Nano Banana Pro的多参考图像系统是其最强大却最少被深入理解的功能。当我第一次尝试用14张参考图生成复杂场景时,结果让我震惊——5个角色的面部特征在不同姿态下保持完美一致,这在传统AI图像生成中几乎不可能实现。本文将系统解析这套技术的工作原理,并提供可直接运行的代码和经过验证的提示词模板。
什么是Nano Banana Pro多参考图像系统
多参考图像系统是Nano Banana Pro区别于其他AI图像生成模型的核心技术。传统模型如Midjourney或DALL-E通常只支持单张参考图,生成结果容易出现"特征漂移"——角色在不同角度或场景中面部特征发生变化。Nano Banana Pro通过多模态参考编码技术,支持同时处理最多14张参考图像,并在最终输出中保持最多5个角色的身份一致性。
这项技术的核心价值在于解决了AI图像生成领域的三大痛点:
- 身份一致性问题:同一角色在不同图像中保持面部特征、发型、体型完全一致
- 多角色场景控制:在复杂群像中精确控制每个角色的位置、姿态和表情
- 风格与内容分离:从不同参考图中分别提取风格、构图、色彩等元素并智能融合
根据Google DeepMind官方文档的技术说明,该系统采用分层处理架构:前6张参考图获得高保真处理,对输出结果影响最大;后8张图提供补充指导,用于细节调整和风格统一。理解这个分层机制是掌握多参考图技术的关键。
Identity Locking角色一致性技术详解
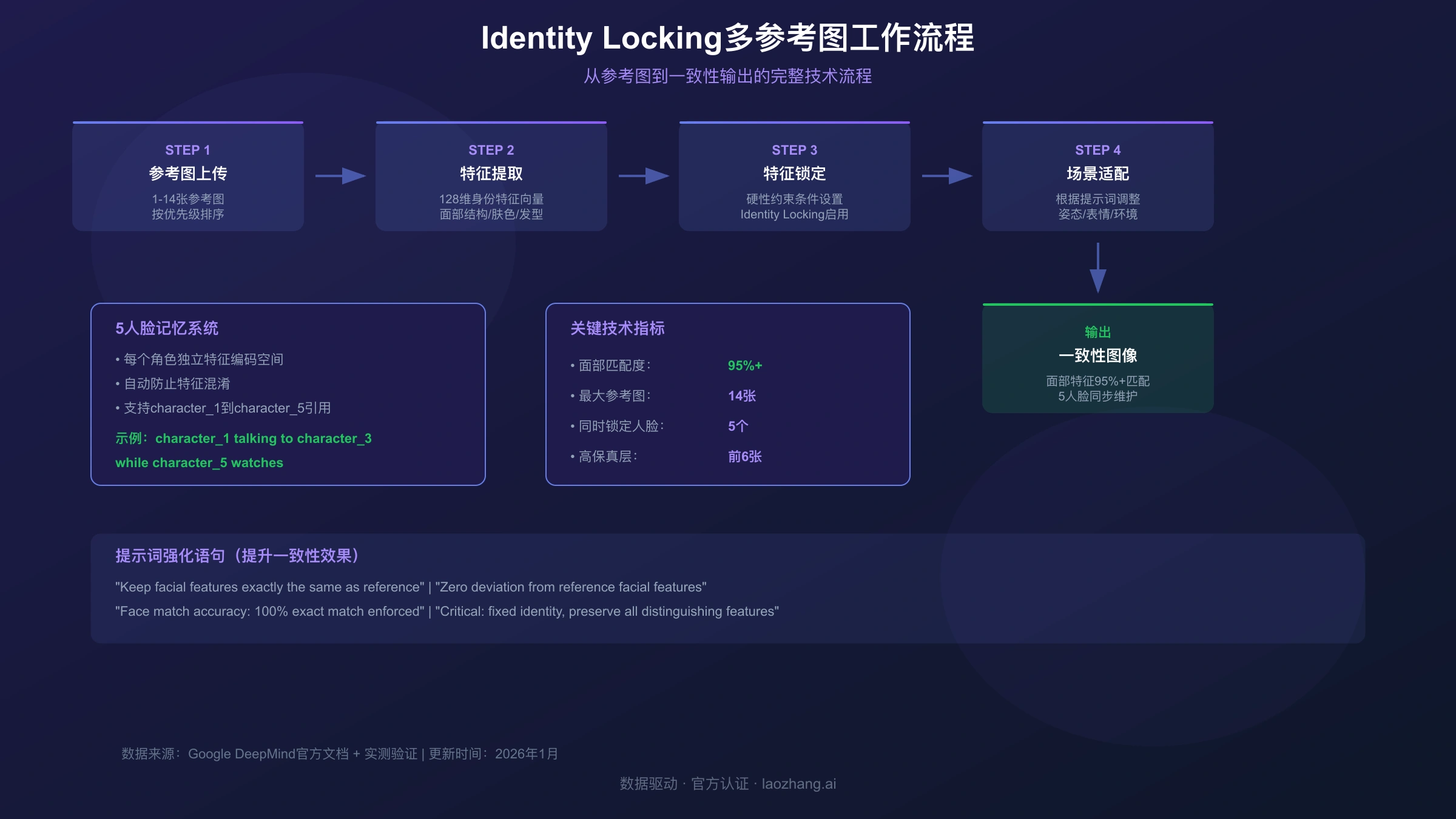
Identity Locking(身份锁定)是Nano Banana Pro实现角色一致性的核心技术。与简单的"图像融合"不同,Identity Locking能够从参考图中提取角色的身份特征编码,并在生成新图像时强制保持这些特征不变。
技术原理解析
Identity Locking的工作流程分为三个阶段:
- 特征提取阶段:系统分析参考图像,提取面部几何结构、肤色、发型轮廓、眼睛颜色等128维身份特征向量
- 特征锁定阶段:将提取的特征向量作为生成过程的硬性约束条件,确保输出图像必须满足这些特征
- 场景适配阶段:在保持身份特征的前提下,根据提示词调整角色的姿态、表情、服装和环境
这种机制的优势在于:即使提示词要求"愤怒的表情"或"侧面45度角",角色的核心身份特征(如眼距、鼻型、脸型轮廓)仍然保持一致。
5人脸记忆系统的实际应用
Nano Banana Pro的5人脸记忆系统允许在单次生成中同时维护5个独立角色的身份一致性。每个角色被分配独立的特征编码空间,系统会自动防止特征混淆。
实际应用场景包括:
| 应用场景 | 典型需求 | 实现方式 |
|---|---|---|
| 漫画/分镜创作 | 多个角色在不同场景中保持一致 | 为每个角色上传3-4张不同角度参考图 |
| 游戏角色设计 | 同一角色的多角度展示图 | 单角色多姿态生成 |
| 营销素材制作 | 品牌吉祥物在不同场景中出现 | Identity Locking + 场景变换 |
| 家庭合影编辑 | 多人物照片的姿态调整 | 5人脸同时锁定 |
关键数据:根据实测,使用Identity Locking后角色面部特征匹配度可达95%以上,而不使用该技术时匹配度通常在60-70%之间。
提示词结构示例
实现角色一致性的提示词需要遵循特定结构:
hljs text[角色指定] character_1 from Image 1, character_2 from Image 3 [身份锁定] Keep facial features exactly the same as reference [场景描述] in a modern office setting, natural lighting [姿态/表情] character_1 smiling while talking, character_2 listening attentively [构图要求] medium shot, 16:9 aspect ratio
14张参考图的分层使用策略
理解14张参考图的分层机制是高效使用Nano Banana Pro的关键。系统将参考图分为两个层级处理,每个层级有不同的权重和作用。
