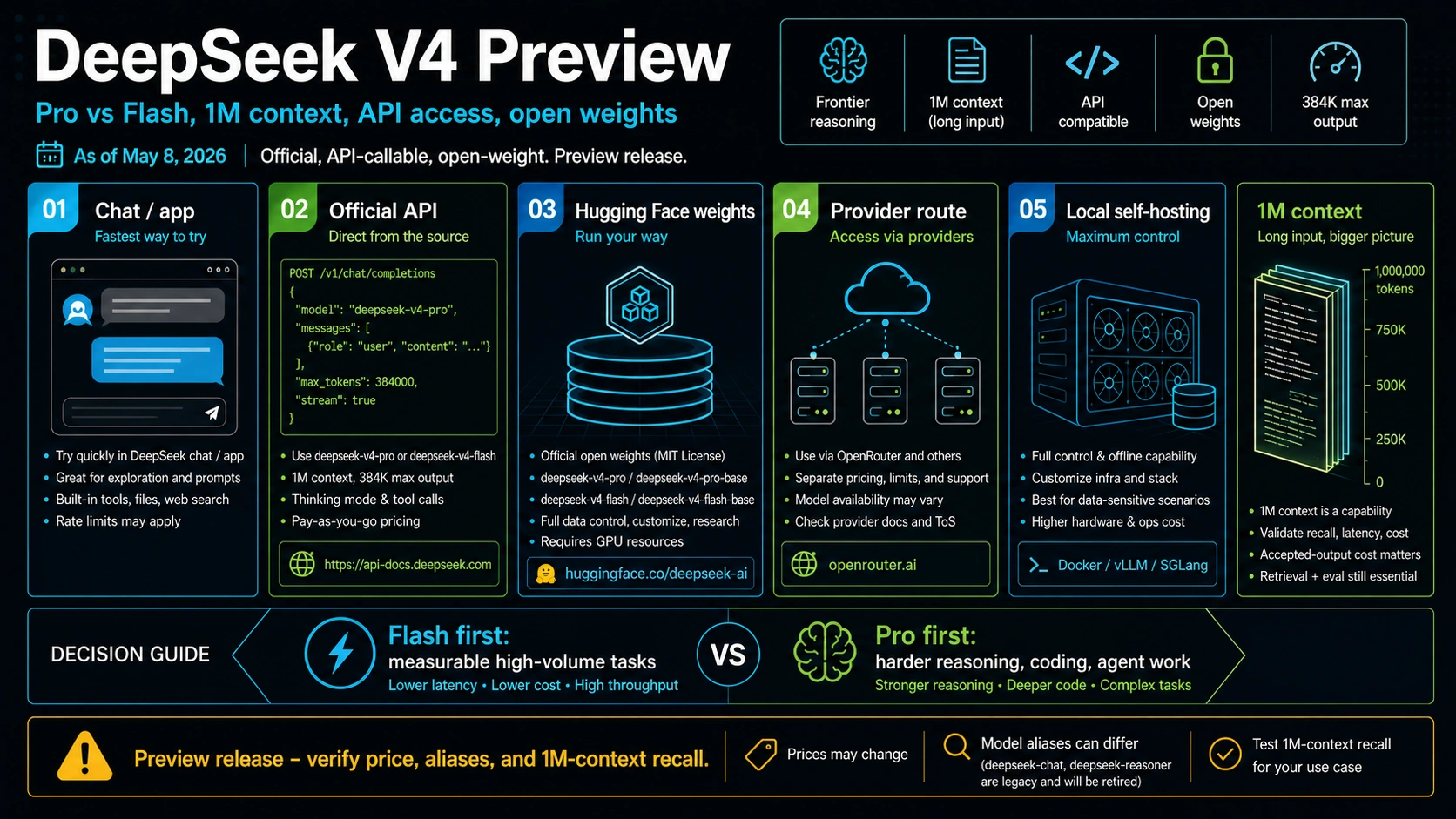
As of May 8, 2026, DeepSeek V4 Preview is official: DeepSeek has published the April 24 release, lists deepseek-v4-pro and deepseek-v4-flash in its API docs, and provides verified open-weight artifacts through its Hugging Face account. The practical decision is which DeepSeek route to test first, because chat/app access, the official API, Hugging Face weights, third-party providers, and local self-hosting each prove a different contract.
