截至 2026 年 6 月 13 日,gemini-3.1-flash-image 没有官方 Gemini Developer API Free Tier 行。
Google AI Studio 仍然适合在浏览器里试用 Nano Banana 2,但这不等于给你的后端应用创建了免费生产 API 额度。只要是应用、服务或内部系统在调用 API,就应该按 Google 定价页上的付费 Developer API 行来规划,除非 Google 之后改变该定价行。
当前模型 ID 是 gemini-3.1-flash-image。旧教程里的 gemini-3.1-flash-image-preview 应当视为历史代码、迁移审计或旧 URL 语境,而不是新代码合同。
路线答案:只做浏览器测试时用 AI Studio;需要同步后端调用时用付费 Developer API Standard;任务可异步等待时再考虑付费 Batch;Gemini Apps 的消费端限制不要拿来当 API 配额。
停止规则:不要因为某个片段说“免费”就把生产流量发上去。先查 Google 定价行,再在 AI Studio 检查当前项目、模型和层级的实际限制。
先给结论
| 问题 | 当前答案 | 核验位置 |
|---|---|---|
官方 API 对 gemini-3.1-flash-image 免费吗? | 不是。Standard 和 Batch 图像行没有 Free Tier。 | Google Gemini API pricing |
| AI Studio | 可做浏览器测试,不是后端免费额度。 | AI Studio |
| Nano Banana 2 | 对应当前模型 ID gemini-3.1-flash-image。 | Google image generation docs |
| Preview ID | 新代码不用;只作旧例迁移。 | Google changelog |
“免费”在这个问题里不是一个统一权益,而是路线词。它可能指 AI Studio 浏览器测试、Gemini Apps 里的消费端功能、另一个 Gemini 模型的免费行,或者某个第三方页面自己的促销。对 Gemini 3.1 Flash Image 后端 API 来说,控制事实是 Google 定价页的模型行。
先选访问路线
最稳的规划方式是在写代码前先选路线。路线选错,后面的额度、成本和支持判断都会错。AI Studio 证明你可以在浏览器环境里试模型;Developer API 定价行决定你的后端调用是否免费;Apps 帮助页只解释消费端限制。
| 路线 | 成本状态 | 适合场景 | 主要边界 |
|---|---|---|---|
| AI Studio | 浏览器测试路线 | 提示词、参考图和一次性实验 | 看当前项目/账号限制 |
| Developer API Standard | 同步后端付费 | 应用、服务、内部工具 | 本模型无官方 Free Tier |
| Batch API | 异步付费低价 | 可等待的大批量任务 | 便宜不是免费 |
| Gemini Apps | 消费端功能 | 个人使用 | 不能当 API 配额 |
| 第三方网关 | 提供方自己的合同 | 当前证据充分时再评估 | 不能替代 Google 定价行 |
