Gemini 3 Pro vs GPT-Image-1.5: Complete Pricing & Quality Comparison (December 2025)
Compare Gemini 3 Pro Image (Nano Banana Pro) vs OpenAI GPT-Image-1.5: detailed pricing breakdown, quality benchmarks, text rendering, speed tests, and integration guide with code examples.
Nano Banana Pro
4K-80%Google Gemini 3 Pro · AI Inpainting
谷歌原生模型 · AI智能修图

The AI image generation landscape has shifted dramatically in the final weeks of 2025. OpenAI released GPT-Image-1.5 on December 16, 2025, just weeks after Google launched Gemini 3 Pro Image (codenamed Nano Banana Pro) as their flagship image generation model. For developers and businesses choosing between these two powerhouses, the decision involves weighing pricing structures, quality outputs, generation speed, and integration complexity.
This comprehensive comparison provides the latest pricing data from official documentation, real-world quality assessments, and practical code examples to help you make an informed decision. Whether you are building an e-commerce platform, creating marketing assets, or developing creative applications, understanding the differences between GPT-Image-1.5 and Gemini 3 Pro Image is essential for optimizing both cost and quality.
Both models represent significant architectural advances over their predecessors. GPT-Image-1.5 improves upon GPT-Image-1 with 4x faster generation and 20% lower token costs, while Gemini 3 Pro Image introduces advanced reasoning capabilities through its "Thinking" mode and supports up to 4K resolution outputs. The pricing models differ substantially: OpenAI uses a quality-tiered approach (Low/Medium/High) while Google charges based on output resolution (1K/2K/4K).

Model Overview: Two Different Approaches to Image Generation
Understanding the fundamental positioning of each model helps contextualize their strengths and trade-offs. GPT-Image-1.5 and Gemini 3 Pro Image represent the current state-of-the-art from OpenAI and Google respectively, but they approach image generation with different philosophies and technical implementations.
GPT-Image-1.5 is OpenAI's latest flagship image model, released on December 16, 2025. It powers the "ChatGPT Images" feature and immediately claimed the top position on LMArena's Text-to-Image leaderboard with a score of 1277. The model is designed for production-quality visuals and highly controllable creative workflows, offering significant improvements in realism, accuracy, and editability compared to its predecessor. Key enhancements include more precise image editing with better preservation of logos and faces, improved instruction following, and enhanced text rendering capabilities, particularly for dense text and markdown tables.
Gemini 3 Pro Image, known by its codename Nano Banana Pro, is Google's state-of-the-art image generation and editing model optimized for professional asset production. Built on the Gemini 3 Pro foundation, it leverages advanced reasoning to tackle complex multi-turn creation and modification tasks. The model excels at generating high-resolution outputs up to 4K, advanced text rendering for infographics and marketing assets, and a unique "Thinking" mode where it generates interim thought images to refine compositions before producing final outputs. For developers seeking detailed API documentation, the Nano Banana Pro API guide provides comprehensive integration instructions.
Both models support similar core capabilities including text-to-image generation, image editing with masks, and style control. However, their implementation details differ significantly in terms of maximum resolution, batch processing limits, and specialized features like Google Search grounding in Gemini 3 Pro Image.
Architecture Deep Dive: Autoregressive vs Multimodal Approaches
The architectural differences between GPT-Image-1.5 and Gemini 3 Pro Image fundamentally affect their generation characteristics, quality profiles, and performance trade-offs. Understanding these differences helps explain why each model excels in different scenarios.
GPT-Image-1.5 uses an autoregressive architecture, which represents a departure from the diffusion-based approach used in DALL-E models. In autoregressive image generation, the model predicts image tokens sequentially, similar to how language models generate text token by token. This approach enables several advantages: the model can leverage its extensive world knowledge during generation, produce more coherent compositions, and achieve superior text rendering within images. The autoregressive pipeline delivers more coherent text rendering and faster adaptation to unusual compositions, though it typically requires longer generation times than pure diffusion models. Text rendered by GPT-Image-1.5 is notably crisp and well-aligned, making it suitable for infographics, diagrams, and content with embedded typography.
