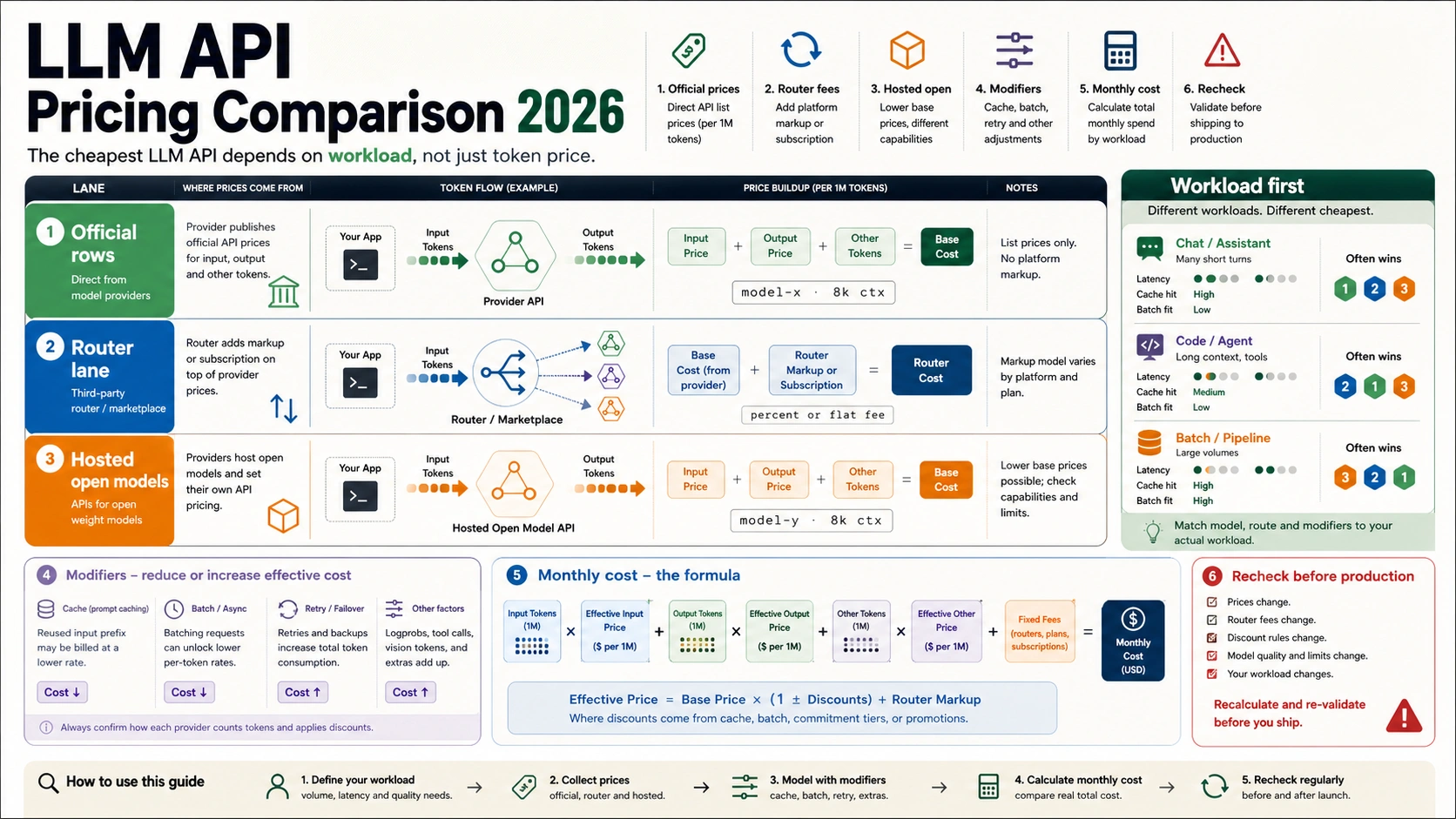
As of July 2, 2026, the cheapest LLM API is the route that completes your workload at the lowest accepted-output cost, not the model with the lowest input-token price. Keep official direct API rows separate from hosted open-model rows and router economics, then calculate monthly cost from input tokens, cached input, output tokens, route fees, and retry overhead.
