度问题。93.8%的准确率已经接近人类专家水平(约89.8%),表明Deep Think在专业知识领域的推理能力已相当成熟。
值得注意的是,这些卓越表现是在特定模式下取得的。在标准模式(非Deep Think)下,Gemini 3的表现与其他顶级模型相当但并无压倒性优势。这说明Deep Think确实激活了额外的推理能力,而非简单的模型规模提升。
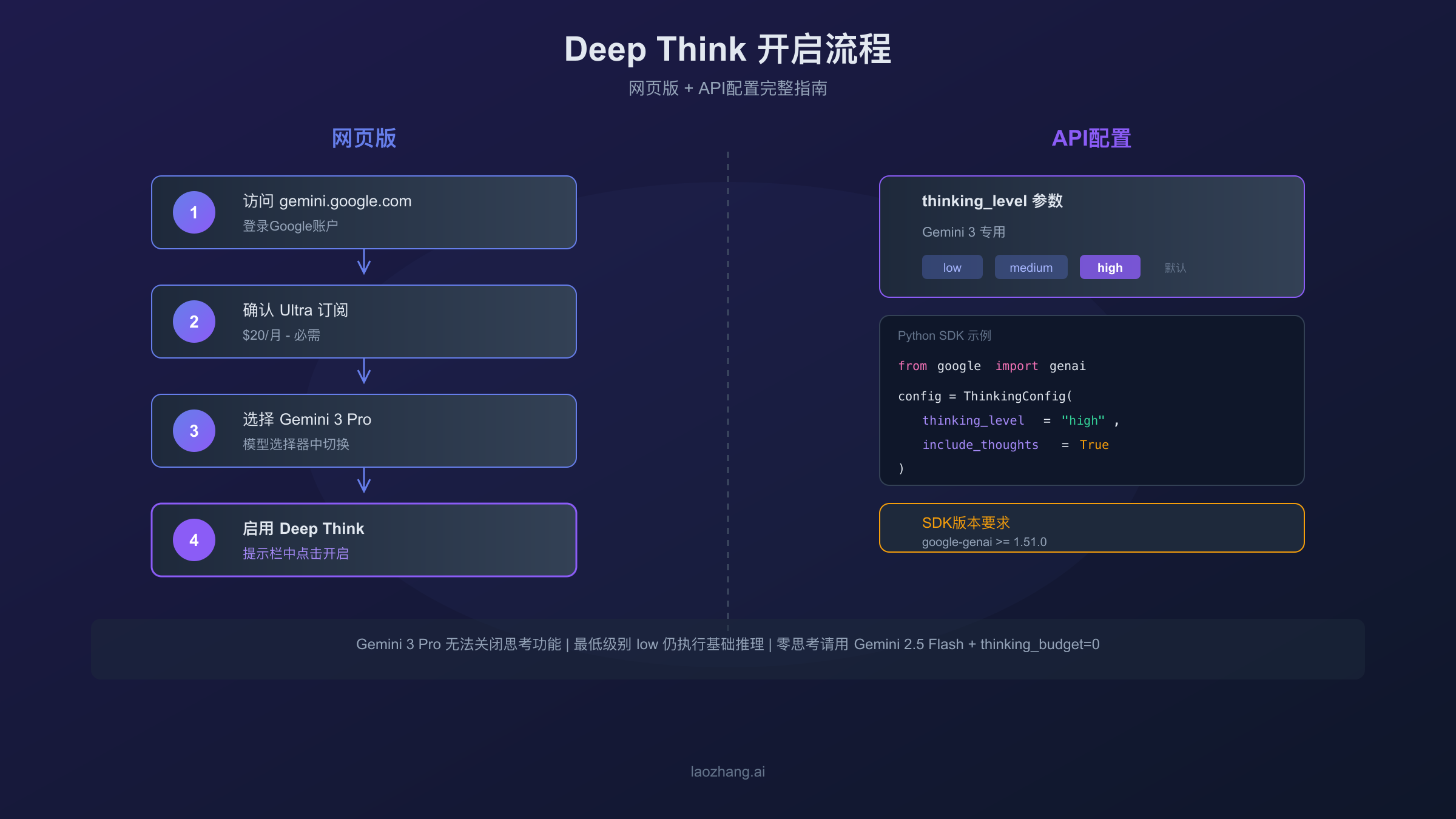
如何开启Deep Think模式
网页版在提示栏选择Deep Think并切换Gemini 3 Pro模型;API使用thinking_level参数控制推理深度,支持minimal、low、medium、high四个级别。
网页版开启方法
对于普通用户,最简单的体验方式是通过Gemini网页应用。目前Deep Think功能仅对Google AI Ultra订阅用户开放,订阅费用为每月20美元。开启步骤如下:
- 访问 gemini.google.com 并登录你的Google账户
- 确认你已订阅Google AI Ultra服务
- 在聊天输入框下方,点击模型选择器
- 选择"Gemini 3 Pro"模型
- 在提示栏中找到并启用"Deep Think"选项
- 输入你的问题并提交
需要注意的是,Deep Think模式的响应时间通常较长,复杂问题可能需要几分钟才能返回结果。在此期间,你可以离开当前对话,系统会在完成后发送通知。这种异步处理方式与传统的即时响应不同,但对于需要深度思考的复杂问题,等待是值得的。
API配置方法
对于开发者,通过API使用Deep Think需要理解thinking_level参数。这是Gemini 3系列专用的参数,用于控制模型的推理深度:
| thinking_level | 适用场景 | 延迟特性 | 成本影响 |
|---|---|---|---|
| minimal | Flash模型专用,最快响应 | 最低 | 最低 |
| low | 简单任务,日常对话 | 低 | 低 |
| medium | Flash模型专用,平衡选择 | 中等 | 中等 |
| high (默认) | 复杂推理,数学/代码 | 高 | 高 |
关键区别:Gemini 3 Pro默认使用high级别,且无法完全关闭思考功能,最低只能设为low。如果你需要零思考的快速响应,应选择Gemini 2.5 Flash并设置thinking_budget=0。
另一个重要参数是include_thoughts,设为true时API会返回模型的思考摘要,这对于调试和理解模型决策非常有用。
API开发完整指南
使用Python SDK只需设置thinking_config参数,支持thinking_level和include_thoughts两个关键配置项。SDK版本要求1.51.0或更高。
环境准备
在开始之前,确保你的开发环境满足以下要求:
- Python 3.9+ 或 Node.js 18+
- Google AI Python SDK ≥ 1.51.0(旧版本不支持thinking配置)
- 有效的Gemini API密钥
获取API密钥请访问 Google AI Studio,点击"Get API Key"创建。
Python代码示例
以下是一个完整的Python示例,展示如何使用Deep Think模式:
hljs pythonfrom google import genai
from google.genai import types
# 初始化客户端
client = genai.Client(api_key="YOUR_API_KEY")
# 配置Deep Think模式
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="证明:对于任意正整数n,n^3 + 2n 能被3整除",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="high", # 最大推理深度