| Route | Use it first when | Verify before production |
|---|---|---|
| Chat or app | You need the fastest hands-on trial. | Feature limits, privacy boundary, and whether the same behavior exists in API. |
| Official API | You need DeepSeek's hosted contract and exact model IDs. | deepseek-v4-pro vs deepseek-v4-flash, 1M context behavior, 384K max output, pricing date, thinking mode, tool calls, and streaming. |
| Hugging Face weights | You need open-weight control or local research. | Hardware, serving stack, license boundary, recall, latency, and whether your setup matches hosted API behavior. |
| Provider route | You need a gateway, regional route, or existing provider account. | Provider-specific price, limits, model freshness, quota, routing, and support policy. |
| Local self-hosting | You need maximum control or offline-sensitive deployment. | GPU capacity, context feasibility, accepted-output cost, maintenance burden, and evaluation coverage. |
Start with deepseek-v4-flash for measurable high-volume tasks where latency, throughput, and cost matter. Start with deepseek-v4-pro when harder reasoning, coding, agent work, long-context synthesis, or failure review time costs more than the extra tokens. Do not use deepseek-v4-preview as an API model ID, and do not treat 1M context as proof of perfect recall; validate recall, latency, accepted-output cost, and route-specific behavior on your own workload.
What DeepSeek Actually Announced
DeepSeek's own release note is enough to answer the status question, but not the route question. The release is titled "DeepSeek V4 Preview Release" and is dated April 24, 2026. It says V4 Preview is officially live and open-sourced, names DeepSeek-V4-Pro and DeepSeek-V4-Flash, and says both models support 1M context plus thinking and non-thinking modes.
The model split matters. DeepSeek-V4-Pro is listed as a 1.6T-parameter mixture-of-experts model with 49B active parameters. DeepSeek-V4-Flash is listed as 284B total parameters with 13B active parameters. That does not automatically make Pro the correct first test for every team. It means Pro should be the stronger DeepSeek route when failure cost is high, while Flash is the efficient first lane for workloads that can be measured and rejected cheaply.
DeepSeek also says the models can be tried through chat.deepseek.com in Expert Mode and Instant Mode, and that the API is available with explicit model IDs. Those are separate surfaces. A chat test can reveal qualitative behavior, but it does not prove API latency, tool calling, token billing, context behavior, or provider-route support. Treat the chat surface as exploration and the API route as the implementation contract.
DeepSeek-V4-Pro vs DeepSeek-V4-Flash
Flash is the default first test only when the task has a measurable acceptance check. Use it for extraction, classification, routing, high-volume summarization, structured output, document screening, and other jobs where a bad answer can be caught by a schema, test set, reviewer queue, or second-pass verifier. If Flash meets the acceptance bar, the lower hosted cost can let you run more validation, process more context, or add a retry without blowing up the budget.
Pro is the first test when a weak answer is expensive. That includes coding agents, multi-file reasoning, tool-heavy workflows, long-context synthesis, multi-hop analysis, architecture tradeoffs, and tasks where human review time is the real cost. Pro can still be cheaper operationally if it avoids repeated retries or manual repair. The decision is not "Pro is better"; the decision is whether Pro reduces accepted-output cost for the hard slices of your workload.

| Workload | Test first | Why |
|---|---|---|
| High-volume classification or tagging | deepseek-v4-flash | The output is cheap to validate and rerun. |
| Bulk summarization with quality checks | deepseek-v4-flash | Throughput and cost matter more than maximum reasoning depth. |
| Coding agent or debugging run | deepseek-v4-pro | A brittle answer can waste more time than the token difference. |
| Long-document synthesis | Start with Flash, escalate hard cases to Pro | The easy documents should not pay Pro prices, but failures need a stronger lane. |
| Tool-call workflow | Compare both on the same tool schema | Tool argument discipline is workload-specific. |
Keep one baseline prompt and one evaluation table across both models. Measure quality, recall, latency, tool-call validity, output length, and accepted-output cost. If Flash passes the same checks, use Flash. If only Pro passes, isolate the hard branch instead of promoting every request.
API Model IDs, Old Aliases, and Request Shape
The API implementation rule is simple: use explicit V4 IDs in new code. DeepSeek's release note names deepseek-v4-pro and deepseek-v4-flash as the V4 API model IDs. It also says deepseek-chat and deepseek-reasoner currently route to DeepSeek-V4-Flash non-thinking and thinking modes, and that those compatibility names are scheduled to become inaccessible after July 24, 2026 at 15:59 UTC.
