If GPT Image 2 looks noisy, dirty, tiled, blurry, or lower quality than expected, check the request settings and generation context before you regenerate. quality: "low" is a real draft-oriented setting, but grime, tiling, unwanted texture, compression, and reference carryover need a different test.
Start with this split:
| What looks wrong | Check first | First fix | Evidence owner |
|---|---|---|---|
| The whole image looks soft or low-detail | quality, size, and whether the output was compressed after generation | Compare medium or high quality before final approval | OpenAI docs for settings |
| The image has dirty texture, grime, repeated tiles, or odd overlay | Fresh chat or fresh API request, then remove reference images | Reproduce once in clean context before changing the prompt | Community reports for symptom language |
| Edits inherit unwanted texture or style | Reference image, edit mask, previous chat context, or wrapper defaults | Run a clean generation without the inherited reference | Your own clean comparison |
| High-resolution output looks inconsistent | Requested size, target aspect ratio, and post-save inspection | Save the original output and inspect at the final display size | OpenAI docs plus local output check |
| Only one route looks bad | ChatGPT, Image API, Responses image tool, or provider wrapper | Hold prompt and model constant, then change only the route | Same-prompt route comparison |
Stop rule: do not approve a final asset until you have saved the original output, compared at least one medium or high-quality run, and reproduced persistent grime or tiling in a clean context. If the clean repro still shows the same artifact, preserve the prompt, settings, route, timestamp, and output file before escalating or switching route.
Separate the quality setting from the quality complaint
The first trap is language. "Low quality" can mean two different things.
In the API, quality is a controllable output setting. OpenAI's image generation documentation describes low, medium, high, and auto quality choices for GPT Image models. In normal workflow terms, low belongs to drafts, thumbnails, and fast iteration. It is not the setting you should use to approve a final product shot, poster, UI board, or paid campaign asset.
In user reports, "low quality" often means the image looks bad: smeared details, low texture fidelity, repeated tiles, a dirty overlay, unnatural grime, compressed edges, or fuzzy text. That complaint may be related to the quality setting, but it is not the same thing. A bad-looking result can come from a small output size, a high-resolution branch that is still variable, a reference image that carries texture into the edit, a long chat that keeps context you no longer want, or a wrapper that rewrites defaults.
Use this rule: settings first, root-cause claims later. If the request used quality: "low", you do not yet have an artifact investigation. You have a draft-quality output. If the same prompt still shows grime, tiling, or odd texture after a clean medium or high-quality run, then you have a symptom worth preserving and comparing.
Check quality, size, and output handling first
The fastest clean test is mechanical. Do not change the prompt yet. Change only one request variable at a time.
First, inspect quality. If you are using the Image API or a Responses image tool, log the actual outgoing request, not only the UI value. A wrapper can default to auto, hide a quality selector, or silently downgrade a preview route. If you used low, rerun once at medium before spending on high. If the image is for final approval, compare one high output against the best medium result so you can see whether the added cost changes the actual defect.

Second, inspect size. GPT Image 2 supports documented size controls, and high-resolution output above 2560x1440 should be treated as a more experimental branch. A file can be large and still look wrong, but a small or compressed file can also make a good generation look worse than it is. Save the original output before resizing, uploading to a CMS, or converting it for web delivery.
Third, inspect output format and compression. If the image looks soft only after download, social upload, CMS conversion, or WebP/JPEG compression, the model may not be the problem. Compare the original generated file, the published file, and a lossless export. If the original looks clean and the final web asset looks bad, fix the delivery pipeline before touching the prompt.
Fourth, verify that the route supports the setting you think you used. Direct Image API generation, image editing, and Responses API image tools are related but not identical surrounding workflows. The model ID may be gpt-image-2, but the UI or integration can still change defaults, handle image inputs differently, or compress outputs after generation.
Run a clean-context test before rewriting the prompt
If medium or high quality still looks wrong, isolate context before rewriting the prompt. Context problems are easy to misread as model problems because they look like style failure, not state failure.
For ChatGPT, open a fresh chat. Do not continue the same long thread that already contains style examples, failed attempts, screenshots, or corrections. Long conversations can push the next image toward patterns you no longer want. If the fresh chat produces a cleaner image with the same core prompt, the old session was part of the issue.
