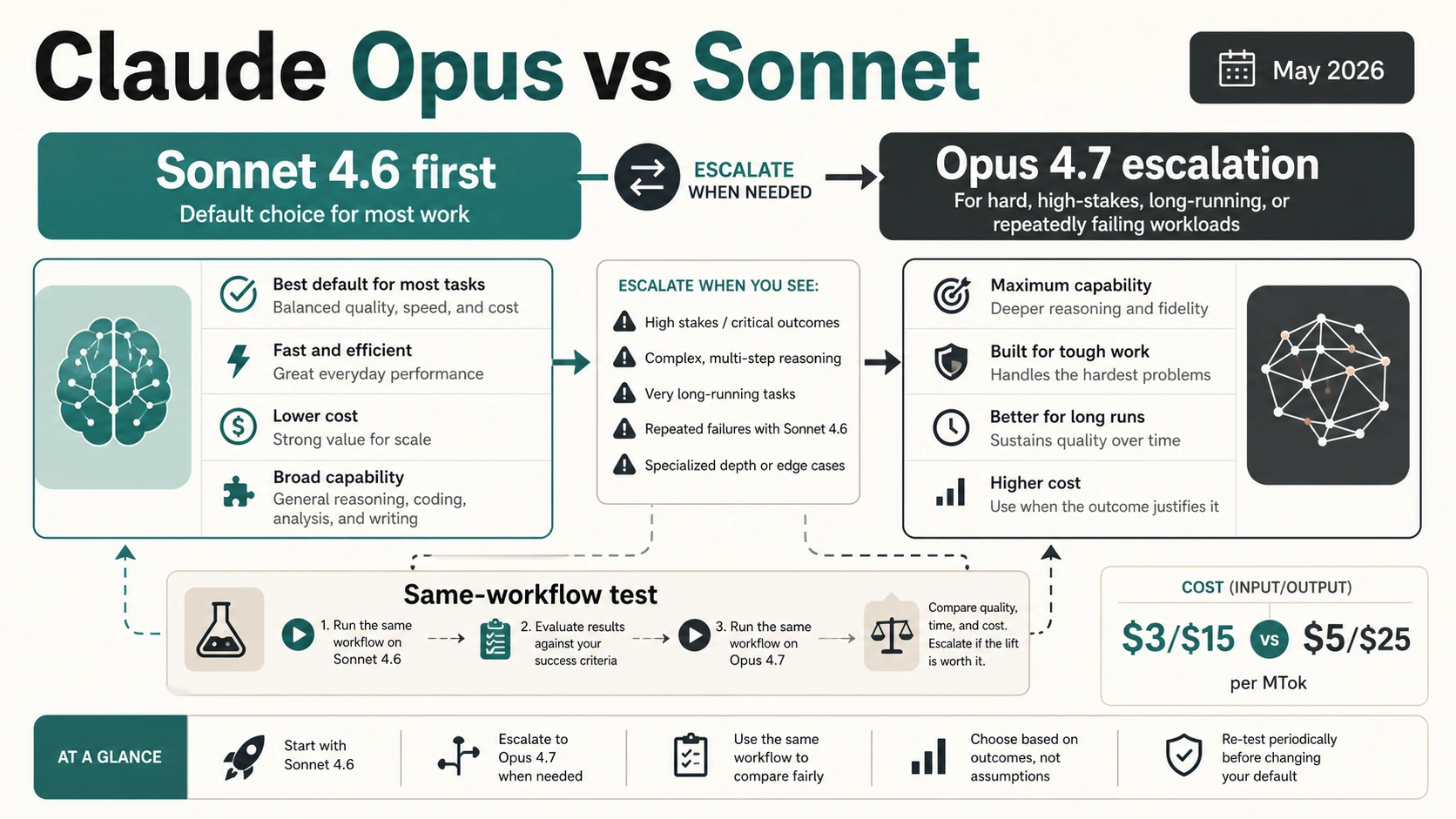
As of May 7, 2026, start with Claude Sonnet 4.6 for most Claude work and move to Claude Opus 4.7 only when the task is hard enough to justify the higher cost. Sonnet is the better default for speed, cost, and scale. Opus is the escalation model for high-stakes reasoning, ambiguous architecture work, long-running agents, document-heavy synthesis, or tasks that keep failing the same acceptance tests.