这张分流表的意义在于把“能试”和“能免费跑生产 API”拆开。很多误判发生在 AI Studio 里能生成图片以后,团队就默认服务器也有免费额度;实际应当回到项目、模型、层级和定价行检查。
官方 API 定价是付费行
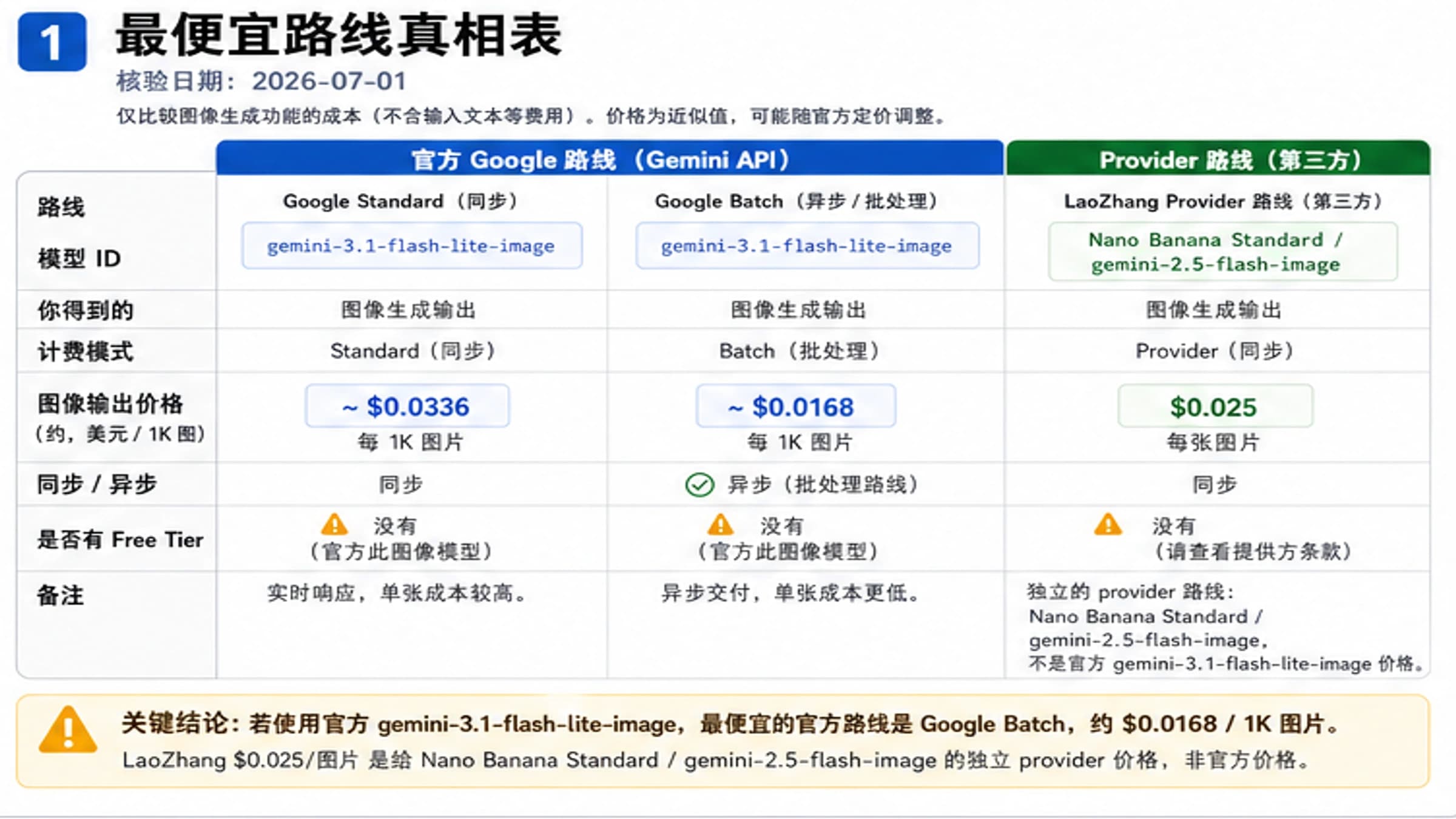
Google 定价页是 Developer API 免费层问题的事实源。当前检查中,gemini-3.1-flash-image 的 Standard 行没有 Free Tier,图像输出按每百万 image tokens 付费。Batch 行也不是免费,只是异步低价。
| 输出尺寸 | Standard API | Batch API |
|---|---|---|
| 0.5K | $0.045 | $0.022 |
| 1K | $0.067 | $0.034 |
| 2K | $0.101 | $0.050 |
| 4K | $0.151 | $0.076 |
这些数值适合做预算起点,不适合做永久承诺。价格、模型 ID、预览状态和计费行都属于高波动事实。发布、演示、迁移或大流量前,应该重新打开 Google 定价页确认 gemini-3.1-flash-image 的当前行。
使用当前模型 ID
新代码应该调用 gemini-3.1-flash-image。旧的 gemini-3.1-flash-image-preview 只适合在迁移旧仓库、解释旧截图、或保留旧页面路径时出现。Google changelog 把 GA 日期写为 2026 年 5 月 28 日,并给 preview 版本设置了 2026 年 6 月 25 日的停用日期。
hljs txtgemini-3.1-flash-image
不要让新代码从下面这个旧字符串开始:
hljs txtgemini-3.1-flash-image-preview
把模型 ID 统一到代码、日志、allowlist、计费看板和故障单里。否则支持团队看到的是 preview,财务看的是 GA 行,工程看的是 Nano Banana 2 显示名,问题会被拆到三套语言里。
上线前检查实时额度
额度问题不能靠旧表格解决。Google 的 rate-limit 文档用 RPM、TPM、RPD 描述限制,并且限制与项目、模型和层级相关。AI Studio 里的当前项目视图才是开发者上线前要看的操作面。
- 用拥有 API key 或项目的账号打开 AI Studio。
- 选择代码实际使用的同一个项目。
- 确认模型 ID 是
gemini-3.1-flash-image。 - 记录项目层级、RPM、TPM、RPD 和任何计费提示。
- 演示、上线、迁移或流量变化前重新检查。
什么时候 AI Studio 足够
AI Studio 适合做早期视觉判断:比较提示词、测试参考图、看 Nano Banana 2 是否适合某类编辑任务、给内部设计评审收集样例。只要开始涉及用户等待、重试、日志、计费、存储、数据保留或上线承诺,就应当切到 Developer API 规划。
Gemini Apps 是消费端路线
Gemini Apps 可以在消费端提供图像生成能力,但它不回答 Developer API 免费层问题。App 的计算限制、套餐能力、地区可用性和界面行为,不能直接变成后端 API 的 RPM、TPM、RPD 或免费权益。
| 表面 | 能证明 | 不能证明 |
|---|---|---|
