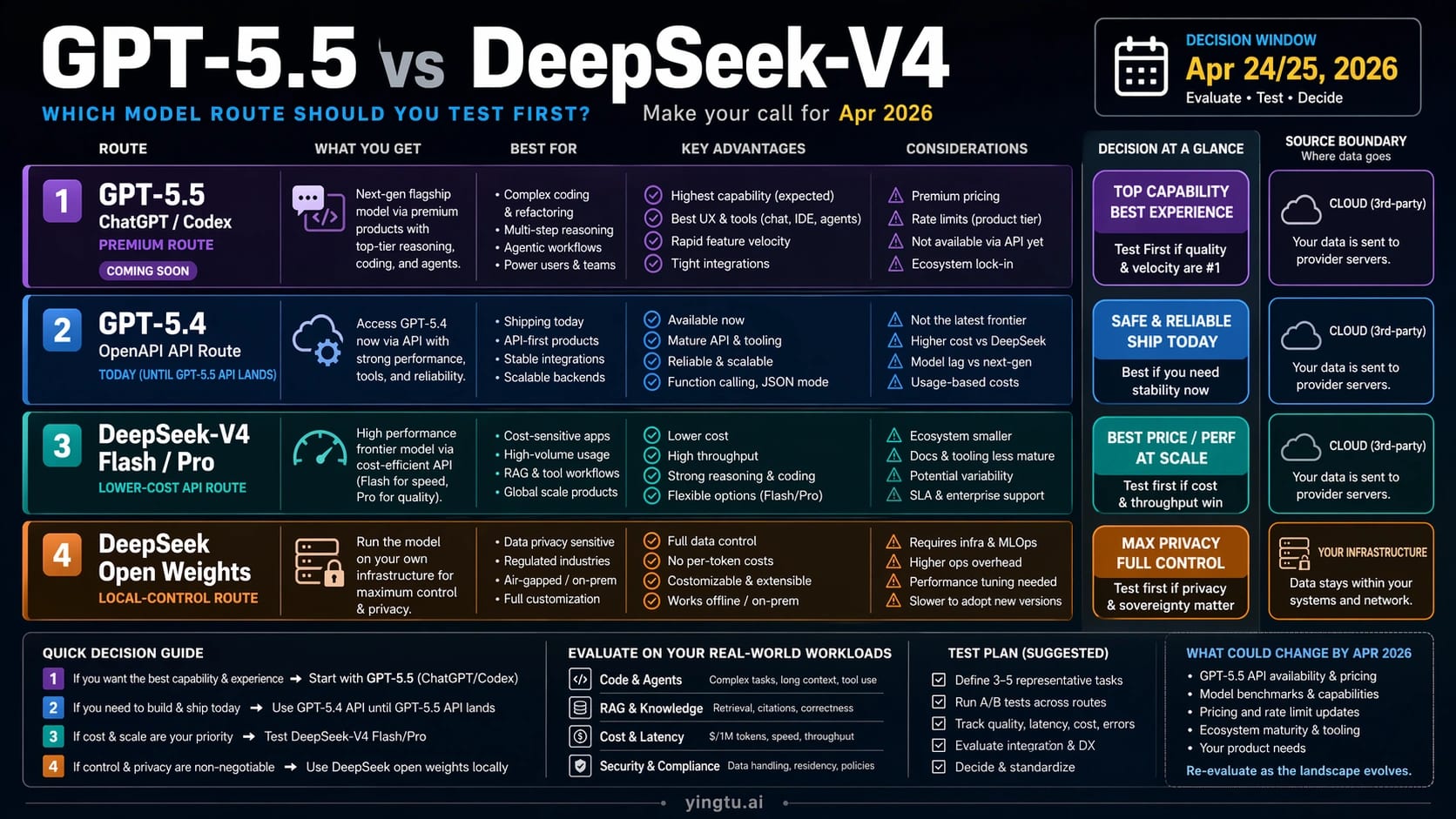
As of April 24/25, 2026, GPT-5.5 and DeepSeek-V4 are not interchangeable API choices. Start with GPT-5.5 when the work belongs in ChatGPT or Codex, keep GPT-5.4 for OpenAI API production until GPT-5.5 API access lands, and test DeepSeek-V4-Flash or DeepSeek-V4-Pro when low API cost, 1M context, or open weights matter more than staying inside OpenAI.
| Route | Test first when | Hold back when |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | You want OpenAI's strongest premium coding, agent, and reasoning experience in the ChatGPT or Codex surface. | You need a normal production API model today. |
| GPT-5.4 in the OpenAI API | You are shipping OpenAI API workflows now and need stable current API availability. | You are evaluating the next frontier route and can wait for GPT-5.5 API access. |
| DeepSeek-V4-Flash or V4-Pro API | You need lower-cost API throughput, long-context testing, or a DeepSeek-native capability check. | You need OpenAI-native tooling, enterprise support, or a proven quality baseline in your own stack. |
| DeepSeek-V4 open weights | You need local control, MIT-licensed weights, privacy, or self-hosted long-context experiments. | You do not want infrastructure, MLOps, or model-serving responsibility. |
Treat benchmark tables as evidence for choosing tests, not as a universal winner label. Before replacing production traffic, run the same tasks through the selected routes, measure quality, latency, cost, tool behavior, error recovery, and data handling, and revisit the decision when OpenAI exposes GPT-5.5 API access.