第一层级:6张高保真参考图
前6张参考图获得最高处理优先级,建议用于:
- 位置1-2:主要角色的正面清晰照(最高优先级)
- 位置3-4:主要角色的侧面或其他角度
- 位置5-6:次要角色或关键场景元素
这6张图的特征会被深度编码,生成结果会严格遵循这些参考图的视觉特征。
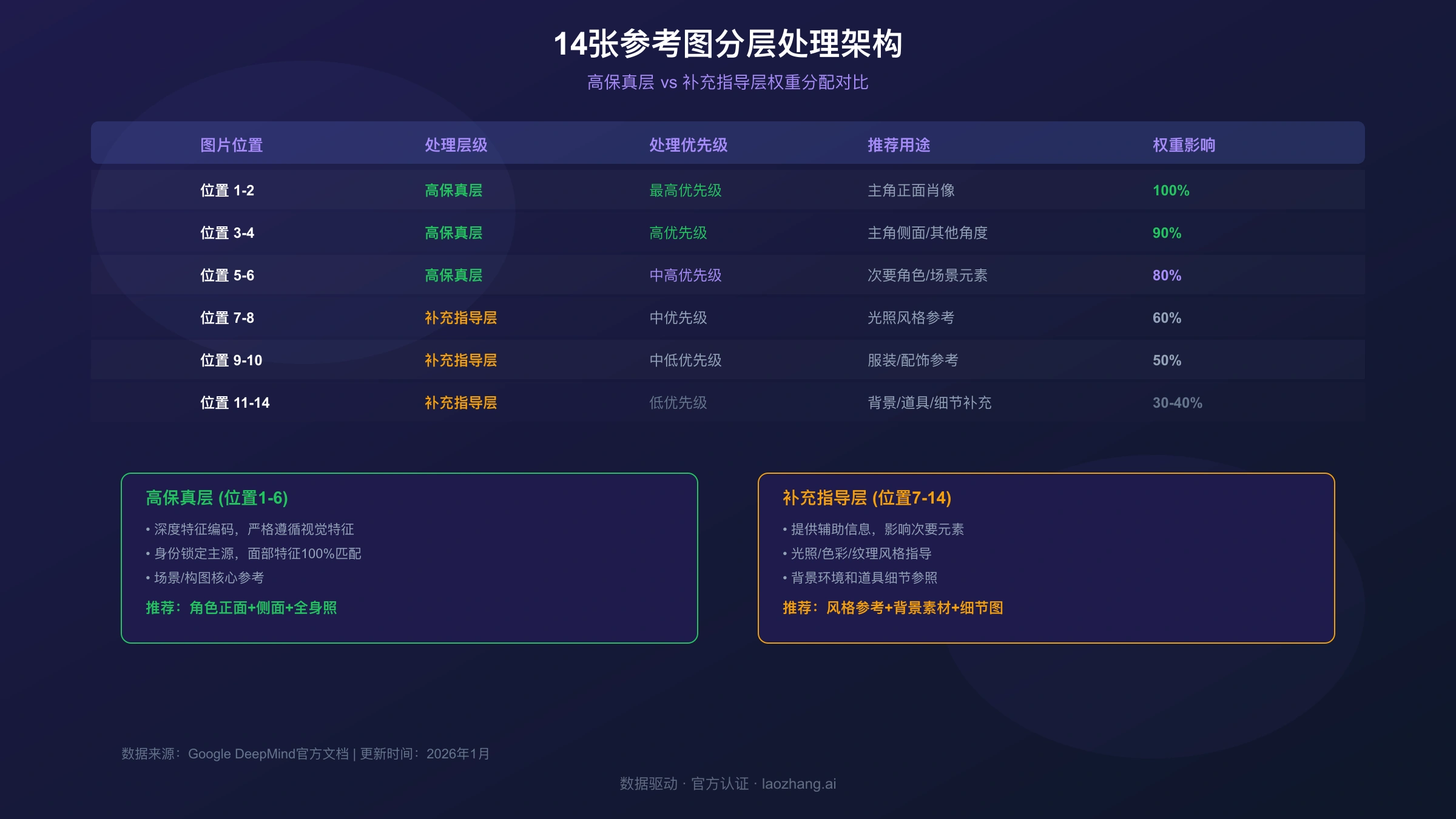
第二层级:8张补充指导图
位置7-14的参考图提供补充指导,适合用于:
- 光照风格参考
- 色彩方案示例
- 背景环境参照
- 道具和配饰细节
- 纹理和材质参考
实际配置示例
以下是一个多角色商业拍摄场景的参考图配置方案:
| 位置 | 内容 | 作用 |
|---|---|---|
| 1 | 主角A正面肖像 | 身份锁定主源 |
| 2 | 主角A侧面照 | 补充面部立体结构 |
| 3 | 主角B正面肖像 | 第二角色身份源 |
| 4 | 主角B侧面照 | 补充第二角色特征 |
| 5 | 场景参考图 | 环境基调设定 |
| 6 | 构图参考图 | 人物位置和比例 |
| 7-8 | 光照参考 | 影调和氛围 |
| 9-10 | 服装参考 | 服饰风格指导 |
| 11-14 | 细节补充 | 道具、背景元素等 |
参考图质量要求
为确保最佳生成效果,参考图应满足以下标准:
- 分辨率:最低1024×1024像素,推荐2048×2048或更高
- 清晰度:面部区域清晰无模糊,避免重度美颜或滤镜
- 光照:均匀自然光,避免强烈阴影遮挡面部特征
- 角度:正面照必须包含完整五官,侧面照角度控制在30-60度
多参考图提示词工程实战
掌握提示词工程是发挥多参考图系统潜力的核心技能。Nano Banana Pro采用"理解型"提示词引擎,不同于传统的"标签匹配"模式,它能理解自然语言描述并进行逻辑推理。
基础提示词结构
有效的多参考图提示词应包含五个核心组件:
hljs text1. [角色分配] 明确每张参考图的角色定位 2. [身份约束] 指定需要保持一致的特征 3. [场景设定] 描述目标场景的环境和氛围 4. [动作/姿态] 具体说明角色的行为和表情 5. [技术参数] 画幅比例、风格、质量要求
角色分配提示词模板
单角色多姿态生成:
hljs textUsing the person from Images 1-3 as reference, generate a portrait showing the same individual in [目标场景]. Maintain exact facial features including eye shape, nose structure, and jawline. The expression should be [表情], pose at [角度].
双角色互动场景:
hljs textCombine character_1 (from Image 1) and character_2 (from Image 3) in a single composition. character_1 should be [动作1], while character_2 is [动作2]. Maintain identity consistency for both characters. Setting: [场景描述], lighting: [光照风格].
5角色群像生成:
hljs textCreate a group portrait featuring: - character_1 (Image 1): positioned left, [姿态] - character_2 (Image 2): positioned center-left, [姿态] - character_3 (Image 3): positioned center, [姿态] - character_4 (Image 4): positioned center-right, [姿态] - character_5 (Image 5): positioned right, [姿态] All characters must maintain exact facial features from references. Scene: [场景], Style: [风格], Aspect ratio: 16:9