| If the workload looks like this | Try first | Escalate when |
|---|---|---|
| Daily coding, research, content, office work, browser or computer-use loops | Sonnet 4.6 | The answer needs repeated manual repair or misses the same acceptance test. |
| High-volume API production | Sonnet 4.6 | The cost of failures, retries, or review time is higher than the Opus premium. |
| Architecture decisions, root-cause debugging, complex multi-file reasoning | Opus 4.7 test lane | Keep Sonnet as a baseline if Opus does not improve the actual output enough. |
| Long-running agents or multi-step workflows | Sonnet baseline plus Opus comparison | Opus sustains better planning or fewer dead ends over the same run. |
| Mechanical extraction, cheap routing, simple transformations | Haiku 4.5 side lane | Promote to Sonnet before jumping to Opus. |
The public API price row is only the first cost signal. In Anthropic's current docs, Sonnet 4.6 is listed at $3 input and $15 output per million tokens, while Opus 4.7 is listed at $5 input and $25 output per million tokens. The real bill also changes with output length, prompt caching, batch eligibility, thinking effort, and the Opus 4.7 tokenizer note that the same fixed text may use more tokens depending on content.
The Current Comparison Is Opus 4.7 vs Sonnet 4.6
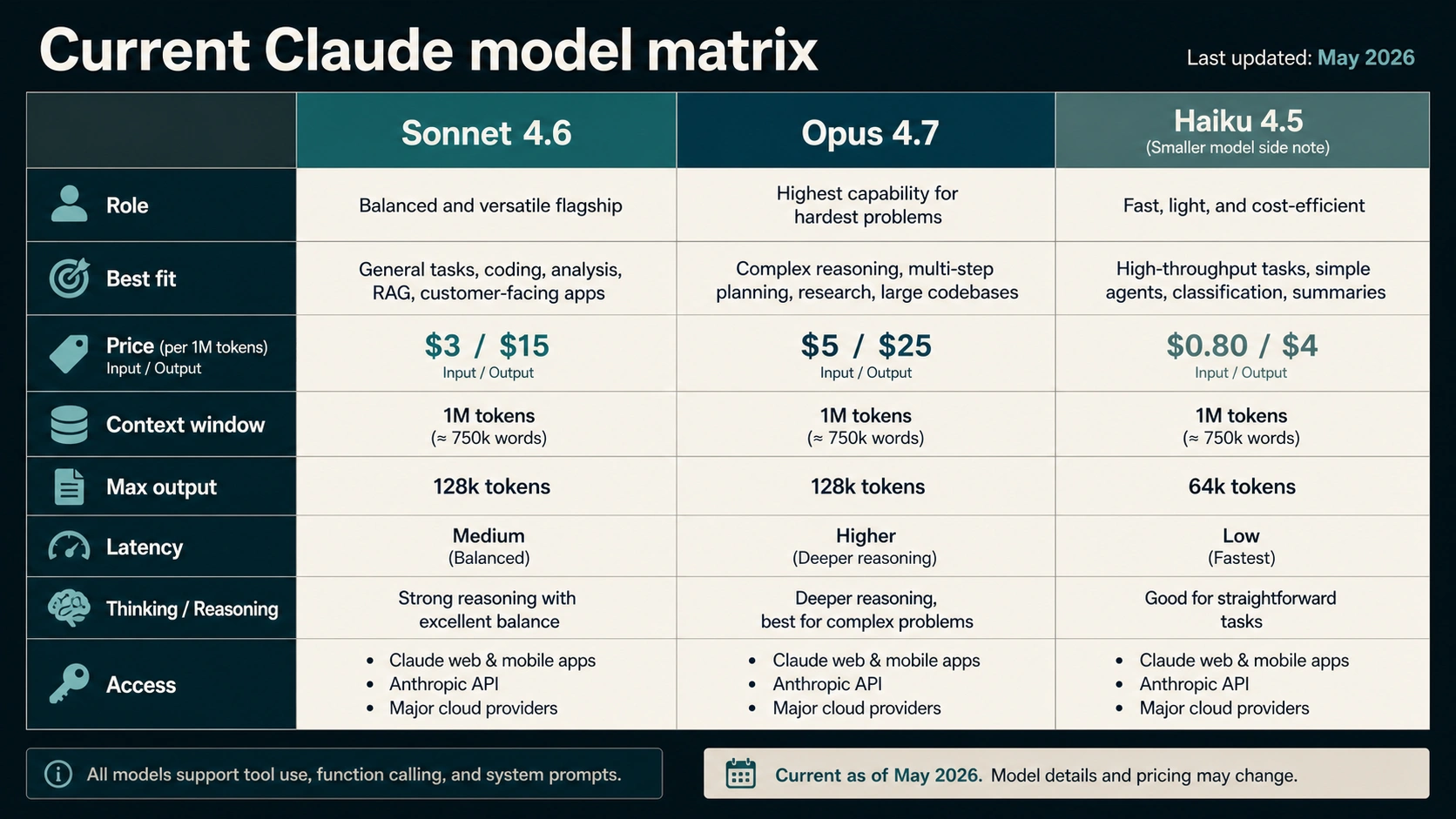
The current factual baseline is not older "Claude 4" wording. Anthropic's model overview lists Claude Opus 4.7, Claude Sonnet 4.6, and Claude Haiku 4.5 as the current primary tiers. That matters because many older comparison pages still discuss Opus 4, Opus 4.5, Opus 4.6, or Sonnet 4.5 as if they were the current choice.