For API work, send a fresh request with the same prompt and no reference image. Then add the reference image back. If the defect returns only when a reference is present, the reference is carrying texture, lighting, noise, compression, edges, or unwanted style into the result. The next fix is not "make it better" in the prompt. It is to clean the reference, change the mask, remove inherited images, or generate a new base image.

For wrappers or provider routes, compare a direct first-party route if you have access. Keep the prompt, aspect ratio, and target quality constant. If the wrapper route looks worse, you still do not know whether GPT Image 2 is worse; you know that the wrapper's defaults, compression, model mapping, or post-processing may be different.
This clean-context test is valuable even when it does not fix the image. A preserved repro is better evidence than a vague complaint. Record the prompt, model label, quality, size, route, whether a reference image was used, whether the output was edited, and the original file. That makes the next escalation concrete.
When dirty texture, tiling, or grime persists
Some users describe GPT Image 2 outputs as having dirty texture, repeated tiling, grime, or a strange overlay even when the prompt did not ask for it. Treat that as a reported artifact symptom unless OpenAI publishes a specific root-cause explanation for the case you are seeing.
The wording matters. It is fair to say "reported artifact" when a community thread, developer forum post, or your own clean repro shows a repeated symptom. It is not fair to say "OpenAI confirmed a model-wide bug" unless you have first-party status or release-note evidence. Overclaiming makes the article less useful because it skips the controllable checks the reader can run immediately.
Use this artifact triage:
| Symptom | Do first | Do not do yet |
|---|---|---|
| Dirty overlay or grime appears across unrelated prompts | Run a fresh medium-quality request with no references | Do not assume a prompt pack will fix it |
| Repeated texture or tiles appear in a specific edit | Remove or replace the reference image and mask | Do not keep editing the same contaminated base |
| Noise appears only after publishing | Compare original output with compressed delivery file | Do not blame GPT Image 2 before checking export |
| Defect appears only in high-resolution output | Test a smaller approved master and upscale separately | Do not assume native high-res is always the safest route |
| Defect appears only through one provider route | Compare a direct route or another documented route | Do not call it an official GPT Image 2 failure without route evidence |
If the symptom persists after a clean request, keep the repro narrow. A good repro says: same prompt, no reference image, model: "gpt-image-2", selected quality, selected size, route used, timestamp, and original output. A weak repro says: "it looks bad again" after five unrelated prompt changes.
Image API versus Responses API versus ChatGPT
The right fix depends on where the image was generated.
Use ChatGPT when you are manually exploring prompts, comparing a few concepts, or editing inside the consumer app. The first fix there is often a fresh chat, a shorter prompt, a cleaner reference, or a smaller request. You may not see every underlying API parameter, so the diagnosis focuses on visible route state: fresh chat, references, edits, downloads, and manual comparison.
Use the Image API when you need the clearest developer repro. The request can name gpt-image-2, set quality, choose size, handle input images, and save the returned image data. This is the easiest route to log because you control the request body and file handling.
Use the Responses API image tool when image generation belongs inside a broader assistant flow. That route is useful for multi-step applications, but it can make quality diagnosis harder if the surrounding assistant rewrites the prompt, adds context, or chooses a tool option automatically. For a quality bug, reduce the flow to the smallest image-generation call that reproduces the problem.
Use a provider wrapper only when you can see enough route detail to trust the comparison. A wrapper may be useful for access, testing, or multi-model evaluation, but a low-quality output through a wrapper is not automatically evidence against the first-party model. Check model label, quality support, size support, compression, retry behavior, and whether the provider modifies prompts or images.
For broader route choices, use a sibling comparison after this diagnosis is complete. If you are deciding whether to switch models, see the GPT Image 2 vs Nano Banana Pro route guide. If the real question is provider cost, use the cheap GPT Image 2 API guide. Keep those decisions separate from the immediate quality triage.
High resolution can expose different failures
Do not assume that high resolution and high quality are the same fix. High resolution changes the canvas. Quality changes generation effort or detail level. Output format and compression change delivery. A large image can still have bad texture, and a good image can be made worse by resizing or compression.
