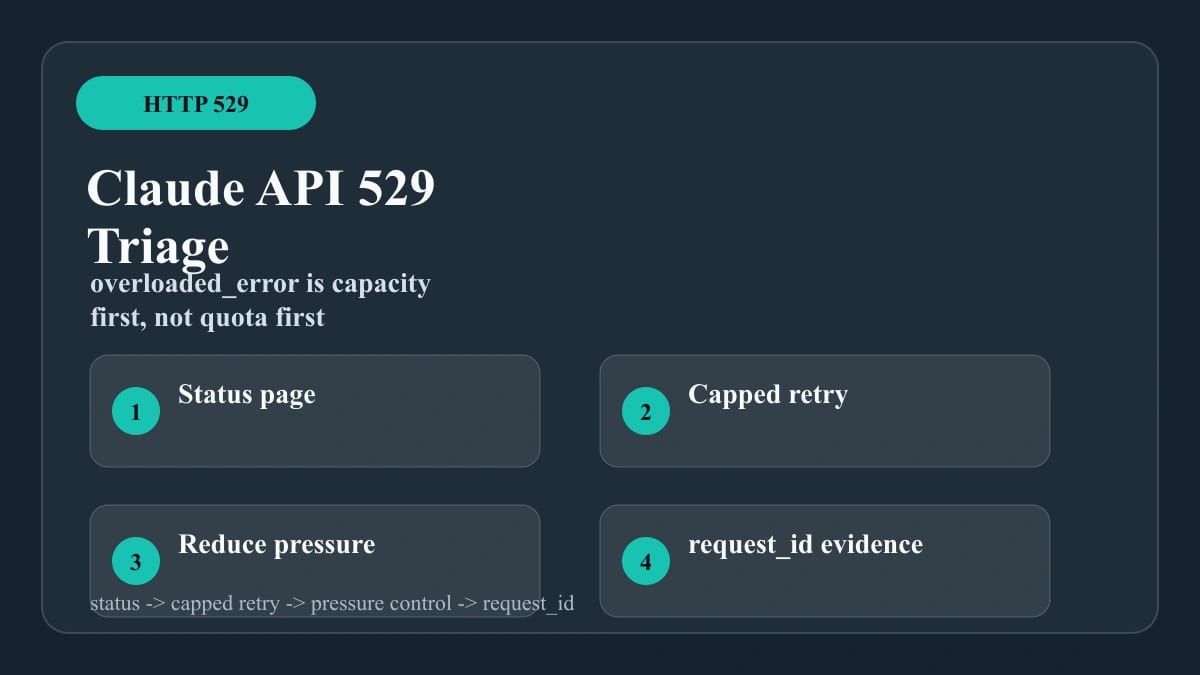
If the Claude API returns HTTP 529 with overloaded_error, treat the first response as an Anthropic capacity branch, not as your account hitting a 429 rate limit. Check Claude Status first, stop any immediate retry loop, reduce parallel traffic, then retry with capped exponential backoff and jitter. Keep the original endpoint, model, workspace, timestamp, and request_id stable while you test, because changing every variable at once hides the owner of the failure.
| Signal in the response | Most likely owner | First move | Stop condition |
|---|---|---|---|
HTTP 529 plus overloaded_error | Anthropic capacity across users | Status check, capped jittered retry, queue new work | Stop after the retry budget and preserve evidence |
HTTP 429 plus rate_limit_error | Your organization or workspace rate limit | Read rate-limit headers and lower request pressure | Stop until the reset signal or tier state changes |
| HTTP 500 or 504 | Server error or processing timeout | Status check, smaller controlled request, streaming for long work | Escalate with request evidence if persistent |
| Claude Code says repeated 529 | Claude Code already exhausted automatic retries | Check status, wait, switch model only for continuity | Do not assume quota exhaustion |
The repair rule is narrow: a 529 can be retried, but only slowly and with pressure reduction. A tight loop, new keys, or a quota playbook usually makes the outage harder to diagnose.