Gemini 3 Pro Image employs a natively multimodal architecture built on the Gemini 3 Pro foundation. Rather than treating image generation as a separate capability, visual generation is integrated directly into the model's core reasoning capabilities. This enables the unique "Thinking" mode where the model can reason through complex prompts by generating interim composition images before producing the final high-quality output. The multimodal approach also allows Gemini 3 Pro Image to use Google Search as a grounding tool, verifying facts and generating imagery based on real-time data such as current weather maps, stock charts, or recent events. This architecture particularly excels at photorealistic image generation with accurate lighting, shadows, and textures.
The practical implications of these architectural choices are significant. For applications requiring accurate text within images, such as poster generation, slide creation, or branded content, GPT-Image-1.5's autoregressive approach typically delivers superior results. For applications prioritizing photorealism, complex scene composition, or integration with real-world data, Gemini 3 Pro Image's multimodal reasoning provides distinct advantages.
Pricing Comparison: Token-Based vs Resolution-Based Models
The pricing structures of GPT-Image-1.5 and Gemini 3 Pro Image differ fundamentally, requiring careful analysis to compare costs accurately. This section provides the latest official pricing data as of December 2025, with practical cost calculations for common usage scenarios.
GPT-Image-1.5 Pricing (December 2025)
GPT-Image-1.5 implements a token-based pricing model with separate rates for text input, image input, and image output. For those exploring cost-effective access options, our GPT-Image-1.5 free usage guide covers available methods.
| Component | Price per 1M Tokens | Notes |
|---|---|---|
| Text Input | $5.00 | Prompt text processing |
| Image Input | $8.00 | Reference images (20% cheaper than GPT-Image-1) |
| Image Output | $32.00 | Generated images (20% cheaper than GPT-Image-1) |
The actual cost per image varies based on the quality setting and resolution:
| Quality | Resolution | Approximate Cost | Use Case |
|---|---|---|---|
| Low | 1024x1024 | ~$0.008 | Rapid prototyping, previews |
| Medium | 1024x1024 | ~$0.032 | Commercial applications |
| High | 1024x1024 | ~$0.136 | Professional, print-ready |
| High | 1536x1024 | ~$0.170 | Landscape high-quality |
GPT-Image-1.5 also supports prompt caching, which reduces input token costs by 75% for repeated prompts, a significant advantage for applications generating variations of similar images.
Gemini 3 Pro Image Pricing (December 2025)
Gemini 3 Pro Image uses a resolution-based pricing model. For a detailed breakdown of per-image costs, see the Nano Banana Pro pricing analysis.
| Mode | Resolution | Price per Image | Notes |
|---|---|---|---|
| Standard | 1K/2K | $0.134 | Real-time generation |
| Standard | 4K | $0.240 | High-resolution output |
| Batch | 1K/2K | $0.067 | 50% discount, 24-hour delivery |
| Batch | 4K | $0.120 | 50% discount, async processing |
Token pricing breakdown for fine-grained cost calculation:
| Component | Price per 1M Tokens |
|---|---|
| Image Input | $2.00 (~$0.0011 per image) |
| Image Output | $120.00 |
Direct Cost Comparison
For standard 1024x1024 generation, here is how the models compare:
| Model | Low Quality | Medium Quality | High Quality |
|---|---|---|---|
| GPT-Image-1.5 | $0.008 | $0.032 | $0.136 |
| Gemini 3 Pro (1K) | - | $0.134 | - |
| GPT-Image-1 (legacy) | $0.010 | $0.040 | $0.170 |
Key insight: GPT-Image-1.5 Low quality ($0.008) is significantly cheaper than Gemini 3 Pro's standard tier ($0.134), making it 16x more cost-effective for preview and prototyping use cases. However, when comparing high-quality outputs, GPT-Image-1.5 High ($0.136) closely matches Gemini 3 Pro's 1K/2K pricing ($0.134).
Image Quality Evaluation: Photorealism and Artistic Styles
Quality assessment of image generation models requires examining multiple dimensions including photorealism, artistic style fidelity, detail handling, and consistency. Based on benchmark data and practical testing, each model demonstrates distinct strengths.
Photorealistic Generation: Gemini 3 Pro Image consistently produces the most photorealistic images among current models, with accurate lighting, shadows, and textures. The model particularly excels at landscape photography, product shots, and portrait photography styles. In comparative testing, Gemini 3 Pro Image images often appear brighter and show a greater level of detail in fine textures like fabric weaves, water droplets, and animal fur. The multimodal architecture enables the model to apply sophisticated understanding of real-world physics to lighting and composition.