| AI Studio | 可在浏览器测试模型行为 | 后端 API 免费或无限 |
| Developer API pricing | 模型 API 行是免费还是付费 | 每个项目的实时限制 |
| Gemini Apps | 消费端可能支持图片生成 | Developer API 配额 |
开发者决策规则
实际决策可以很简单:一次性体验用 AI Studio;交互式产品功能用付费 Standard;可等待的批量任务用付费 Batch;个人消费端使用留在 Gemini Apps;第三方网关只在你能核验它自己的成本、覆盖、失败处理、数据条款和支持路径时才评估。没有这些证据时,默认答案仍是官方路线优先。
如果只是想先免费试一下
很多团队真正想问的不是“有没有永久免费 API”,而是“能不能先不绑生产预算,把模型适不适合这个功能判断清楚”。这个任务可以交给 AI Studio。你可以用同一组提示词、参考图和输出尺寸做几轮手工比较,记录哪些场景稳定、哪些场景需要人工挑选、哪些场景根本不适合进入产品路线。
但这类浏览器验证不要直接扩展成 API 成本承诺。AI Studio 的价值是把产品假设筛掉一批,例如图文一致性是否够用、参考图能否被合理保留、用户需要的构图是否过于随机、失败样例是否容易解释。它回答的是“值得不值得继续设计后端调用”,不是“后端调用是否免费”。
一个更稳的做法是把试用阶段写成三条验收记录。第一,保留模型 ID、项目、日期和提示词集合,避免日后复盘时只剩 Nano Banana 2 这个显示名。第二,把每组样例分成可接受、需要重试、不可接受三类,不要只看最好的一张。第三,记录进入 API 方案前还缺什么,例如批量任务是否可等待、用户是否需要同步返回、是否需要保存输入图、失败重试由谁承担。
完成这些记录后,如果结论只是“这个模型可能适合”,仍然不应该把生产逻辑建立在免费层假设上。下一步是回到 Developer API 定价行和 AI Studio 项目限制,确认预算、额度、日志和回退行为。这样即使价格或额度后来改变,团队也知道自己当初验证的是模型能力,而不是错误地验证了成本权益。
还要特别注意多人协作场景。产品经理可能只看到 AI Studio 的样例,工程师看到的是模型 ID 和调用方式,财务看到的是价格行,客服看到的是用户问法。如果这些记录没有放在同一张上线检查表里,团队很容易各自引用一层证据。把证据层合并到同一个验收单,能让“免费测试”和“付费 API”在讨论开始时就被分开。
这也能降低后续迁移成本:当 Google 更新模型、价格或限制时,团队只需要复核定价行和项目限制,而不必重新争论 AI Studio 截图到底证明了什么。
如果客服或销售需要对外解释,也应引用这张验收单,而不是单独引用某次浏览器测试结果或过期教程。
这样回答更可复核,也更不容易把测试权限说成生产承诺。
这也是上线前最小的风险隔离。
把免费层判断写进工程验收
如果这个模型会进入真实应用,免费层判断应该成为工程验收的一部分,而不是文档备注。最小验收项包括:代码里只出现当前模型 ID,配置中能区分 Standard 与 Batch,日志里保留项目、模型、输出尺寸、错误类型和请求来源,成本看板能按图像任务拆分,支持回答不能把 AI Studio 测试说成 API 免费额度。