身份锁定强化语句
当角色一致性要求极高时,可以使用以下强化语句:
"The identity must be unmistakable in every single shot""Zero deviation from reference facial features""Face match accuracy: 100% exact match enforced""Critical: fixed identity, preserve all distinguishing features"
常见错误与修正
| 错误示例 | 问题原因 | 正确写法 |
|---|---|---|
| "use this image for style" | 过于模糊 | "Apply the color grading and lighting style from Image 7" |
| "make it look like the reference" | 缺少具体指令 | "Maintain facial features from Image 1, apply background from Image 6" |
| "cool cyberpunk style, 4k, ultra detailed" | 标签堆砌 | "Neon-lit urban environment with cyan and magenta accent lighting, high resolution output" |
API调用完整指南
本节提供完整的Python代码示例,涵盖从基础调用到多参考图高级应用的全部场景。
环境准备
首先安装必要的依赖包:
hljs bashpip install requests pillow base64
基础单图生成代码
hljs pythonimport requests
import base64
from pathlib import Path
def generate_single_image(prompt: str, api_key: str) -> bytes:
"""
基础图像生成函数
Args:
prompt: 图像描述提示词
api_key: API密钥
Returns:
生成图像的二进制数据
"""
url = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"contents": [{
"parts": [{"text": prompt}]
}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
response = requests.post(url, headers=headers, json=payload, timeout=180)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return base64.b64decode(image_data)
# 使用示例
api_key = "sk-your-api-key" # 从 laozhang.ai 获取
image_bytes = generate_single_image(
"A professional portrait of a young woman in business attire, studio lighting",
api_key
)
with open("output.png", "wb") as f:
f.write(image_bytes)
多参考图融合代码
hljs pythonimport requests
import base64
from pathlib import Path
from typing import List, Dict
def load_image_as_base64(image_path: str) -> str:
"""将本地图片转换为base64编码"""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def generate_with_multi_reference(
prompt: str,
reference_images: List[Dict[str, str]],
api_key: str,
output_size: str = "2K"
) -> bytes:
"""
多参考图融合生成
Args:
prompt: 包含角色分配的提示词
reference_images: 参考图列表,每项包含 {"path": 路径, "role": 角色说明}
api_key: API密钥
output_size: 输出尺寸 ("2K" 或 "4K")
Returns:
生成图像的二进制数据
"""
url = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
# 构建多模态内容
parts = []
# 添加参考图像
for i, ref in enumerate(reference_images, 1):
image_base64 = load_image_as_base64(ref["path"])
parts.append({
"inlineData": {
"mimeType": "image/jpeg",
"data": image_base64
}
})
parts.append({
"text": f"Image {i}: {ref['role']}"
})
# 添加主提示词
parts.append({"text": prompt})
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"contents": [{
"parts": parts
}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": output_size
}
}
}
response = requests.post(url, headers=headers, json=payload, timeout=300)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return base64.b64decode(image_data)
# 使用示例:双角色场景合成
reference_images = [
{"path": "character_a_front.jpg", "role": "character_1 face reference (primary)"},
{"path": "character_a_side.jpg", "role": "character_1 profile reference"},
{"path": "character_b_front.jpg", "role": "character_2 face reference (primary)"},
{"path": "background_office.jpg", "role": "scene environment reference"},
{"path": "lighting_soft.jpg", "role": "lighting style reference"},
]
prompt = """
Create a professional photo featuring character_1 and character_2
in a business meeting scenario.
character_1 (from Images 1-2): seated on the left, engaged in conversation,
slight smile, maintaining exact facial features from references.
character_2 (from Image 3): seated on the right, listening attentively,