| Price lane | Use it for | Representative current evidence |
|---|---|---|
| Official direct API | Provider-owned support, billing, data route, and model terms | OpenAI, Anthropic, Google Gemini, DeepSeek, Mistral, and xAI rows belong here only when quoted from their own pricing docs. |
| Hosted open-model API | Cheap serving of open-weight models without self-hosting | Groq-hosted GPT OSS, Llama, and Qwen rows are Groq route prices, not the model authors' official list prices. |
| Router or marketplace | One account for model switching, fallback, or comparison | OpenRouter-style rows are route-owned economics; platform fees, request limits, and fallback behavior matter beside token price. |
Start with this formula before choosing a winner:
monthly API cost = uncached input + cached input + output + route/tool/search/request fees + retry overhead - batch/cache savings
A bulk extraction job can favor a different model than a coding agent, support chatbot, long-context analysis job, or regulated workflow. Recheck model availability, preview labels, cache and batch discounts, free-tier rules, data-residency uplifts, and router fees before you move production traffic.
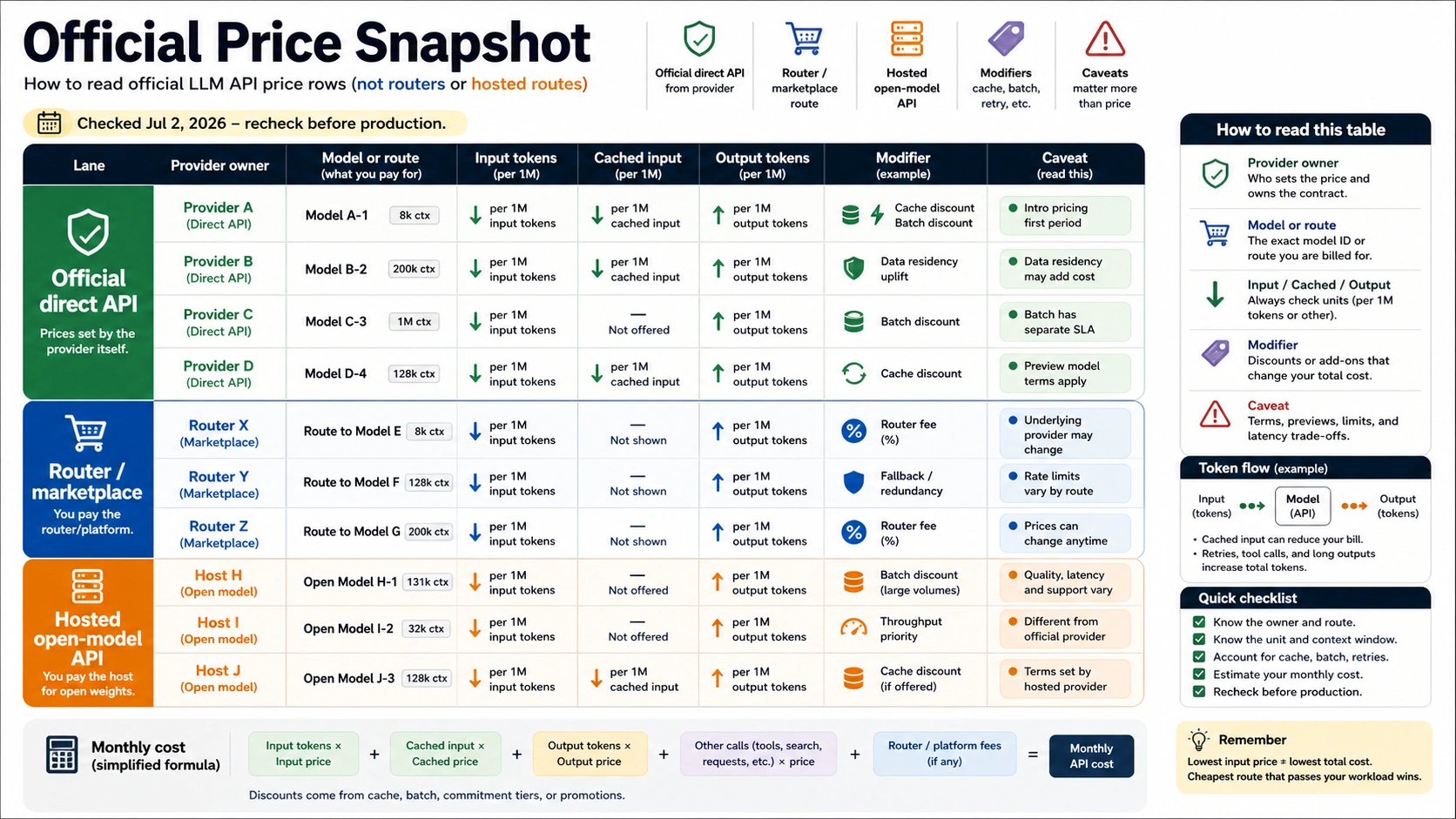
Official Direct API Price Snapshot
Use this table as a dated owner-labeled starting point, not as a permanent leaderboard. Prices are per 1M tokens in USD unless the row says otherwise. Input, cached input, and output are listed separately because output-heavy apps can invert a cheap-looking input price.