上线评审也要把同步和异步路线分开。交互式功能通常关心首字节时间、用户等待和失败重试,因此更接近 Standard API 的同步成本。离线生成、营销素材批处理或可排队任务可以评估 Batch,但 Batch 的低价来自异步处理,不是免费权益。把这两类任务混在同一个“图片生成”预算里,后续很容易把一次性测试成本误判成长期生产成本。
支持团队还需要一套统一话术。用户问“为什么 AI Studio 能试,API 还收费”时,答案应当落在路线差异上:AI Studio 是浏览器测试面,Developer API 是项目级后端调用面,Gemini Apps 是消费端产品面。三者都可能生成图片,但它们的额度、计费、限制和支持路径不同。解释清楚这个差异,通常比争论“免费”这个词更能解决问题。
相关的相邻问题可以分开看:Gemini API Free Tier 处理整个 Gemini API 免费层地图,Gemini image generation rate limits 处理图像 429 和额度恢复,Gemini 3 Pro Image vs Gemini 3.1 Flash Image 处理模型选择。
从 Preview 旧例迁移
迁移旧 preview 例子时,不只是替换字符串。还要重新检查定价假设、免费层措辞、项目额度、日志字段、文档截图和用户支持回答。旧模型名继续留在生产代码里,会把停用风险、计费风险和排障语言全部放大。
| 检查项 | 动作 |
|---|---|
| Model ID | 活动调用改成 gemini-3.1-flash-image。 |
| Free Tier wording | 把“免费 API”改成 AI Studio 测试或官方 API 无 Free Tier。 |
| Quota notes | 删除不属于当前项目的静态限制。 |
| Support logs | 记录项目、模型、tier、图片尺寸和错误维度。 |
常见问题
Gemini 3.1 Flash Image 有免费 API 层吗?
没有。以 2026 年 6 月 13 日的 Google 定价页为准,gemini-3.1-flash-image 的 Standard 与 Batch 图像行都没有 Free Tier。
AI Studio 可以免费测试吗?
可以作为浏览器测试路线使用,但它不是后端生产 API 免费额度。实际限制要看当前账号、项目、模型和层级。
Nano Banana 2 是同一个模型吗?
是。Google 图像生成文档把 Nano Banana 2 映射到 gemini-3.1-flash-image。
还应该使用 preview 模型 ID 吗?
新代码不应使用。gemini-3.1-flash-image-preview 只适合旧例子、迁移备注或历史 URL 语境。
Batch 便宜是不是等于免费?
不是。Batch 是较低价格的付费异步路线,适合可等待任务,不是 Free Tier。
Gemini Apps 的限制等于 API 限制吗?
不等于。Gemini Apps 是消费端产品,Developer API 额度属于项目、模型和层级。
在哪里查精确额度?
在 AI Studio 查看当前项目背后的模型、层级、RPM、TPM、RPD 和可见账号或计费提示。
更宽泛的 Gemini 免费层问题看哪里?
模型家族和项目额度问题应看 /zh/blog/gemini-api-free-tier/;图像 429 和额度恢复应看 /zh/blog/gemini-image-generation-rate-limit/。