Opus 4.7 is Anthropic's premium model for the hardest work. The Opus page positions it for professional software engineering, complex agentic workflows, advanced coding, and high-stakes enterprise tasks. It is available in Claude for Pro, Max, Team, and Enterprise users, and for developers through Claude Platform and supported cloud routes listed by Anthropic.
Sonnet 4.6 is Anthropic's balanced model. The Sonnet page and Sonnet 4.6 launch note position it for daily use, scaled production, coding, agents, browser and computer use, long-context reasoning, and cost-efficient performance. The launch note says Sonnet 4.6 became the default model in claude.ai and Claude Cowork for Free and Pro plans.
| Current official row | Sonnet 4.6 | Opus 4.7 |
|---|---|---|
| Practical role | Default model for most work | Escalation model for hardest work |
| API price checked May 7, 2026 | $3 input / $15 output per MTok | $5 input / $25 output per MTok |
| Latency tier in model overview | Fast | Moderate |
| Context window in model overview | 1M | 1M |
| Max output in model overview | 64k | 128k |
| Thinking support | Extended thinking plus adaptive thinking | Adaptive thinking |
| Best first use | Daily work, coding loops, scaled production | Hard reasoning, agentic coding, high-stakes decisions |
Haiku 4.5 is useful to mention only as a side lane. It is the fast and cheaper model when the task is mechanical enough that Sonnet is more model than needed. It should not take over an Opus versus Sonnet article unless the reader's real problem is a three-model family selection.
When Sonnet 4.6 Should Be the Default
Sonnet wins the default slot when a workflow needs speed, cost control, and reliable scale. That covers a lot of real Claude usage: everyday coding help, PR review support, documentation work, data cleanup, structured summaries, browser or computer-use flows, office analysis, content drafting, support triage, and many API production paths.