529 is an overload branch, not a quota branch
Anthropic's API error reference separates HTTP 529 from the limits that belong to your organization. In that reference, 429 is the rate-limit branch, 500 is an internal API error, 504 is a timeout branch, and 529 is the temporary overloaded branch. That distinction changes the first move. A 429 asks you to read headers and lower the traffic your account controls. A 529 asks you to confirm current service state and keep retries bounded while capacity recovers.
The current status page matters because capacity events can be model-specific, surface-specific, or short-lived. At 2026-04-30T13:42:00+08:00, the public Statuspage API reported the Claude API component as operational while also listing recent incidents earlier on April 30, 2026 and April 29, 2026. That combination is normal for overload work: a current 529 may be a short capacity spike, a model-level pressure point, or a lagging client path even when the broad component line has returned to operational.
Do not erase the symptom too early. The exact response body, the HTTP status, the request_id, the model, the endpoint, the workspace, and the local timestamp are the diagnostic record. If a retry later succeeds, that same record still tells you whether the fix was waiting, lower concurrency, a smaller payload, or a route change.
First five minutes: stabilize the request path
Start with evidence, not code changes. Copy the full response body, response headers, request id, model, endpoint, workspace, provider route, input size, concurrency setting, and timestamp with timezone. Open Claude Status and note whether Claude API, Claude Code, or a model-specific incident is active. If a gateway, automation platform, or hosted agent sits between your app and Anthropic, record that layer separately so an upstream 529 is not confused with a wrapper timeout.
Then send one controlled request on the same path. Keep the same API key, organization, model, endpoint, and client library. Reduce the payload to a small known-good prompt and use a low output cap. If the small request succeeds while the production burst fails, the repair is traffic shaping. If the small request also returns 529, the evidence points more strongly to capacity or provider route pressure.
Use a stop rule. Three to five attempts with exponential backoff and jitter are enough for a foreground request. Background jobs can wait longer, but they should move into a queue with a retry-after time instead of occupying a worker and hammering the same endpoint. When the retry budget is exhausted, keep the job pending and surface a clear temporary-capacity state to your application.
Retry slowly, with jitter and a hard ceiling
A 529 is retryable in the sense that the same request may work when capacity returns. It is not retryable in the sense that more immediate attempts create success. The retry policy should spread load, cap effort, and protect downstream work.
hljs tstype ClaudeBranch = "overload_retry" | "rate_limit_wait" | "server_check" | "non_retry";
function classifyClaudeApiError(status: number, type?: string): ClaudeBranch {
if (status === 529 || type === "overloaded_error") return "overload_retry";
if (status === 429 || type === "rate_limit_error") return "rate_limit_wait";
if (status === 500 || status === 504) return "server_check";
return "non_retry";
}
async function waitForOverloadRetry(attempt: number) {
const baseMs = Math.min(60_000, 1_000 * 2 ** attempt);
const jitterMs = Math.floor(Math.random() * 750);
await new Promise((resolve) => setTimeout(resolve, baseMs + jitterMs));
}
The key is the ceiling. A web request can usually try three times and then return a temporary failure. A batch worker can keep the job in a durable queue and retry later. A streaming user interface should tell the user the model path is temporarily overloaded rather than silently freezing.
Do not mix the 529 branch with 429 repair. Anthropic's rate-limit documentation says 429 responses can include a retry-after header and rate-limit headers. A 529 may not give your account a reset time because the owner is not your account bucket. When the response is 529, retry scheduling is your backoff policy plus service-state observation, not a quota reset countdown.
Reduce pressure without hiding the diagnosis
Pressure reduction is useful only when it preserves a clean diagnosis. Lower worker concurrency, disable speculative parallel calls, queue new tasks, shorten context, and avoid duplicate retries from every service layer. If a client SDK already retries transient failures, do not wrap it in another aggressive loop unless you can prove the combined policy still has a strict cap.
For long jobs, prefer streaming or asynchronous batch processing when the user does not need an immediate synchronous answer. Streaming reduces idle timeout confusion, while batch or queue-based work prevents a single capacity spike from taking down all foreground requests. For repeated prompts with large shared context, prompt caching can reduce account-side token pressure, which helps with 429 and burst behavior even though it cannot guarantee that a 529 will disappear.