| Owner and route | Representative row checked July 2, 2026 | Input | Cached input | Output | Caveat to keep beside the row |
|---|---|---|---|---|---|
| OpenAI direct API, Standard | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Standard, Batch, Flex, and Priority are different economics. Data residency endpoints can add an uplift for eligible newer models. |
| OpenAI direct API, Standard | gpt-5.4-mini | $0.75 | $0.075 | $4.50 | Good comparison row for capable lower-cost OpenAI workloads, not a universal best model. |
| OpenAI direct API, Standard | gpt-5.5 | $5.00 | $0.50 | $30.00 | Use when model quality justifies the jump; output cost dominates. |
| Anthropic direct API | Claude Sonnet 5 intro row | $2.00 | route-specific | $10.00 | Intro pricing is stated through 2026-08-31; later pricing is $3.00 input and $15.00 output. |
| Anthropic direct API | Claude Haiku 4.5 | $1.00 | route-specific | $5.00 | Cache writes, cache hits, Batch, Fast mode, and data residency change the bill. |
| Google Gemini Developer API | gemini-3.1-flash-lite, Paid Tier Standard | $0.25 text/image/video, $0.50 audio | $0.025 text/image/video, $0.05 audio | $1.50 | Free Tier rows exist, but production should treat the paid project and data terms as a separate contract. |
| Google Gemini Developer API | gemini-3.5-flash, Paid Tier Standard | $1.50 | $0.15 | $9.00 | Grounding with Google Search and Maps can add query fees after the included monthly allowance. |
| Google Gemini Developer API | gemini-3.1-pro-preview, Paid Tier Standard | $2.00 <= 200k prompt tokens, $4.00 > 200k | $0.20 <= 200k, $0.40 > 200k | $12.00 <= 200k, $18.00 > 200k | Prompt length changes the price tier; preview status should be rechecked. |
| DeepSeek direct API | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | deepseek-chat and deepseek-reasoner map to V4 Flash modes and are scheduled for deprecation on 2026-07-24. |