include_thoughts=True # 返回思考摘要
)
)
)
# 处理响应
for part in response.candidates[0].content.parts:
if hasattr(part, 'thought') and part.thought:
print("=== 思考过程 ===")
print(part.text)
else:
print("=== 最终答案 ===")
print(part.text)
# 查看token使用情况
print(f"思考tokens: {response.usage_metadata.thoughts_token_count}")
print(f"输出tokens: {response.usage_metadata.candidates_token_count}")
JavaScript代码示例
对于前端或Node.js开发者,以下是等效的JavaScript实现:
hljs javascriptimport { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({ apiKey: "YOUR_API_KEY" });
async function deepThinkDemo() {
const response = await ai.models.generateContent({
model: "gemini-3-pro-preview",
contents: "设计一个O(n log n)的排序算法并证明其正确性",
config: {
thinkingConfig: {
thinkingLevel: "high",
includeThoughts: true
}
}
});
console.log(response.text);
}
deepThinkDemo();
cURL示例
如果你需要直接调用REST API,以下是cURL命令示例:
hljs bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{"parts": [{"text": "解释量子纠缠的物理原理"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}'
流式输出处理
对于需要实时显示思考过程的应用,可以使用流式API:
hljs pythonthoughts = ""
answer = ""
for chunk in client.models.generate_content_stream(
model="gemini-3-pro-preview",
contents="分析这段代码的时间复杂度...",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="high",
include_thoughts=True
)
)
):
for part in chunk.candidates[0].content.parts:
if not part.text:
continue
if hasattr(part, 'thought') and part.thought:
thoughts += part.text
print(f"[思考中] {part.text}")
else:
answer += part.text
print(part.text, end="", flush=True)
常见错误处理
使用Deep Think API时可能遇到以下问题:
错误:
thinkingLevel is not supported for this model原因: 使用了Gemini 2.5系列模型(应使用thinking_budget) 解决: 切换到gemini-3-pro-preview或gemini-3-flash-preview
错误:
SDK version too old原因: Python SDK版本低于1.51.0 解决: 执行pip install --upgrade google-genai