Model switching is a continuity tactic, not proof that the first model was wrong. Claude Code's error reference explicitly treats repeated 529 as a capacity condition and suggests switching models to keep working when one model is under load. For an API integration, a fallback model can be reasonable if the product contract allows a quality change. If the response must come from the original model, wait and retry later instead of silently changing output quality.
Verify the same path before escalating
The cleanest verification is same-path, smaller-load testing. Send a small request through the same API key, organization, workspace, endpoint, model, client library, proxy, and network path. Then send the production shape at lower concurrency. That pair tells you whether overload follows the provider path, the workload size, the request burst, or a wrapper layer.
Keep an overload log separate from general application logs. Include request id, status, error type, model, endpoint, workspace, provider route, attempt number, delay, input token estimate, output cap, and final disposition. If support is needed, Anthropic's error documentation says the request id helps support investigate a specific request. A support ticket that includes request ids, timestamps, status-page state, and a same-path reproduction is much stronger than a screenshot of a terminal loop.
Escalate when the symptom is persistent, broad, and reproducible after controlled retries. If only one automation platform fails while direct Anthropic calls succeed, start with that platform. If direct calls fail across small controlled requests and status is clean, escalate with request ids. If status shows an active incident, preserve evidence and let queued work drain after recovery.
Claude Code, gateways, and automation platforms
Claude Code has its own surface behavior. Its error reference says transient server errors, overloaded responses, timeouts, temporary throttles, and dropped connections are retried automatically before the user sees the final message. Therefore, a visible repeated-529 message in Claude Code is already after several attempts. The next move is status, waiting, or a model switch for continuity, not assuming that your Console API tier is exhausted.
Gateways and automation products add another branch. Zapier, Make, a custom proxy, or a hosted agent may replay, delay, or transform the error. Keep the upstream Anthropic status separate from wrapper status. When a platform gives you only a generic failure, add logging that captures the original HTTP status and Anthropic error type. Without that, 529, 429, timeout, and wrapper quota can all look like the same red step.
The durable production pattern is a small state machine: classify the error, check service state, retry with a cap, reduce pressure, queue deferred work, and preserve request evidence. That state machine is more reliable than one-off fixes such as rotating keys, retrying immediately, or lowering output quality without telling the caller.
Production checklist
| Control | Why it matters for 529 | Implementation note |
|---|---|---|
| Error classifier | Keeps 529 separate from 429, 500, and 504 | Branch on HTTP status plus error type |
| Capped jittered retry | Avoids retry storms during capacity spikes | Set different budgets for foreground and batch jobs |
| Concurrency limits | Stops all workers from waking together | Cap by model, endpoint, and provider route |
| Durable queue | Protects user-facing requests from overload windows | Store next retry time and attempt count |
| Same-path probe | Confirms whether a smaller request works | Keep key, workspace, model, endpoint, and route stable |
| Request id logging | Makes escalation actionable | Capture body field and response header when present |
| Status observation | Separates active incident from local pressure | Record checked time and affected component |
FAQ
Does Claude API 529 count against my quota?
Treat 529 as a capacity branch rather than a normal quota branch. Claude Code's error reference says repeated 529 is not the user's usage limit. For direct API work, keep your own billing and usage checks separate, but do not apply a 429 quota repair to a response whose type is overloaded_error.
Should I retry immediately when I see overloaded_error?
No. Retry with backoff, jitter, and a ceiling. Immediate loops increase traffic at the exact moment the service is asking clients to slow down.
Is switching models a real fix?
It is a continuity move. It can keep a non-critical workflow moving if capacity pressure is model-specific and the product contract allows a different model. It is not a silent replacement for requests that require the original model.
What evidence should I send to support?
Send request ids, timestamps with timezone, model, endpoint, workspace, provider route, status-page state, retry schedule, and the result of one smaller same-path request. That evidence lets support separate capacity, model, route, wrapper, and account-state branches.