The Practical Answer: Pick a Route, Not a Winner
The useful comparison is not "which name is smarter in every situation?" The useful comparison is "which route can a developer test or ship today, and what would make that route change?" GPT-5.5 currently lives first as an OpenAI-native experience: ChatGPT, Codex, and premium product surfaces where OpenAI controls the surrounding tools, memory, interface, and deployment path. DeepSeek-V4 currently gives developers a more direct API and open-weight evaluation path, with lower hosted prices and a self-hosting option for teams that can handle infrastructure.
That asymmetry changes the decision. A team building a Codex-driven engineering workflow should not treat DeepSeek-V4 as a drop-in replacement for the whole OpenAI product experience. A team shipping a cost-sensitive API workload should not wait for GPT-5.5 API availability when DeepSeek-V4-Flash and DeepSeek-V4-Pro can be tested now. A team already on the OpenAI API should keep GPT-5.4 as the current production baseline until GPT-5.5 appears in the API model list and the pricing, limits, tool behavior, and migration path can be measured directly.
The first evaluation slot should follow the job:
| Workload | First route to test | Reason |
|---|---|---|
| Premium coding in ChatGPT or Codex | GPT-5.5 | The model and the product surface are designed together. |
| OpenAI API production today | GPT-5.4 | It is the current API baseline while GPT-5.5 API access is pending. |
| High-volume hosted API calls | DeepSeek-V4-Flash | It has the lowest current DeepSeek-V4 hosted token price. |
| Higher-capability DeepSeek API evaluation | DeepSeek-V4-Pro | It is the stronger hosted DeepSeek-V4 route when quality matters more than minimum cost. |
| Local control or open-weight testing | DeepSeek-V4 open weights | The Hugging Face artifacts support local experiments under the published license terms. |
Availability and Pricing: What You Can Actually Use
OpenAI's GPT-5.5 launch announcement positions GPT-5.5 as a new premium model for ChatGPT and Codex. The announcement also previews GPT-5.5 API pricing, but OpenAI's latest-model API guide still keeps GPT-5.4 as the current OpenAI API route as of April 24/25, 2026. That makes GPT-5.5 a strong route for OpenAI-native usage now, not a normal production API peer to DeepSeek-V4 yet.
DeepSeek's API pricing page lists hosted DeepSeek-V4 routes now: deepseek-v4-flash and deepseek-v4-pro. The same docs also describe OpenAI-compatible and Anthropic-compatible endpoints, which matters for teams that want to test a DeepSeek route without redesigning every client abstraction at once. DeepSeek aliases such as deepseek-chat and deepseek-reasoner currently map into V4-Flash modes, but production code should prefer explicit model IDs where possible so a future alias change does not silently change behavior.
| Route | Current access status | Pricing signal as of April 24/25, 2026 |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | Available through OpenAI product surfaces listed in the launch announcement. | Product subscription or workspace access, not normal API token billing. |
| GPT-5.5 API | Announced as coming soon. | Announced future API price: $5 input and $30 output per 1M tokens. |
| GPT-5.5 Pro API | Announced as coming soon. | Announced future API price: $30 input and $180 output per 1M tokens. |
| GPT-5.4 API | Current OpenAI API fallback route. | Use OpenAI's current API pricing and model guide before shipping. |
| DeepSeek-V4-Flash API | Listed in current DeepSeek API docs. | Cache hit $0.028, cache miss $0.14, output $0.28 per 1M tokens. |
| DeepSeek-V4-Pro API | Listed in current DeepSeek API docs. | Cache hit $0.145, cache miss $1.74, output $3.48 per 1M tokens. |
| DeepSeek-V4 open weights | Published through official model-card artifacts. | Infrastructure cost replaces hosted token billing. |
The price gap is real, but it should not be read as a quality verdict. DeepSeek-V4-Flash is extremely attractive for high-volume extraction, classification, summarization, routing, and long-context screening workloads if it meets the task quality bar. DeepSeek-V4-Pro is still far below the announced GPT-5.5 API price and is the more useful DeepSeek test when the task demands stronger reasoning or agent behavior. GPT-5.5, meanwhile, may justify a higher price in workflows where the surrounding OpenAI product route saves engineering time or produces fewer failures.