Artistic and Creative Styles: GPT-Image-1.5 demonstrates superior performance in creative interpretation and artistic styles. The model excels at fantasy imagery, stylized visuals, and complex artistic compositions where adherence to physical realism is less important than creative expression. When given open-ended artistic prompts, GPT-Image-1.5 tends toward more imaginative interpretations while maintaining high visual quality. In benchmark testing on LMArena, GPT-Image-1.5 achieved the highest overall score (1277) across diverse image generation tasks.
Detail and Consistency: Both models handle fine details well, but with different characteristics. Gemini 3 Pro Image maintains remarkable consistency in multi-turn editing sessions, preserving character identity and scene elements across iterations. This consistency advantage is particularly valuable for workflows requiring multiple edits or variations. GPT-Image-1.5 demonstrates superior compositional accuracy for complex scenes involving multiple objects with specific spatial relationships, a result of its autoregressive attention mechanisms.
Color and Lighting: Gemini 3 Pro Image images tend to have more vibrant, saturated colors and dramatic lighting, while GPT-Image-1.5 often produces more naturalistic color grading. The choice between these profiles depends on intended use: marketing materials may benefit from Gemini 3 Pro's vibrancy, while documentary or editorial content may prefer GPT-Image-1.5's naturalism.
Text Rendering Comparison: Typography and Infographic Capabilities
Text rendering within generated images has historically been a weakness for AI image generators, but the latest models have made significant advances. This capability is crucial for applications requiring embedded text, such as marketing materials, infographics, presentations, and branded content.
GPT-Image-1.5 leads the industry in text rendering accuracy. The autoregressive architecture enables the model to treat text tokens with the same attention and precision applied to language generation, resulting in legible, correctly-spelled text in generated images. Dense text, markdown tables, and small typography now render with sufficient accuracy for direct use in infographics, posters, and branded content. Our detailed comparison in the Nano Banana Pro vs GPT-Image text rendering analysis examines specific test cases.
Gemini 3 Pro Image has also made substantial improvements in text handling. Google added a specialized decoder stage specifically to improve text legibility, and the model can now generate readable text for infographics, menus, and diagrams. However, the diffusion-based text generation still struggles with complex layouts, multilingual scripts, and very dense typography. The model may occasionally produce character substitutions or spacing issues in text-heavy compositions.
Practical Recommendations for Text-Heavy Content:
For applications where text accuracy is critical, GPT-Image-1.5 is the clear choice. The model can reliably render headlines, body text, data labels, and even styled typography with consistent accuracy. For applications where text is secondary to visual impact, and occasional minor text errors are acceptable, Gemini 3 Pro Image provides a viable option with its photorealistic background and superior lighting, particularly when combined with post-processing text overlay.
Speed and Latency: Generation Performance Analysis
Generation speed significantly impacts user experience and API costs in production applications. The two models demonstrate markedly different performance profiles that may influence architectural decisions.
Gemini 3 Pro Image delivers exceptional speed, generating images within 3-5 seconds through the standard synchronous API. This sub-5-second performance represents a significant advantage for real-time applications, interactive design tools, and user-facing features where immediate feedback is essential. The fast generation also enables efficient batch workflows where images can be generated sequentially without significant wait times.
GPT-Image-1.5 requires longer generation times, typically 15-30 seconds per image depending on complexity and quality settings. Through the ChatGPT interface, generation may exceed 60 seconds due to queue management and additional processing. However, GPT-Image-1.5 includes streaming support, allowing applications to display partial progress during generation and improving perceived responsiveness.
| Metric | GPT-Image-1.5 | Gemini 3 Pro Image |
|---|---|---|
| Typical Generation Time | 15-30 seconds | 3-5 seconds |
| Batch Processing | 1-10 images | 1-4 images |
| Streaming Support | Yes | No |
| Async Batch API | No | Yes (24-hour) |
Practical Implications: For applications requiring rapid iteration or real-time preview, Gemini 3 Pro Image's speed advantage is substantial. E-commerce product visualization, automated social media content, and rapid prototyping workflows all benefit from faster generation. For applications where generation happens in the background or quality is paramount over speed, GPT-Image-1.5's longer generation time is less impactful.