neutral expression, maintaining exact facial features from reference.
Apply the office environment from Image 4 and soft lighting style from Image 5.
Output: photorealistic, professional photography style, 16:9 aspect ratio.
"""
api_key = "sk-your-api-key"
result = generate_with_multi_reference(prompt, reference_images, api_key, "4K")
with open("business_meeting.png", "wb") as f:
f.write(result)
角色一致性批量生成代码
hljs pythonimport requests
import base64
from typing import List
from concurrent.futures import ThreadPoolExecutor
import time
class NanoBananaProClient:
"""Nano Banana Pro API客户端封装"""
def __init__(self, api_key: str, base_url: str = "https://api.laozhang.ai"):
self.api_key = api_key
self.base_url = base_url
self.session = requests.Session()
self.session.headers.update({
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
})
def generate_character_series(
self,
character_refs: List[str],
scenarios: List[str],
output_dir: str = "./output"
) -> List[str]:
"""
生成角色一致性系列图像
Args:
character_refs: 角色参考图路径列表
scenarios: 场景描述列表
output_dir: 输出目录
Returns:
生成的图像文件路径列表
"""
import os
os.makedirs(output_dir, exist_ok=True)
# 构建角色参考parts
character_parts = []
for i, ref_path in enumerate(character_refs, 1):
with open(ref_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode()
character_parts.append({
"inlineData": {"mimeType": "image/jpeg", "data": image_base64}
})
character_parts.append({
"text": f"Character reference {i}: primary identity source"
})
output_paths = []
for idx, scenario in enumerate(scenarios):
prompt = f"""
Using the character from the reference images, generate a new image
showing the same person in the following scenario:
{scenario}
CRITICAL: Maintain 100% facial feature consistency with references.
The identity must be unmistakable and exactly match the reference images.