The reason is not that Sonnet is "cheap." The reason is that Sonnet often gives enough intelligence with lower latency and lower token price. If a task has clear instructions, a measurable output contract, and low failure severity, starting with Opus can waste money without changing the result. In production, this matters more than model prestige. A model that is good enough and cheaper can let you run more validations, keep more context, or add a second pass while still spending less than a single Opus run.
Use Sonnet first when:
- the output is easy to validate automatically;
- the task is frequent enough that token cost matters;
- the workflow needs fast iteration more than maximal depth;
- the prompt is well structured and the success criteria are clear;
- the model only needs to follow a process rather than invent a strategy;
- failures can be caught by tests, schemas, review, or retry logic.
For Claude app users, Sonnet is also the natural starting point because it is the ordinary balanced route. For API users, it should usually be the first production candidate because the current official price row is lower and the model is designed for scaled use.
When Opus 4.7 Is Worth Testing
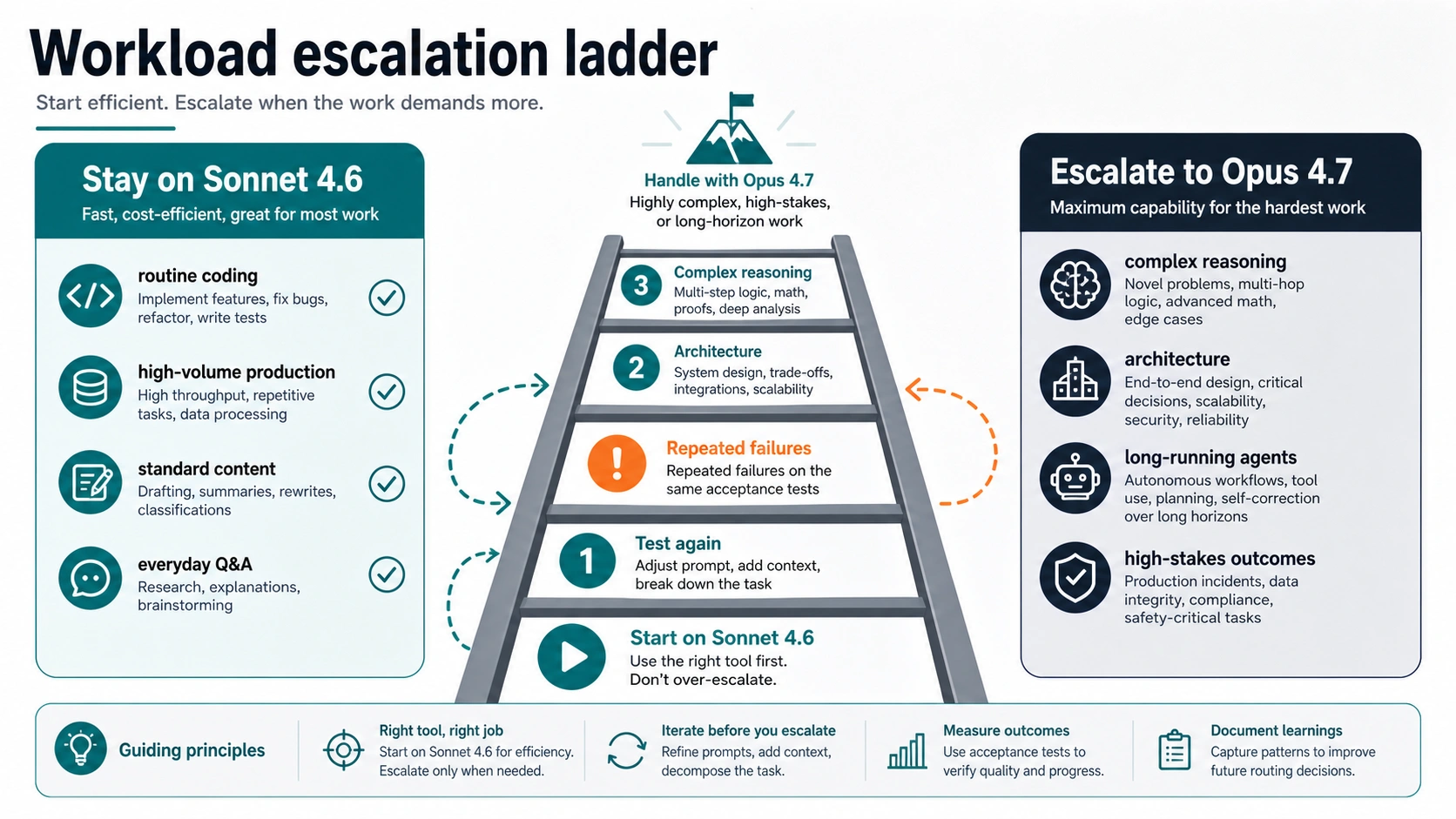
Opus becomes worth testing when the failure mode is expensive, ambiguous, or too hard for a cheap retry loop. The best Opus tasks are not merely "important" tasks. They are tasks where deeper reasoning, better long-run planning, or more consistent handling of messy context can change the outcome.