Technical Specifications: API Parameters and Capabilities
Understanding the technical specifications of each API helps developers design integrations that leverage each model's unique capabilities. This section details the supported parameters, formats, and special features.
GPT-Image-1.5 Technical Specifications
| Parameter | Specification |
|---|---|
| Supported Sizes | 1024x1024, 1536x1024 (landscape), 1024x1536 (portrait), auto |
| Quality Levels | low, medium, high |
| Output Formats | PNG, JPEG, WebP |
| Batch Size | 1-10 images per request |
| Output Method | Base64-encoded (URLs not supported) |
| Compression | 0-100% for JPEG/WebP |
| Streaming | Supported |
| Mask Editing | Yes (PNG, same dimensions as source) |
| Style Fidelity | high, low (controls style matching intensity) |
| Content Moderation | low, auto |
Gemini 3 Pro Image Technical Specifications
| Parameter | Specification |
|---|---|
| Supported Sizes | 1K (1024x1024), 2K, 4K |
| Aspect Ratios | 1:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 |
| Output Formats | PNG, JPEG (SynthID watermark embedded) |
| Batch Size | 1-4 images per request |
| Output Method | Base64-encoded in inline_data |
| Reference Images | Up to 14 (6 objects + 5 humans for consistency) |
| Thinking Mode | Generates interim composition images |
| Google Search Grounding | Real-time data integration |
| Safety Filter Levels | block_most, block_some, block_few |
Key Capability Differences
Resolution: Gemini 3 Pro Image supports significantly higher maximum resolution (4K vs 1536px), making it preferable for print-ready and large-format applications.
Aspect Ratio Flexibility: Gemini 3 Pro Image offers extensive aspect ratio options including cinematic 21:9, while GPT-Image-1.5 limits selections to square and standard landscape/portrait variations.
Reference Image Support: Gemini 3 Pro Image can accept up to 14 reference images for style and subject consistency, compared to GPT-Image-1.5's single reference image approach with mask editing.
Watermarking: All Gemini 3 Pro Image outputs include SynthID digital watermarks by default (removable for Google AI Ultra subscribers), while GPT-Image-1.5 does not add invisible watermarks.
Cost-Effectiveness Analysis: Monthly Production Scenarios