Benchmark Evidence: Useful, but Not a Universal Scoreboard
Benchmark rows help choose evaluation tasks, but the rows available today are source-attributed rather than a single neutral same-harness leaderboard. OpenAI reports GPT-5.5 numbers for coding, browsing, and agentic work in its launch material, including Terminal-Bench 2.0 at 82.7, SWE-Bench Pro public at 58.6, BrowseComp at 84.4, and GPT-5.5 Pro at 90.1 on BrowseComp. DeepSeek's DeepSeek-V4-Pro model card reports DeepSeek-V4-Pro-Max numbers such as Terminal-Bench 2.0 at 67.9, SWE Verified at 80.6, SWE Pro at 55.4, BrowseComp at 83.4, MCPAtlas Public at 73.6, and Toolathlon at 51.8.
Those figures point to two practical readings. First, GPT-5.5 looks especially strong when the workflow is coding, browsing, and OpenAI-native agent execution. Second, DeepSeek-V4 is not just a budget model family; its reported SWE Verified, browsing, tool, and long-context signals justify a real evaluation for developer workflows, especially when cost or open weights matter. The gap that matters for production is the gap on your own tasks, not the bold cell in a provider table.
Use benchmarks to build a test matrix:
| Evidence area | What the public rows suggest | What to verify locally |
|---|---|---|
| Coding changes | GPT-5.5 has strong OpenAI-reported coding and terminal scores; DeepSeek-V4-Pro reports competitive software scores. | Multi-file edits, repo navigation, test repair, dependency handling, and patch review quality. |
| Tool and agent behavior | Both families publish tool or browsing evidence, but not always on the same harness. | Function calling accuracy, tool argument discipline, retry behavior, and recovery after partial failures. |
| Long-context work | DeepSeek-V4 emphasizes 1M context and high output ceilings; GPT-5.5 also previews a 1M context API route. | Retrieval accuracy, late-context recall, instruction persistence, and cost at realistic prompt sizes. |
| Production reliability | Public benchmarks rarely expose rate-limit pain, latency variance, or data-handling fit. | p95 latency, refusal rate, timeout behavior, structured output validity, and audit requirements. |
The safe conclusion is asymmetric: GPT-5.5 deserves the first look for OpenAI-native premium work, while DeepSeek-V4 deserves the first API cost and open-weight evaluation. Neither public evidence set removes the need for a dual run before migration.
Choosing Inside DeepSeek-V4: Flash, Pro, or Open Weights
DeepSeek-V4 is a family decision, not a single row. Hosted API users should separate V4-Flash, V4-Pro, and open weights before comparing the family to GPT-5.5.
DeepSeek-V4-Flash is the default first test when the workload is high volume and the quality requirement is measurable. It fits extraction, reranking, classification, short answers, batch summarization, and other tasks where a lower-cost model can be rejected automatically when it misses format or accuracy checks. The very low cached-input price also makes it attractive for repeated context, stable system prompts, or workflows where many requests share the same document base.
DeepSeek-V4-Pro is the first DeepSeek route when the task is harder and a weak answer is expensive. It should be tested for coding agents, multi-step reasoning, long-context synthesis, and workflow automation where Flash may produce a plausible but brittle result. The hosted price remains much lower than the announced GPT-5.5 API price, so Pro can still be economical if it avoids retries or manual cleanup.
DeepSeek-V4 open weights are for teams that need local control more than hosted convenience. The model-card artifacts describe an MIT-licensed route and a large mixture-of-experts architecture, but self-hosting changes the cost model. Token price disappears, but GPU capacity, serving latency, batching, monitoring, updates, security, and staff time become the bill. This route is rational when data locality, customization, or infrastructure control is a first-order requirement.
DeepSeek also exposes thinking modes and long-output possibilities that should be tested with realistic prompts. A model that performs well at 20K tokens can behave differently at 300K or 800K tokens. Long-context tests should include distractors, late-file references, conflicting instructions, and final-answer checks that prove the model used the relevant parts of the context rather than summarizing the beginning.
Workflow Recommendations
For coding inside OpenAI's product surfaces, start with GPT-5.5. The value is not only model quality; it is the combination of model, Codex workflow, editor or terminal integration, review loop, and OpenAI account controls. If the task is codebase repair, multi-step reasoning, or agentic debugging inside Codex, DeepSeek-V4 should be treated as an alternative route to evaluate separately, not as a direct replacement for the whole experience.