成本与定价深度分析
思考tokens按输出价格计费,Gemini 3 Pro为$12/1M tokens。输出成本包含可见回复和不可见的思考tokens,这一点与普通API调用有本质区别。
定价结构详解
Gemini 3的定价采用分层结构,且思考模式会显著影响成本。以下是官方定价明细:
| 模型 | 输入(≤200K) | 输入(>200K) | 输出(含思考) | 免费额度 |
|---|---|---|---|---|
| Gemini 3 Pro | $2.00/1M | $4.00/1M | $12.00/1M | 无 |
| Gemini 3 Flash | $0.50/1M | $0.50/1M | $3.00/1M | 有限 |
| Gemini 2.5 Flash | $0.30/1M | $0.30/1M | $2.50/1M | 有限 |
关键成本因素:输出价格包含了thinking tokens。当模型在Deep Think模式下工作时,可能产生数千甚至上万的思考tokens,这些都按输出价格计费。一个复杂问题可能产生8000 thinking tokens + 500输出tokens,总计8500 tokens按$12/1M计费。
实际成本计算示例
假设你使用Gemini 3 Pro处理一个复杂数学问题:
- 输入: 200 tokens(问题描述)
- 思考: 5000 tokens(内部推理)
- 输出: 800 tokens(最终答案)
成本计算:
- 输入成本: 200 × $2.00 / 1M = $0.0004
- 输出成本: (5000 + 800) × $12.00 / 1M = $0.0696
- 总成本: 约$0.07/次
如果每天处理100个类似问题,月成本约为$210。
成本优化策略
降低Deep Think成本的有效方法包括:
1. 按任务复杂度选择模型
对于中等复杂度的任务,Gemini 3 Flash可能是更具性价比的选择。它的输出成本仅为Pro的25%,而推理能力对大多数应用已足够。
2. 调整thinking_level
不是所有任务都需要high级别的思考。简单的代码解释用low即可,只有数学证明或复杂算法设计才需要high。
3. 使用Batch API
Batch API提供50%的折扣,适合非实时场景。批量处理100个问题可节省一半成本。
对于需要频繁调用Gemini API的开发者,laozhang.ai提供与官方一致的定价,同时支持统一接口切换多种模型。这种灵活性对于需要对比不同模型效果的开发场景尤其有价值。当然,如果只是偶尔测试,官方的免费额度可能已经足够使用。更多Gemini API定价细节和免费额度信息可参考相关指南。
最佳实践:场景化使用建议
Deep Think适合复杂数学、代码调试、科学分析;不适合简单问答、高频调用场景。选择正确的使用场景是获得最佳投入产出比的关键。
最适合Deep Think的场景
数学证明与推导是Deep Think的强项。当你需要证明一个数学定理、求解复杂方程或进行符号计算时,Deep Think的并行假设探索能力可以显著提高成功率。例如,证明"任意连续函数在闭区间上必有界"这类需要严密逻辑链的问题。
代码调试与算法优化同样适合Deep Think。面对一个隐蔽的bug,模型可以同时考虑多种可能原因:内存泄漏、竞态条件、边界情况等。这种多路径探索比单一假设更容易找到根本原因。
科学分析与研究是另一个典型场景。分析实验数据的异常、推导物理公式、设计化学合成路径等任务都需要深度推理,Deep Think能提供接近专家水平的分析能力。
复杂决策规划如系统架构设计、商业策略分析等,需要权衡多种因素并预测潜在后果,Deep Think的多假设评估机制正好适用。
不适合Deep Think的场景
简单问答和日常对话使用Deep Think是浪费资源。询问"今天天气如何"或"Python如何读取文件"这类问题,普通模式足够且响应更快。
高频率API调用场景需谨慎。如果你的应用每分钟需要处理数百个请求,Deep Think的延迟和成本都不适合。考虑使用Gemini 2.5 Flash配合thinking_budget=0。