Real-world API costs depend on usage patterns, quality requirements, and optimization strategies. This analysis examines monthly cost projections for common production scenarios.
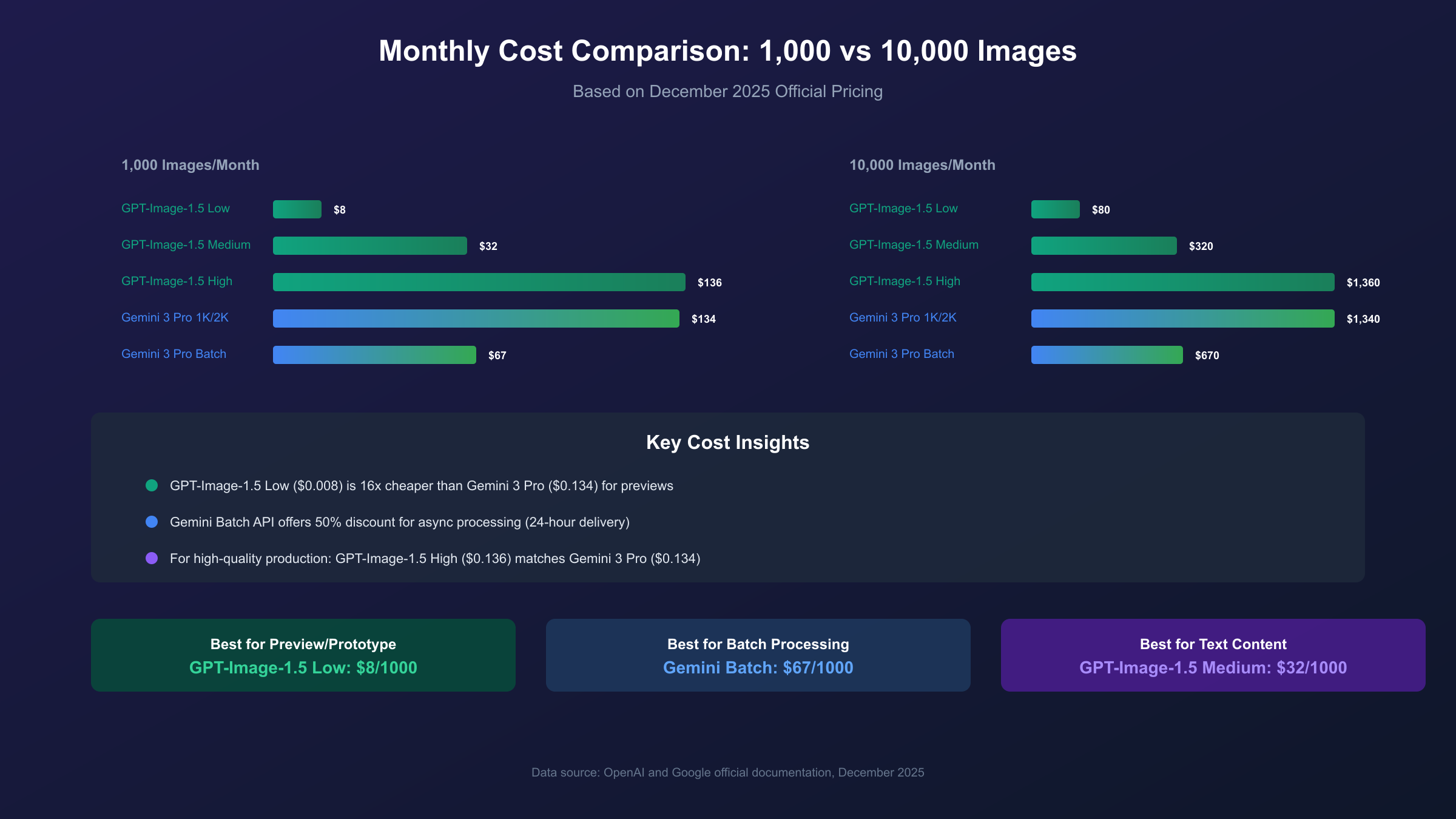
Scenario 1: 1,000 Images per Month (Small Business)
| Model & Quality | Monthly Cost | Notes |
|---|---|---|
| GPT-Image-1.5 Low | $8 | Preview quality, rapid prototyping |
| GPT-Image-1.5 Medium | $32 | Standard commercial use |
| GPT-Image-1.5 High | $136 | Professional output |
| Gemini 3 Pro 1K/2K | $134 | Standard quality |
| Gemini 3 Pro 1K/2K Batch | $67 | 50% savings with async processing |
Scenario 2: 10,000 Images per Month (Medium Enterprise)
| Model & Quality | Monthly Cost | Notes |
|---|---|---|
| GPT-Image-1.5 Low | $80 | Preview quality |
| GPT-Image-1.5 Medium | $320 | Standard commercial |
| GPT-Image-1.5 High | $1,360 | Professional output |
| Gemini 3 Pro 1K/2K | $1,340 | Standard quality |
| Gemini 3 Pro 1K/2K Batch | $670 | Batch processing discount |
Cost Optimization Strategies
For GPT-Image-1.5:
- Use Low quality for initial drafts and client previews, upgrading to High only for final deliverables
- Implement prompt caching for template-based generation (75% input cost reduction)
- Batch multiple requests to reduce API call overhead
For Gemini 3 Pro Image:
- Utilize the Batch API for non-time-sensitive generation (50% cost reduction)
- Schedule bulk generation during off-peak hours for improved reliability
- Consider Google AI Studio's free tier (500 images/day) for development and testing
For developers seeking cost optimization beyond official APIs, third-party aggregation platforms can provide additional savings. For example, laozhang.ai offers unified API access to both models with transparent per-token pricing, approximately 30-50% below official rates for high-volume usage. Official APIs remain preferable when SLA guarantees, dedicated support, or specific compliance requirements are essential.
The following visualization summarizes the monthly cost comparison across different quality tiers and usage volumes, highlighting the cost advantages of each model for specific scenarios.
Integration Guide: Python Code Examples
This section provides working code examples for integrating both APIs into Python applications. Each example includes complete imports, error handling, and practical usage patterns.