Use Opus 4.7 for a test lane when:
- Sonnet keeps missing the same acceptance criterion after prompt cleanup;
- the task requires architecture tradeoffs across multiple files, systems, or constraints;
- the model must reason through a long document set and preserve nuance;
- a long-running agent keeps losing the plan, looping, or taking brittle shortcuts;
- the answer will drive a high-stakes engineering, legal, financial, or enterprise decision;
- the task involves root-cause debugging where a plausible shortcut is more costly than a slower answer;
- review time is the largest cost and a better first answer would save human effort.
Opus is not a moral upgrade for every prompt. It is an escalation route. If Opus gives the same answer Sonnet gives, or only improves polish, keep Sonnet. If Opus prevents a bad architecture decision, catches a hidden dependency, or finishes a long agent run that Sonnet cannot sustain, the premium can be justified.
The cleanest mental model is: Sonnet is the default operating model; Opus is the escalation model when the task's failure cost is higher than the model premium.
The Cost Difference Is Bigger Than the Price Row
Anthropic's pricing page is the right source for token-price rows, but the price row is not the full workload cost. Sonnet's $3/$15 and Opus's $5/$25 per million tokens show the base gap. Real spend can move because of output length, cache behavior, batch usage, thinking settings, tool schemas, repeated context, and retries.
The current pricing page also notes that Opus 4.7 uses a new tokenizer and may use up to 35% more tokens for the same fixed text depending on content. That does not mean every Opus run costs 35% more than the price row implies. It means you should not estimate a migration by multiplying last month's Sonnet token count by the Opus price alone. Re-run the workload and measure real input tokens, output tokens, retries, and accepted-output cost.
| Cost layer | Why it changes the decision |
|---|---|
| Base input and output price | Opus costs more per token than Sonnet in the current official row. |
| Output length | Opus may write longer or deeper answers unless the output budget is constrained. |
| Prompt caching | Cache hits can lower repeated-input cost, but cache writes and cache strategy matter. |
| Batch processing | Eligible asynchronous work may be cheaper through batch pricing. |
| Thinking and effort | More thinking can improve hard answers but can also increase spend or latency. |
| Tokenizer behavior | Opus 4.7 may count the same fixed text differently from older models or Sonnet paths. |
| Human review time | A more expensive model can still be cheaper if it prevents repeated manual repair. |
The practical budget question is not "Which model is cheaper per token?" It is "Which model gives the lowest accepted-output cost for this workload?"