For native high-resolution GPT Image 2 work, validate the API size first. If the target is 4K, follow the dedicated GPT Image 2 4K size and verification guide. That topic has its own constraints: exact landscape and portrait sizes, custom-size rules, and the need to inspect the saved file.
For a low-quality complaint, ask a narrower question: does the artifact appear only at the larger size? If yes, try a smaller master at medium or high quality, approve the composition, and then choose whether native high-res, upscale, or a separate production route is safer. If the artifact appears at every size, the problem is probably not just resolution.
This is especially important for images with dense text, UI boards, product edges, or repeated patterns. A high-resolution request may make errors easier to see. It may also make failure cost higher. Approve the concept before spending repeated high-quality high-res attempts.
Production acceptance checklist
The final check should be boring and repeatable.
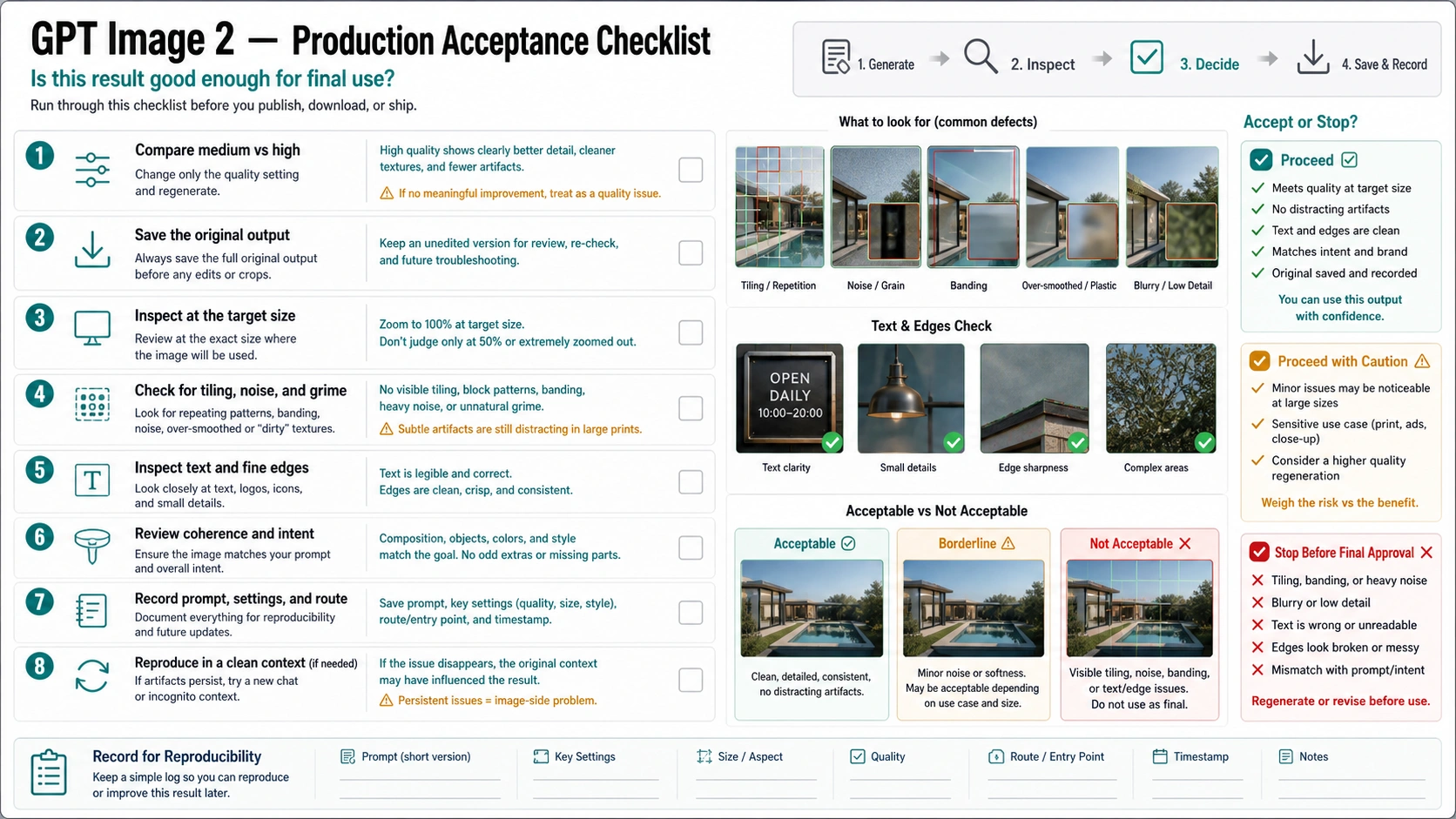
Use a small acceptance packet before approving a GPT Image 2 asset:
| Check | Pass condition |
|---|---|
| Original saved | You have the original generated file before compression, resize, upload, or CMS processing |
| Settings recorded | You know model, route, quality, size, reference images, and whether it was an edit |
| Medium/high compared | At least one non-low-quality run was inspected before final approval |
| Target size inspected | The image was viewed at the final display or print size |
| Artifact scan complete | Tiling, grime, noise, edge defects, text errors, and repeated texture were checked |
| Clean repro attempted | Persistent defects were tested in a fresh chat or fresh API request |
| Stop rule applied | If defects persist in clean context, the asset is not approved as final |
This checklist is not bureaucracy. It prevents the two most expensive mistakes: rerunning the same contaminated setup because the prompt feels close, and shipping a compressed or artifact-heavy asset because the preview looked acceptable in a small UI.
When the image passes, you have a usable asset and a record of how it was made. When it fails, you have enough evidence to choose the next branch: change quality, change size, clean references, reset context, check export, compare the same prompt across routes, or escalate with a narrow repro.
What not to conclude too early
Do not conclude that GPT Image 2 is broken for everyone because one route produced a bad image. The useful question is narrower: which setting, route, input, context, size, or output step can you control now?
Do not conclude that quality: "high" always fixes artifacts. It is a valid final-comparison setting, but reported grime, tiling, or inherited texture may survive if the underlying context or reference is still contaminated.