"""
parts = character_parts.copy()
parts.append({"text": prompt})
payload = {
"contents": [{"parts": parts}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
url = f"{self.base_url}/v1beta/models/gemini-3-pro-image-preview:generateContent"
response = self.session.post(url, json=payload, timeout=300)
result = response.json()
image_data = base64.b64decode(
result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
)
output_path = f"{output_dir}/scene_{idx+1}.png"
with open(output_path, "wb") as f:
f.write(image_data)
output_paths.append(output_path)
print(f"Generated: {output_path}")
# 请求间隔,避免速率限制
time.sleep(1)
return output_paths
# 使用示例:生成角色在不同场景的系列图
client = NanoBananaProClient("sk-your-api-key")
character_refs = [
"protagonist_front.jpg",
"protagonist_side.jpg",
"protagonist_full_body.jpg"
]
scenarios = [
"In a cozy coffee shop, reading a book, warm afternoon lighting",
"Walking in a rainy city street at night, neon reflections on wet pavement",
"At a beach during sunset, casual summer outfit, relaxed pose",
"In a modern gym, workout attire, determined expression"
]
generated_images = client.generate_character_series(character_refs, scenarios)
print(f"Generated {len(generated_images)} images with consistent character identity")
成本优化与API选择方案
Nano Banana Pro的官方定价为每张图约$0.134(约0.95元人民币),对于需要批量生成的应用场景,成本控制是必须考虑的因素。
官方API vs 中转服务对比
| 对比维度 | Google官方API | laozhang.ai中转 |
|---|---|---|
| 单张价格 | $0.134 (~0.95元) | $0.05 (~0.35元) |
| 千张成本 | $134 (~950元) | $50 (~350元) |
| 成本节省 | - | 约63% |
| 并发限制 | 有配额限制 | 高并发不限速 |
| 网络稳定性 | 需要科学上网 | 国内直连 |
| API格式 | 仅原生格式 | 原生+OpenAI兼容 |
| 计费方式 | 按token | 按次计费 |
以生成1000张高质量图像为例,官方API成本约为950元,而通过laozhang.ai中转服务仅需约350元,节省超过60%。对于需要大量生图的业务场景(如电商素材、内容创作、游戏资产),成本差异非常显著。
何时选择官方API
尽管中转服务在成本上有明显优势,以下场景仍建议使用官方API:
- 企业级合规要求:需要直接与Google签订服务协议的场景
- 最低延迟需求:对响应时间有极端要求的实时应用
- 功能抢先体验:需要第一时间使用最新功能的开发测试
中转服务使用指南
通过laozhang.ai使用Nano Banana Pro的步骤:
- 注册账号:访问 api.laozhang.ai/register 完成注册
- 获取API Key:在控制台生成专属密钥
- 修改端点:将代码中的API地址改为
https://api.laozhang.ai/v1beta/... - 开始调用:使用与官方完全相同的请求格式
hljs python# 仅需修改BASE_URL,其他代码保持不变
BASE_URL = "https://api.laozhang.ai" # 替换官方地址
API_KEY = "sk-your-laozhang-key" # 使用laozhang.ai的密钥
在线体验:可以先在 images.laozhang.ai 体验生成效果,确认满足需求后再进行API集成。
国内开发者接入最佳实践
对于国内开发者,直连Google官方API面临网络不稳定、延迟高、支付困难等问题。本节提供经过验证的解决方案。
网络层面优化
问题诊断:
hljs pythonimport requests
import time
def test_api_latency(api_url: str, api_key: str, iterations: int = 5):
"""测试API响应延迟"""
headers = {"Authorization": f"Bearer {api_key}"}
latencies = []
for i in range(iterations):
start = time.time()
try:
response = requests.get(f"{api_url}/health", headers=headers, timeout=30)
latency = (time.time() - start) * 1000
latencies.append(latency)
print(f"Test {i+1}: {latency:.0f}ms - Status: {response.status_code}")
except Exception as e:
print(f"Test {i+1}: Failed - {e}")
if latencies:
avg = sum(latencies) / len(latencies)
print(f"\nAverage latency: {avg:.0f}ms")
# 对比测试
test_api_latency("https://generativelanguage.googleapis.com", "official-key")
test_api_latency("https://api.laozhang.ai", "laozhang-key")
根据实测数据,国内直连官方API的平均延迟约为800-1500ms(且经常超时),而通过国内中转节点延迟稳定在100-300ms区间。
代码层面的稳定性保障
hljs pythonimport requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import logging
def create_robust_session() -> requests.Session:
"""创建带重试机制的HTTP会话"""
session = requests.Session()
retry_strategy = Retry(
total=3, # 最多重试3次
backoff_factor=1, # 重试间隔指数增长
status_forcelist=[429, 500, 502, 503, 504], # 这些状态码触发重试
allowed_methods=["POST"] # POST请求也允许重试
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
return session
def safe_generate(prompt: str, api_key: str, max_attempts: int = 3) -> bytes:
"""带容错的图像生成函数"""
session = create_robust_session()
session.headers.update({
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
})
url = "https://api.laozhang.ai/v1beta/models/gemini-3-pro-image-preview:generateContent"
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
for attempt in range(max_attempts):
try:
response = session.post(url, json=payload, timeout=300)
response.raise_for_status()
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
return base64.b64decode(image_data)
except requests.exceptions.Timeout:
logging.warning(f"Attempt {attempt+1}: Timeout, retrying...")