Test Both on the Same Workflow Before Changing Defaults
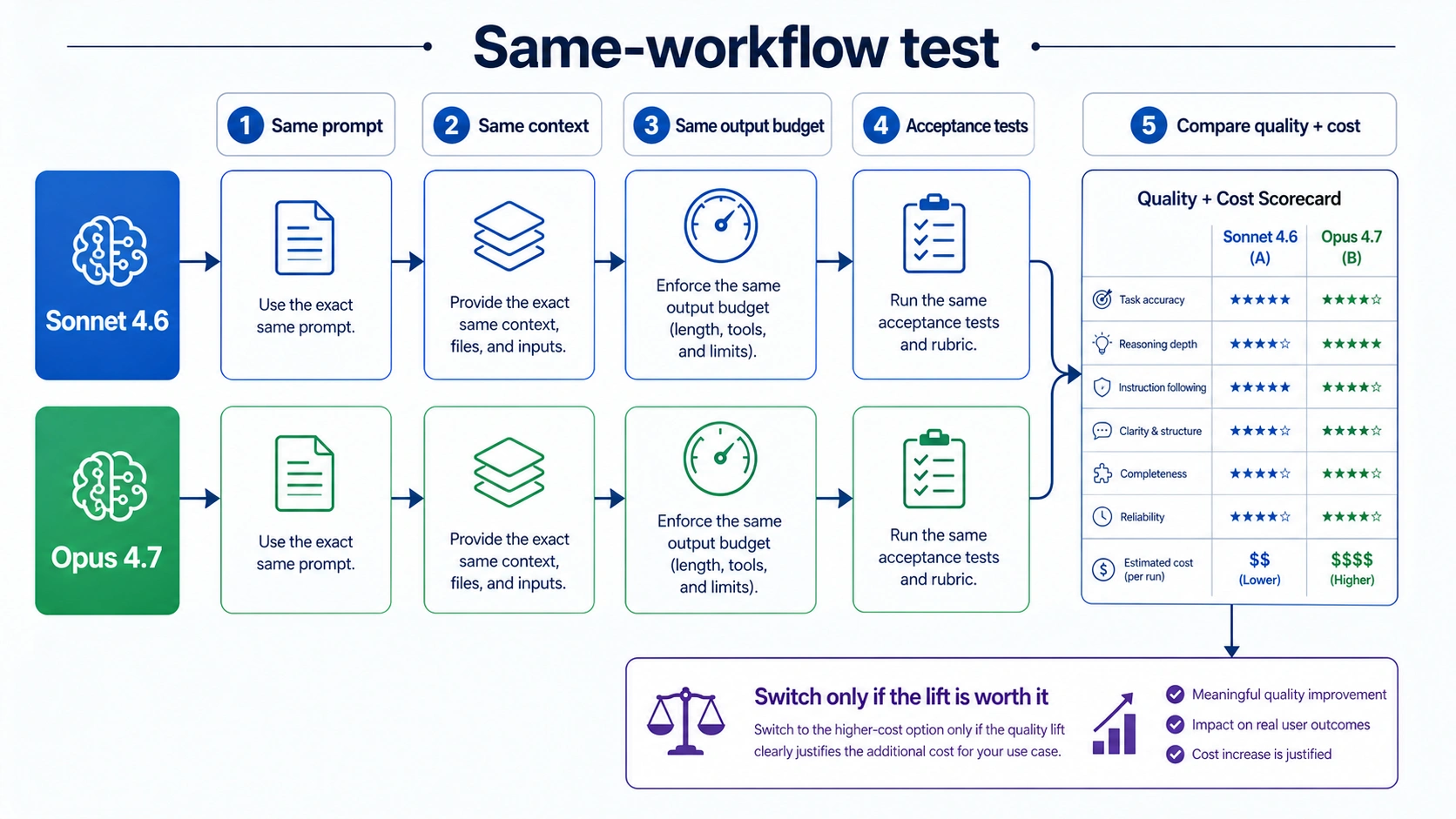
Do not switch a production default because a model label sounds stronger. Switch only when the same task performs better enough to pay for. A fair test keeps the prompt, context, output budget, tools, and acceptance criteria as equal as possible.