GPT-Image-1.5 Integration
hljs pythonfrom openai import OpenAI
import base64
from pathlib import Path
# Initialize client with official API
client = OpenAI(api_key="your-openai-api-key")
def generate_image_gpt(
prompt: str,
quality: str = "medium",
size: str = "1024x1024",
output_format: str = "png"
) -> bytes:
"""
Generate image using GPT-Image-1.5
Args:
prompt: Text description of desired image
quality: 'low', 'medium', or 'high'
size: '1024x1024', '1536x1024', or '1024x1536'
output_format: 'png', 'jpeg', or 'webp'
Returns:
Image data as bytes
"""
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
quality=quality,
size=size,
response_format="b64_json",
output_format=output_format
)
image_data = base64.b64decode(response.data[0].b64_json)
return image_data
# Usage example
image = generate_image_gpt(
prompt="A professional product photo of a modern smartwatch on white background",
quality="high"
)
Path("output.png").write_bytes(image)
Gemini 3 Pro Image Integration
hljs pythonimport google.generativeai as genai
import base64
from pathlib import Path
# Initialize with Google AI API key
genai.configure(api_key="your-google-api-key")
def generate_image_gemini(
prompt: str,
aspect_ratio: str = "1:1",
image_size: str = "2K"
) -> bytes:
"""
Generate image using Gemini 3 Pro Image (Nano Banana Pro)
Args:
prompt: Text description of desired image
aspect_ratio: '1:1', '16:9', '9:16', '21:9', etc.
image_size: '1K', '2K', or '4K'
Returns:
Image data as bytes
"""
model = genai.GenerativeModel("gemini-3-pro-image-preview")
response = model.generate_content(
prompt,
generation_config={
"response_modalities": ["TEXT", "IMAGE"],
"image_config": {
"aspect_ratio": aspect_ratio,
"image_size": image_size
}
}
)
# Extract image from response
for part in response.parts:
if hasattr(part, 'inline_data'):
return base64.b64decode(part.inline_data.data)
raise ValueError("No image generated in response")
# Usage example
image = generate_image_gemini(
prompt="A photorealistic landscape of mountains at sunset with dramatic clouds",
aspect_ratio="16:9",
image_size="4K"
)
Path("output.png").write_bytes(image)
Unified API Access via laozhang.ai
For developers requiring access to multiple models through a single interface, the following example demonstrates unified API integration:
hljs pythonfrom openai import OpenAI
# Unified access to multiple image models
client = OpenAI(
api_key="your-laozhang-api-key",
base_url="https://api.laozhang.ai/v1"
)
# Generate with GPT-Image-1.5
gpt_response = client.images.generate(
model="gpt-image-1.5",
prompt="Modern office interior with natural lighting",
quality="high"
)
# Same interface for Gemini 3 Pro Image
gemini_response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Modern office interior with natural lighting",
size="2048x2048" # Maps to 2K
)
This unified approach simplifies integration when you need to compare outputs, implement fallback logic, or switch between models based on specific requirements. The laozhang.ai documentation provides complete parameter mappings for all supported models.
Use Case Recommendations: Choosing the Right Model
Different applications have different requirements for quality, speed, cost, and specific features. This decision matrix helps identify the optimal model for common use cases.
| Use Case | Recommended Model | Reasoning |
|---|---|---|
| E-commerce Product Photos | Gemini 3 Pro Image | Superior photorealism, accurate lighting and textures |
| Marketing Posters with Text | GPT-Image-1.5 | Best-in-class text rendering for headlines and copy |
| Social Media Content | GPT-Image-1.5 Low/Medium | Cost-effective at scale, fast iteration |
| Infographics & Data Viz | GPT-Image-1.5 | Accurate text, numbers, and labels |
| Artistic/Creative Content | GPT-Image-1.5 | Superior creative interpretation |
| Real-time Preview Tools | Gemini 3 Pro Image | 3-5 second generation vs 15-30 seconds |
| Print-Ready 4K Output | Gemini 3 Pro Image | Native 4K support |
| Character Consistency | Gemini 3 Pro Image | Multi-reference image support |
| Batch Processing at Scale | Gemini 3 Pro Image Batch | 50% cost reduction with async API |
| Interactive Editing Sessions | Gemini 3 Pro Image | Faster iteration, consistency features |
Regional Considerations
For developers in regions with limited direct access to these APIs, such as mainland China, aggregation platforms provide reliable access with optimized routing. Our Nano Banana Pro China access guide details specific solutions for Chinese developers, including platforms like laozhang.ai that offer approximately 20ms latency compared to 200ms+ for direct connections through VPN.