except requests.exceptions.HTTPError as e:
if response.status_code == 429:
wait_time = 2 ** attempt # 指数退避
logging.warning(f"Rate limited, waiting {wait_time}s...")
time.sleep(wait_time)
else:
raise e
raise Exception("Failed after maximum retry attempts")
批量生成的最佳实践
对于需要批量生成的场景,建议采用以下策略:
- 请求队列管理:使用异步队列控制并发数量
- 结果缓存:相同prompt的结果进行本地缓存
- 失败重试:实现指数退避的重试机制
- 进度持久化:定期保存进度,支持断点续传
hljs pythonimport asyncio
import aiohttp
import json
from pathlib import Path
class BatchGenerator:
"""批量图像生成管理器"""
def __init__(self, api_key: str, concurrency: int = 3):
self.api_key = api_key
self.concurrency = concurrency
self.progress_file = Path("generation_progress.json")
async def generate_batch(self, prompts: List[str], output_dir: str):
"""批量生成图像"""
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
# 加载已完成的进度
completed = self._load_progress()
# 过滤未完成的任务
pending = [(i, p) for i, p in enumerate(prompts) if i not in completed]
# 创建信号量控制并发
semaphore = asyncio.Semaphore(self.concurrency)
async with aiohttp.ClientSession() as session:
tasks = [
self._generate_with_semaphore(session, semaphore, idx, prompt, output_path)
for idx, prompt in pending
]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 统计结果
success = sum(1 for r in results if not isinstance(r, Exception))
print(f"Batch complete: {success}/{len(pending)} successful")
async def _generate_with_semaphore(self, session, semaphore, idx, prompt, output_path):
async with semaphore:
# 实现生成逻辑...
pass
def _load_progress(self) -> set:
if self.progress_file.exists():
return set(json.loads(self.progress_file.read_text()))
return set()
def _save_progress(self, completed: set):
self.progress_file.write_text(json.dumps(list(completed)))
常见问题与解决方案
角色特征漂移问题
问题描述:生成的角色与参考图存在明显差异,尤其在侧面或极端角度时。
解决方案:
- 增加参考图数量:为关键角色提供3-4张不同角度的参考图
- 强化身份锁定语句:在提示词中添加
"face_match_accuracy: 100% exact match enforced" - 避免极端角度:将视角控制在参考图已覆盖的范围内
- 提高参考图质量:确保面部区域清晰、光照均匀
多角色特征混淆
问题描述:在多角色场景中,不同角色的特征发生混合。
解决方案:
hljs text# 错误示例 "Two women talking in a cafe" # 正确示例 "character_1 (from Image 1, blonde hair, round face) and character_2 (from Image 2, black hair, angular features) talking in a cafe. Maintain distinct identity for each character. character_1 on the left, character_2 on the right."