For OpenAI API applications already in production, keep GPT-5.4 as the stable baseline until GPT-5.5 API access is live and documented in the API model guide. Build an abstraction that can add GPT-5.5 later, but do not quote GPT-5.5 as the production API model in user-facing promises, sales material, or SLA planning before access is actually available.
For cost-sensitive API workloads, test DeepSeek-V4-Flash first. The expected win is not just cheaper input tokens; it is the ability to run more candidates, add verification passes, or process larger context at a lower total cost. If Flash fails on reasoning, tool discipline, or long-context faithfulness, promote only the hard slices to DeepSeek-V4-Pro and keep Flash for the routine slices.
For high-stakes reasoning or coding where OpenAI product access is not enough, compare DeepSeek-V4-Pro against GPT-5.4 API today and against GPT-5.5 API when it arrives. The winner should be decided by task-specific scoring: accepted patches, passing tests, valid JSON, correct citations, stable tool calls, and human review time saved. A cheaper model that needs two retries and a manual repair may cost more operationally than the token table suggests.
For privacy, regulated data, or custom serving requirements, evaluate DeepSeek-V4 open weights in a small controlled deployment before promising broad internal migration. The open route can be valuable, but it should be judged as an infrastructure project as well as a model evaluation.
Production Test Plan Before Migration
The migration plan should be deliberately small. Pick three to five representative tasks, not a hundred generic prompts. Each task should include the input, expected output contract, quality rubric, retry policy, cost measurement, and failure severity. Use real examples from production logs or internal workflows after removing sensitive data that should not leave the approved environment.
Run each task through the relevant current routes:
| Test lane | Use when | Measure |
|---|---|---|
| GPT-5.5 in ChatGPT/Codex | The task depends on OpenAI-native product workflow. | Completion quality, user effort saved, code-review outcome, and interface fit. |
| GPT-5.4 API | The task is already an OpenAI API workload. | Baseline quality, cost, latency, tool calls, structured output validity, and regression risk. |
| DeepSeek-V4-Flash API | The task is high-volume or cost-sensitive. | Pass rate, retry rate, format validity, cache behavior, and total cost per accepted output. |
| DeepSeek-V4-Pro API | The task needs stronger reasoning but still needs DeepSeek economics. | Accuracy, reasoning stability, tool behavior, long-context recall, and cost versus retries. |
| DeepSeek-V4 open weights | The task needs local control. | Serving latency, GPU cost, throughput, update process, security, and observability. |
Set stop rules before testing. Do not migrate a route that fails structured output checks, silently drops tool arguments, ignores late-context evidence, creates unsafe code changes, or requires manual review that erases token savings. Do not promote a route to production only because it is cheaper on a clean prompt. The migration candidate must win on accepted output cost, not raw token cost.
Revisit the decision when OpenAI lists GPT-5.5 API access in the live API docs, when DeepSeek changes V4 pricing or aliases, or when independent same-harness evaluations become available. Until then, the most defensible answer is route-first: GPT-5.5 for OpenAI-native premium work, GPT-5.4 for OpenAI API production today, DeepSeek-V4-Flash for cost-sensitive hosted API tests, DeepSeek-V4-Pro for stronger DeepSeek evaluation, and DeepSeek open weights for local-control projects.
FAQ
Is GPT-5.5 available in the API today?
OpenAI has announced GPT-5.5 API pricing and says API access is coming soon, but the current API model guidance as of April 24/25, 2026 still keeps GPT-5.4 as the production OpenAI API route. Treat GPT-5.5 as available for ChatGPT and Codex surfaces now, and wait for the live API docs before planning normal GPT-5.5 API production.
Which DeepSeek-V4 model should I test first?
Start with DeepSeek-V4-Flash when cost and volume matter and the task has a clear automatic acceptance check. Start with DeepSeek-V4-Pro when reasoning quality, coding reliability, or tool behavior matters more than the lowest token price. Use open weights when local control, data boundary, or self-hosting flexibility is the main requirement.
Do the pricing tables mean DeepSeek-V4 is automatically better value?
No. DeepSeek-V4 has a major hosted price advantage, especially through V4-Flash, but value depends on accepted output cost. A cheaper route is only better when it meets the quality bar without extra retries, manual repair, or downstream failures.
Should benchmarks decide the winner?
No. Public benchmark rows are useful for choosing which tasks to test first, but the current rows are source-attributed and not always from one independent same-harness comparison. Use them to form hypotheses, then score the same production tasks across the candidate routes.
When should the recommendation change?
Recheck the decision when GPT-5.5 becomes available in the OpenAI API docs, when DeepSeek updates V4 pricing or aliases, when independent same-harness benchmark work appears, or when your own task mix changes. The route choice is not permanent; it should follow access, quality, cost, and operational risk.