That retirement date is the reason not to build new production config around the old aliases. They may be convenient for old clients, but they are not the clearest long-term model contract. Put deepseek-v4-pro or deepseek-v4-flash in configuration, document why the choice was made, and add an alert or release-review item before the alias retirement date if older services still use deepseek-chat or deepseek-reasoner.

For OpenAI-compatible clients, DeepSeek's pricing and quick-start material identify https://api.deepseek.com as the base URL. Keep the model ID explicit and keep route-specific behavior in your own integration tests:
hljs tsimport OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: "https://api.deepseek.com",
});
const response = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{
role: "user",
content: "Summarize this document and quote the evidence lines you used.",
},
],
stream: true,
max_tokens: 4096,
});
Use deepseek-v4-pro in the same slot when the hard branch needs Pro. Do not put DeepSeek V4 Preview, deepseek-v4-preview, or provider-specific display names into the model field unless the provider's own API contract explicitly requires a different naming layer.
Pricing and Discount Boundary
DeepSeek's pricing page is the source to check before quoting hosted API costs. As of May 8, 2026, the page lists both V4 models with 1M context and 384K maximum output, and it also marks the prices as subject to change.
| Model | Cache hit input | Cache miss input | Output | Current caveat |
|---|---|---|---|---|
deepseek-v4-flash | $0.0028 per 1M tokens | $0.14 per 1M tokens | $0.28 per 1M tokens | Cache-hit reduction took effect April 26, 2026 at 12:15 UTC. |
deepseek-v4-pro | $0.003625 per 1M tokens during discount | $0.435 per 1M tokens during discount | $0.87 per 1M tokens during discount | DeepSeek says the 75% V4-Pro discount is extended until May 31, 2026 at 15:59 UTC. |
deepseek-v4-pro original row | $0.0145 per 1M tokens | $1.74 per 1M tokens | $3.48 per 1M tokens | Use this row after the discount unless DeepSeek updates pricing again. |
These rows should drive test budgeting, not marketing promises. A provider route may copy, discount, bundle, or change pricing in its own way. That provider page proves only the provider's contract. If you are buying through a gateway such as OpenRouter, read the provider's price, routing, fallback, logging, support, and model freshness terms separately instead of treating it as first-party DeepSeek billing.
How to Validate 1M Context
A 1M context window is a capability to validate, not permission to skip retrieval design. DeepSeek's official API rows and verified model cards support the 1M-context claim, and the API page lists 384K maximum output. That is a large operational surface. Long inputs can still fail through truncation, weak recall, lost middle evidence, latency, cost, or updates during the Preview period.

A useful long-context test has at least six checks:
| Check | What it proves | Failure signal |
|---|---|---|
| Input acceptance | The route accepts the intended prompt size. | Rejection, truncation, timeout, or unexpected provider limit. |
| Distant recall | The model can retrieve facts placed far apart. | It cites early context but misses late or middle evidence. |
| Cross-section reasoning | It can combine evidence from multiple distant locations. | It answers from one section while ignoring conflicts elsewhere. |
| Latency envelope | The run fits your user or batch SLA. | p95 latency or timeout rate is too high. |
| Accepted-output cost | The usable answer is affordable after retries and review. | Cheap tokens become expensive because many outputs are rejected. |
| Route stability | The result survives Preview changes and provider differences. | The same task shifts after model, alias, or provider updates. |
For self-hosting, the 1M context statement should be treated even more carefully. The model card can establish that the released model supports long context, but it does not buy the hardware, memory planning, serving stack, batching, observability, or evaluation harness. If local control is the reason to use DeepSeek V4, start with a smaller context ladder, record memory pressure and latency, then scale only after recall quality remains acceptable.
Open Weights, Providers, and Local Self-Hosting
The verified DeepSeek Hugging Face collection lists DeepSeek-V4-Flash, DeepSeek-V4-Flash-Base, DeepSeek-V4-Pro, and DeepSeek-V4-Pro-Base artifacts. The Pro and Flash model cards describe the Preview series, the MoE parameter counts, 1M context support, thinking modes, and MIT license. That is strong evidence for open-weight availability. It is not evidence that your local endpoint will behave like DeepSeek's hosted API.