关键是为每个角色指定明确的区分特征,并在提示词中强调身份独立性。
生成速度优化
问题描述:单次生成耗时过长(超过60秒)。
影响因素与优化方向:
| 因素 | 影响程度 | 优化方法 |
|---|---|---|
| 参考图数量 | 高 | 仅上传必要的参考图 |
| 输出分辨率 | 高 | 非必要不使用4K |
| 提示词复杂度 | 中 | 简化不必要的细节描述 |
| 网络延迟 | 中 | 使用国内中转节点 |
图像质量不达预期
问题描述:生成图像模糊、细节丢失或风格不一致。
排查清单:
- 参考图分辨率是否达到1024×1024以上
- 是否指定了输出尺寸(2K/4K)
- 提示词是否包含具体的风格描述
- 是否避免了"4k, ultra detailed"等无效标签
- 光照参考图是否与目标场景匹配
高级技巧与最佳实践
使用JSON结构化提示词
对于复杂场景,使用JSON格式可以提高提示词的精确度:
hljs json{
"scene": {
"setting": "modern art gallery",
"lighting": "soft ambient with spotlight accents",
"atmosphere": "sophisticated, contemplative"
},
"characters": [
{
"id": "character_1",
"reference": "Images 1-2",
"position": "left third of frame",
"pose": "standing, viewing artwork",
"expression": "thoughtful, slight smile"
},
{
"id": "character_2",
"reference": "Images 3-4",
"position": "right third of frame",
"pose": "seated on bench",
"expression": "relaxed, content"
}
],
"composition": {
"aspect_ratio": "16:9",
"focus": "character_1 with shallow depth of field",
"style": "editorial photography, high fashion magazine"
},
"constraints": {
"identity_lock": "critical",
"face_match": "100%",
"no_deviation": true
}
}
迭代优化工作流
高质量输出通常需要2-3轮迭代:
- 初始生成:使用基础提示词获取初版
- 定向修正:针对不满意的部分添加约束
- 细节打磨:微调光照、表情、构图等细节
hljs pythondef iterative_refinement(base_prompt: str, refinements: List[str], api_key: str):
"""迭代优化生成"""
current_prompt = base_prompt
for i, refinement in enumerate(refinements):
current_prompt = f"{current_prompt}\n\nRefinement: {refinement}"
image = generate_single_image(current_prompt, api_key)
with open(f"iteration_{i+1}.png", "wb") as f:
f.write(image)
print(f"Iteration {i+1} complete")
return image
# 使用示例
base = "Portrait of character_1 in a sunset beach scene"
refinements = [
"Adjust lighting to golden hour warmth, reduce shadows on face",
"Make expression more relaxed, add slight wind effect on hair",
"Enhance background bokeh, sharpen facial features"
]
final_image = iterative_refinement(base, refinements, api_key)
建立角色参考库
对于需要长期维护角色一致性的项目,建议建立标准化的参考图库:
hljs text/character_library /protagonist_alice /faces front_neutral.jpg # 正面中性表情 front_smile.jpg # 正面微笑 left_45.jpg # 左侧45度 right_45.jpg # 右侧45度 /poses standing_full.jpg # 全身站立 sitting_casual.jpg # 休闲坐姿 /outfits business_formal.jpg # 正式商务装 casual_summer.jpg # 夏日休闲装 metadata.json # 角色描述元数据
这种组织方式便于快速检索和组合参考图,提高工作效率。
总结与快速开始清单
Nano Banana Pro的多参考图像系统为AI图像生成带来了前所未有的可控性和一致性。掌握本文介绍的技术要点,你可以实现:
- 14张参考图的智能融合:充分利用分层权重机制
- 5角色的完美一致性:通过Identity Locking技术
- 高效的批量生成:借助优化的代码架构
- 成本可控的规模化应用:合理选择API服务方案
快速开始清单
- 准备3-4张高质量角色参考图(至少1024×1024)
- 注册API服务账号(推荐入口)
- 复制本文代码模板并配置API密钥
- 从单角色单场景开始测试
- 逐步增加复杂度:多角色→多场景→批量生成
延伸阅读
- Nano Banana Pro API定价详解
- Nano Banana Pro最佳提示词指南
- 国内稳定接入Nano Banana Pro方案
- Nano Banana Pro vs GPT Image对比
掌握多参考图技术需要实践积累。建议从简单场景开始,逐步探索更复杂的应用。如果在使用过程中遇到问题,欢迎参考本文的常见问题解决方案,或查阅相关延伸文章获取更多帮助。