实时交互应用如聊天机器人,用户期望即时回复。Deep Think可能需要数秒到数分钟才能响应,这会严重影响用户体验。
Prompt优化技巧
即使在Deep Think模式下,良好的prompt仍能显著提升效果:
根据官方指南,Gemini 3对简洁直接的指令响应更好。避免冗长的prompt工程技巧,直接说明目标即可。例如,"证明这个定理"比"请你扮演一个数学家,认真思考..."更有效。
指定输出格式有助于引导模型。"先给出证明过程,然后总结关键步骤"这样的指令会让输出更有结构。
对于复杂问题,提供足够的上下文和约束条件。例如解决编程问题时,说明使用的语言版本、已尝试的方法、报错信息等,都能帮助模型更准确地定位问题。
Deep Think vs Claude vs GPT:如何选择
Gemini适合多模态和快速迭代,Claude适合代码审查和长文分析,GPT适合通用对话。理解每个模型的优势有助于做出正确选择。
能力对比分析
当前三大顶级推理模型各有特色:
| 维度 | Gemini 3 Deep Think | Claude 4.5 | GPT-5.1 |
|---|---|---|---|
| 数学推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 代码生成 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 多模态理解 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 长文分析 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 响应速度 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Gemini 3 Deep Think的核心优势在于极致的推理深度和多模态能力。如果你的任务涉及数学证明、科学推理,或需要同时处理图像、视频和文本,Gemini是首选。它的1M token上下文窗口也是目前最大的。
Claude 4.5在代码审查和长文档分析上表现卓越。根据多方评测,Claude生成的代码更可靠、文档更清晰、幻觉更少。如果你需要审查现有代码、编写技术文档或进行安全分析,Claude可能更适合。它的推理过程可追溯性也更好,便于审计。
GPT-5.1的优势在于通用性和生态系统。如果你需要与现有OpenAI工具链集成,或任务涉及广泛的知识领域而非深度推理,GPT是成熟的选择。
场景化选择建议
选择Gemini Deep Think当:需要解决数学或科学问题、处理多模态内容、需要超长上下文、追求极致推理质量。
选择Claude当:进行代码审查或重构、编写长文档、需要可解释的推理过程、对安全和合规有较高要求。
选择GPT当:需要快速原型开发、与OpenAI生态集成、处理通用对话任务、成本敏感且任务简单。
许多资深开发者的实践是组合使用多个模型。一个常见模式是:用Claude做规划和代码审查,用Gemini处理复杂推理和多模态任务,用GPT处理日常交互。这种分工能最大化每个模型的优势。
如需深入了解Claude的使用,可参考我们的Claude最佳实践指南。
中国用户使用指南
由于网络限制,中国用户无法直接访问Gemini API。通过中转服务或特定网络配置可以解决这一问题,延迟可从200ms+降至20ms左右。
访问限制说明
Gemini API目前在中国大陆、香港等地区受到访问限制。直接调用官方API endpoint会遇到连接超时或403错误。这不是API配额问题,而是网络层面的地理限制。
解决方案
方案一:网络代理配置
如果你有境外服务器资源,可以配置代理转发API请求。这需要一定的技术基础,且需要确保代理服务器的稳定性和安全性。
方案二:使用中转服务
对于希望快速接入的开发者,laozhang.ai等中转服务提供了便捷的解决方案。这类服务的原理是通过其境外服务器中转API请求,对用户表现为标准的OpenAI兼容接口。