Do not conclude that a free or third-party generator proves the official model is better or worse. Free access, browser testing, API billing, provider credits, and no-login wrappers are different contracts. If free route ownership is the actual question, use the GPT Image 2 free and unlimited route guide. If official API free-tier support is the only question, use the GPT Image 2 API free-tier guide.
Do not publish a final asset from a single small preview. Save the original, inspect the target size, compare a non-low-quality run, and keep a clean repro when something persists.
FAQ
Is quality: "low" the reason GPT Image 2 looks bad?
It can be. quality: "low" is meant for drafts, thumbnails, and quick iteration, so it should not be your final approval setting. But if grime, tiling, repeated texture, or unwanted overlay persists at medium or high quality in a clean context, treat it as a separate artifact symptom.
Should I always use quality: "high"?
No. Use low for draft exploration, medium for working previews, and high for final comparison or high-value assets. If the problem is reference carryover, session context, compression, or route defaults, high quality alone may not fix it.
Why does a fresh chat help with image quality?
A fresh chat removes old instructions, failed outputs, reference images, style corrections, and unwanted context from the next generation. If the same prompt looks cleaner in a fresh chat, the old session was part of the diagnosis.
Why does my image have grime, tiling, or dirty texture?
Those are reported artifact symptoms. Start by removing references, using a fresh chat or fresh API request, comparing medium or high quality, and saving the original output. Do not claim an official model-wide cause unless OpenAI publishes one for that symptom.
Can high resolution make GPT Image 2 look worse?
It can expose different failures. High-resolution output can make texture, text, and edge defects easier to see, and output above 2560x1440 should be treated carefully. If native high-res is inconsistent, approve a smaller master first and then decide whether to upscale or retry native high-res.
Is the Image API better than ChatGPT for troubleshooting?
For developer troubleshooting, yes, because the Image API makes it easier to log model, quality, size, input images, and saved output. ChatGPT is useful for manual testing, but you may not see every underlying setting.
What should I save before reporting a GPT Image 2 quality issue?
Save the original output file, prompt, model label, route, quality, size, reference images, edit mask if any, timestamp, and whether the issue reproduces in a fresh chat or fresh API request. That is much more useful than a screenshot after several unrelated prompt changes.