Use a small test plan:
- Pick three to five real tasks from the workflow.
- Remove sensitive data or run only in the approved environment.
- Run each task on Sonnet 4.6 with the current prompt and output budget.
- Run the same task on Opus 4.7 with the same prompt, context, and budget.
- Score both outputs against the same acceptance tests.
- Record token cost, latency, retries, manual review time, and final accepted result.
- Promote only the task slices where Opus improves accepted-output cost or failure severity.
This also prevents the opposite mistake: staying on Sonnet because it is cheaper while paying more in retries, review time, or failed outcomes. A team can keep Sonnet for normal traffic and route only hard slices to Opus. That mixed strategy is usually better than a universal default switch.
Claude App, API, and Claude Code Are Different Surfaces
Claude app access and API model choice are related but not identical. A Claude app user choosing models in the product may care about plan access and message limits. A developer using Claude Platform cares about model IDs, token prices, rate limits, caching, batch processing, and integration behavior. A Claude Code user may care about the model selected for coding sessions, but billing and availability can depend on subscription login, API keys, and local configuration.
Keep the boundaries tight:
- If the question is "Do I need Pro, Max, or API billing?", use a billing-specific resource such as the Claude API pricing versus subscription page.
- If the question is "Can I use Claude Code for free or through Pro?", use a Claude Code access page.
- If the question is "Which model should this task run on?", stay here and choose Sonnet, Opus, Haiku, or a test lane by workload.
This separation matters because buying access does not answer the model-routing question. A Pro user may still prefer Sonnet for most tasks. A developer with Opus API access may still route only hard failures to Opus. A team with Claude Code may still need to check whether its specific session is using a subscription route or API key route before making cost assumptions.
FAQ
Is Opus better than Sonnet?
Opus 4.7 is the stronger escalation model for the hardest tasks, but that does not make it the better default for every workload. Sonnet 4.6 is usually the better starting point when speed, cost, and scale matter. Opus is worth testing when task difficulty or failure cost justifies the premium.
Which should I use first, Opus or Sonnet?
Use Sonnet 4.6 first for most work. Move to Opus 4.7 when the task is high-stakes, ambiguous, long-running, architecture-heavy, document-heavy, or repeatedly failing on Sonnet after prompt cleanup.
How much more expensive is Opus than Sonnet?
As of May 7, 2026, Anthropic's official rows list Sonnet 4.6 at $3 input and $15 output per million tokens, and Opus 4.7 at $5 input and $25 output per million tokens. Real workload cost can differ because output length, caching, batch processing, thinking, retries, and Opus 4.7 tokenizer behavior can change the bill.
Is Sonnet enough for coding?
Sonnet 4.6 is enough for many coding loops, PR reviews, refactors, tests, and agent workflows. Use Opus when the coding task becomes architectural, spans many interacting constraints, needs deeper root-cause analysis, or repeatedly fails the same acceptance tests.
Does Claude Code use Opus or Sonnet?
Claude Code model behavior can depend on the current product, plan, settings, and route. Treat Claude Code as a workload surface rather than a separate answer to Opus versus Sonnet. For ordinary coding loops, Sonnet is often the default test. For difficult architecture or debugging tasks, compare Opus on the same repo task before changing your default behavior.
Where does Haiku fit?
Haiku 4.5 is the speed and cost off-ramp for mechanical tasks. Use it for simple extraction, routing, formatting, or low-risk batch work when it meets the output contract. Promote to Sonnet before jumping to Opus.
What should I do with old Opus 4.5 or Sonnet 4.5 advice?
Treat old version advice as historical orientation. For current model choice, use Opus 4.7 and Sonnet 4.6 facts checked against Anthropic's current model and pricing pages.
When should a team use both models?
Use both when the workload has a cheap normal path and a hard exception path. Sonnet can handle default traffic, while Opus handles tasks that fail Sonnet tests, need deeper reasoning, or have high review cost.