使用中转服务的典型代码示例:
hljs pythonfrom openai import OpenAI
client = OpenAI(
api_key="sk-YOUR_API_KEY", # 从中转服务获取
base_url="https://api.laozhang.ai/v1"
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": "你好"}],
extra_body={
"google": {
"thinking_config": {
"thinking_level": "high"
}
}
}
)
中转服务的优势包括:延迟更低(国内节点约20ms vs 官方200ms+)、支持多模型统一接口、无需自行维护代理。需要注意的是,这类服务涉及第三方信任,敏感数据的处理需谨慎评估。建议在重要项目中同时保留官方API作为备用方案。
更多关于中国访问Gemini的方案可参考专题指南。
常见问题解答
Deep Think模式和普通模式有什么本质区别?
普通模式追求快速响应,采用线性推理直接生成答案。Deep Think模式则进行并行假设探索,同时测试多条解题路径后选择最优解。这导致Deep Think响应更慢但质量显著更高,特别是在复杂推理任务上。技术上,Deep Think会产生大量thinking tokens用于内部推理,这些token计入计费但不直接展示给用户。
Gemini 3 Pro和Flash的Deep Think有什么区别?
两者的核心区别在于能力深度和成本。Gemini 3 Pro的Deep Think更强大,适合最复杂的任务,但成本更高($12/1M输出tokens)且无法完全关闭思考。Gemini 3 Flash提供平衡选择,支持minimal到high四个思考级别,成本仅为Pro的25%,适合大多数应用场景。选择建议:极限推理用Pro,日常使用选Flash。
thinking_level和thinking_budget有什么区别?
这是两个不同系列模型使用的参数,不可混用。thinking_level是Gemini 3系列专用参数,取值为minimal/low/medium/high,控制推理"深度级别"。thinking_budget是Gemini 2.5系列专用参数,取值为具体token数量(0-32768),控制推理"资源预算"。使用错误的参数会返回400错误。
Deep Think模式响应太慢怎么办?
首先确认是否真正需要Deep Think。如果任务简单,降级到普通模式或使用thinking_level=low。对于必须使用Deep Think的复杂任务,接受其本身需要更多时间的特性。在网页端可以提交后离开等待通知,在API端可以实现异步处理。如果延迟主要来自网络,中国用户可考虑使用低延迟的中转服务。
如何查看模型的思考过程?
设置include_thoughts=true参数,API会返回模型的思考摘要(thought summaries)。这些摘要展示了模型的推理路径和关键决策点,对调试异常输出非常有帮助。注意这只是摘要,完整的thinking tokens出于安全考虑不对外公开。在响应对象中,带有thought=True标记的part就是思考内容。
Ultra订阅值得吗?
这取决于你的使用场景。如果你是重度Gemini用户,每月处理大量复杂推理任务,$20/月的Ultra订阅提供了无限网页端Deep Think使用,性价比很高。如果只是偶尔使用或主要通过API调用,按量付费可能更经济。API调用不包含在Ultra订阅中,需要单独付费。
Gemini 3 Deep Think模式代表了AI推理能力的重要突破。通过本指南,你应该已经掌握了它的工作原理、配置方法和最佳实践。无论是解决复杂数学问题、调试棘手代码还是进行深度科学分析,Deep Think都能提供强大的支持。关键是选择合适的场景和配置,平衡质量与成本,让这一能力真正为你的工作创造价值。
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图