Use the Hugging Face route when you need control: local research, privacy-sensitive pilots, model inspection, custom serving, or infrastructure experiments. Use the official API route when you need DeepSeek's hosted inference contract. Use a provider route when your buying or integration constraint is the provider itself. These are not quality tiers; they are different owners of runtime behavior.
OpenRouter and similar pages are useful because they show that provider routes exist and may offer their own routing layer. They do not replace DeepSeek's official docs. A provider can have different price display, context handling, token accounting, logs, fallback behavior, moderation, rate limits, or support response. If you switch providers after testing the official API, re-run the same evaluation instead of assuming results transfer.
When to Use the GPT Comparison Instead
Keep the DeepSeek decision separate from the broader vendor comparison. The immediate job is to know whether DeepSeek V4 Preview is official, which V4 IDs exist, how Flash and Pro should be tested, what 1M context means, and how API, open weights, providers, and local routes differ.
If your actual decision is OpenAI versus DeepSeek, use the sibling route comparison: GPT-5.5 vs DeepSeek-V4. That route comparison covers GPT-5.5 in ChatGPT/Codex, current OpenAI API fallback, DeepSeek V4 API, and DeepSeek open weights. Do not force the cross-vendor decision into a DeepSeek-only evaluation unless your immediate question is still inside DeepSeek's own V4 Preview family.
Production Checklist
Before moving traffic to DeepSeek V4 Preview, make the test boring and measurable:
- lock the candidate model ID as
deepseek-v4-flashordeepseek-v4-pro; - record whether the route is official API, provider, Hugging Face weights, or local serving;
- run the same prompt set across Flash and Pro before promoting either;
- include at least one long-context recall test if 1M context is part of the reason to switch;
- measure accepted-output cost, not only token price;
- test streaming, tool calls, JSON output, and thinking mode only where your application uses them;
- document alias retirement risk for any old
deepseek-chatordeepseek-reasonerclients; - re-check pricing, discounts, and provider terms before publishing user-facing claims.
The practical answer is route first, then model. Flash is the first lane for measurable high-volume work. Pro is the first lane for harder failure-expensive work. Hugging Face weights are a control route. Provider pages are separate contracts. Local self-hosting is an infrastructure decision. DeepSeek V4 Preview is real, but the production answer is still the result of your own route-specific test.
FAQ
Is DeepSeek V4 Preview official?
Yes. DeepSeek's April 24, 2026 release note says DeepSeek V4 Preview is officially live and open-sourced, and the API docs list V4 model IDs. Keep the Preview qualifier because availability, pricing, aliases, and model behavior can still change.
What are the correct DeepSeek V4 API model IDs?
Use deepseek-v4-pro or deepseek-v4-flash. Do not use deepseek-v4-preview as a model ID in code. Treat deepseek-chat and deepseek-reasoner as compatibility aliases with a scheduled retirement, not as the preferred new production names.
Should I test DeepSeek-V4-Flash or DeepSeek-V4-Pro first?
Test Flash first when the task is high-volume, latency-sensitive, cost-sensitive, and objectively measurable. Test Pro first when the work is harder, the failure cost is high, or the task involves coding, agents, multi-step reasoning, or long-context synthesis.
Does DeepSeek V4 support 1M context?
DeepSeek's release note, pricing page, and verified Hugging Face model cards all support the 1M-context claim for the V4 family. Treat it as a capability to validate. Long inputs still need recall tests, latency measurement, accepted-output cost tracking, and route-specific checks.
Are the DeepSeek V4 weights open?
DeepSeek's verified Hugging Face collection includes Pro, Pro-Base, Flash, and Flash-Base artifacts, and the model cards list MIT license. That proves open-weight availability, not hosted API behavior or local deployment readiness.
Is OpenRouter official DeepSeek API access?
No. OpenRouter is a provider route. It may be useful, but its pricing, routing, fallback, logs, quotas, support, and model freshness are the provider's contract. Use DeepSeek's own docs for first-party API claims.
Can I run DeepSeek V4 locally with 1M context?
You can evaluate the open weights locally, but 1M context locally is an infrastructure problem as much as a model feature. Validate GPU capacity, serving stack, memory pressure, latency, recall, and accepted-output cost before treating local 1M context as production-ready.