Frequently Asked Questions
Which model is cheaper overall, GPT-Image-1.5 or Gemini 3 Pro Image?
The cost comparison depends heavily on quality requirements and usage patterns. For preview-quality images, GPT-Image-1.5 Low at $0.008 per image is significantly cheaper than Gemini 3 Pro at $0.134 per image, representing a 16x cost difference. For high-quality production images, the costs converge: GPT-Image-1.5 High costs approximately $0.136 while Gemini 3 Pro 1K/2K costs $0.134. Gemini 3 Pro offers a Batch API with 50% discount for non-time-sensitive generation, reducing costs to $0.067 per image. Organizations with mixed quality needs often find GPT-Image-1.5 more cost-effective due to its flexible quality tiers.
Which model produces better quality images?
Quality depends on the specific use case. Gemini 3 Pro Image excels at photorealistic imagery with superior lighting, textures, and color vibrancy, making it ideal for product photography and realistic scenes. GPT-Image-1.5 leads in creative interpretation, artistic styles, and text rendering accuracy, making it preferable for marketing content with embedded text, infographics, and stylized artwork. In benchmark testing, GPT-Image-1.5 achieved the highest overall score on LMArena (1277), while Gemini 3 Pro Image ranked highest specifically for photorealism in comparative studies.
Can I render accurate text in images with these models?
GPT-Image-1.5 is currently the industry leader in text rendering accuracy. Its autoregressive architecture enables it to generate legible, correctly-spelled text suitable for headlines, body copy, data labels, and even dense markdown tables. Gemini 3 Pro Image has improved text capabilities compared to earlier models but may still produce occasional character errors or spacing issues in text-heavy compositions. For applications where text accuracy is critical, GPT-Image-1.5 is the recommended choice.
How fast can each model generate images?
Gemini 3 Pro Image generates images in 3-5 seconds, approximately 5-6 times faster than GPT-Image-1.5's typical 15-30 second generation time. This speed difference significantly impacts user experience for interactive applications and affects total throughput for batch processing workflows. GPT-Image-1.5 offers streaming mode to display partial progress during generation, which can improve perceived responsiveness in user-facing applications.
What is the maximum resolution supported?
Gemini 3 Pro Image supports up to 4K resolution natively, while GPT-Image-1.5 maxes out at 1536x1536 pixels. For print-ready materials, large-format displays, or applications requiring high-resolution outputs, Gemini 3 Pro Image provides a significant advantage. The 4K output from Gemini 3 Pro is priced at $0.24 per image in standard mode or $0.12 using the Batch API.
Are there free tiers or trials available?
Google AI Studio offers a free tier with approximately 500 images per day from Gemini 3 Pro Image, suitable for development and testing. OpenAI provides $5 in free credits for new accounts, equivalent to approximately 625 GPT-Image-1.5 Low quality images or 37 High quality images. Third-party platforms like laozhang.ai offer 3 million free tokens for initial testing across multiple models.
Conclusion: Making Your Decision
The choice between Gemini 3 Pro Image and GPT-Image-1.5 ultimately depends on your specific priorities across quality, speed, cost, and feature requirements.
Choose GPT-Image-1.5 when you need:
- Superior text rendering for infographics, posters, or branded content
- Flexible cost tiers from $0.008 (Low) to $0.136 (High) per image
- Creative interpretation and artistic style flexibility
- Streaming generation for responsive user experiences
Choose Gemini 3 Pro Image when you need:
- Photorealistic output with superior lighting and textures
- Fast generation (3-5 seconds vs 15-30 seconds)
- High-resolution output up to 4K
- Multi-reference image support for character/style consistency
- Google Search grounding for data-driven visualizations
For production applications requiring reliable access to both models, API aggregation platforms offer unified interfaces with potential cost savings. laozhang.ai provides OpenAI-compatible endpoints for both models with transparent pricing and approximately 20ms latency from Asian regions. When official SLA guarantees or dedicated enterprise support are required, direct API access through OpenAI and Google remains the appropriate choice.
Both models represent significant advances in AI image generation. The optimal choice depends on matching each model's strengths to your specific use case requirements. For many organizations, a hybrid approach using GPT-Image-1.5 for text-heavy content and Gemini 3 Pro Image for photorealistic imagery may provide the best overall results.