| DeepSeek direct API | deepseek-v4-pro | $0.435 cache miss | $0.003625 cache hit | $0.87 | The official page also lists a 1M context and max output details; test latency and quality before assuming production fit. |
| Mistral official pricing | Mistral Large example | $2.00 | not listed in public pricing FAQ | $6.00 | Mistral states API pricing counts both input and output tokens and Batch gets a 50% discount. |
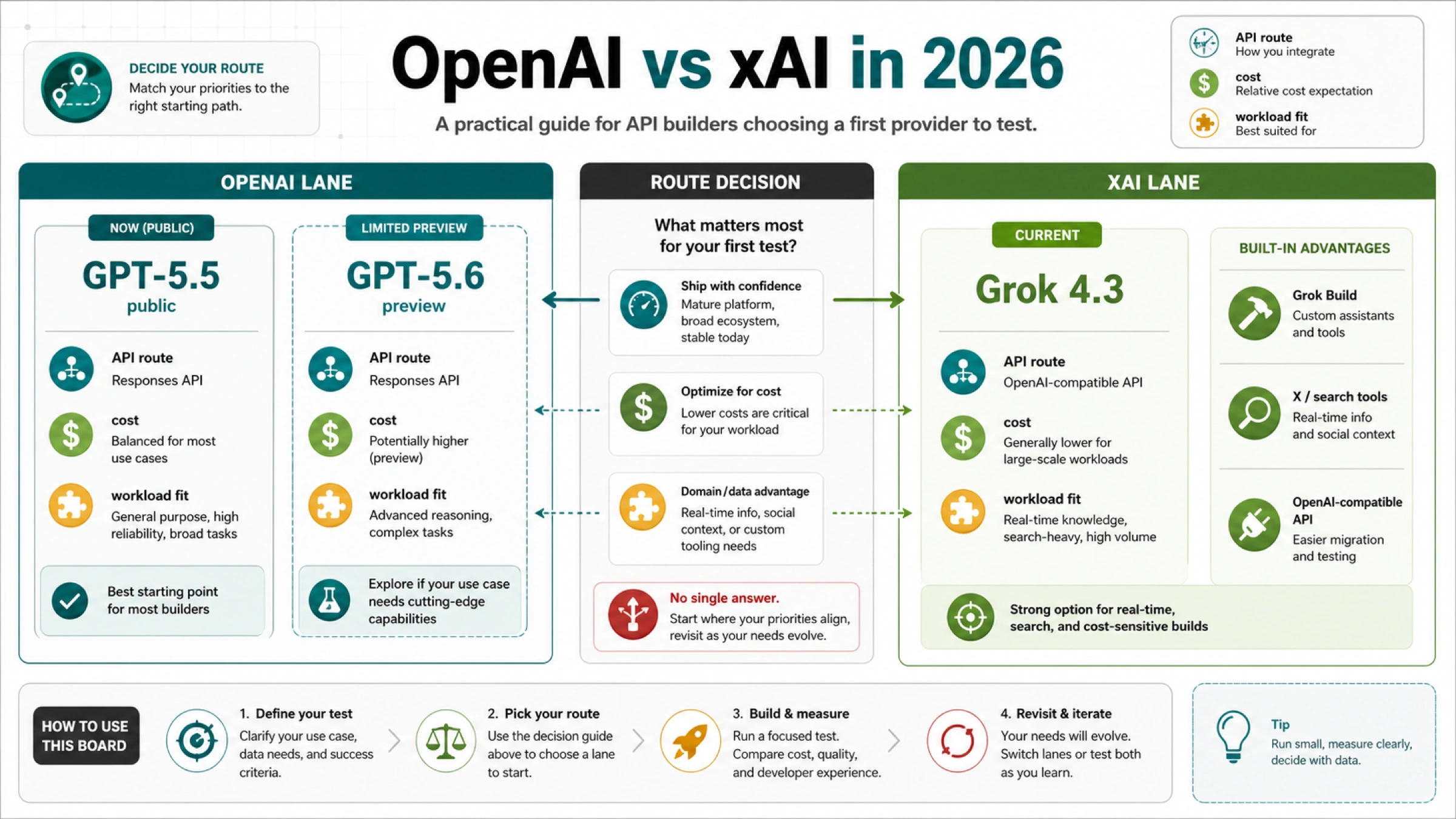
| xAI model docs | Grok 4.3 | $1.25 | not listed | $2.50 | xAI also points coding workloads to Grok Build 0.1; voice, image, and video use different units. |
Hosted open-model APIs and routers can be cheaper, but they are different contracts:
| Route owner | Row or contract | Pricing signal | How to use it |
|---|---|---|---|
| Groq pricing | openai/gpt-oss-20b hosted by Groq | $0.075 uncached input, $0.0375 cached input, $0.30 output | Treat as Groq's hosted serving price for this model route. |
| Groq pricing | openai/gpt-oss-120b hosted by Groq | $0.15 uncached input, $0.075 cached input, $0.60 output | Cheap first test for high-volume open-model workloads, after quality and latency checks. |
| OpenRouter pricing | Pay-as-you-go plan | 5.5% platform fee, 400+ models, 70+ providers | Useful router contract, not an official price owner for the underlying providers. |
| OpenRouter pricing | Free plan | 50 requests/day, free-model access | Fine for exploration, not a production entitlement. |
The snapshot is deliberately representative. If your shortlist depends on a model not shown here, go to the owner page and add it to the same owner, route, unit, date, caveat format before estimating spend.
Cheapest by Workload
A cheaper model wins only if it completes the same job with acceptable output and retry rate. That means the first shortlist should be workload-based, not provider-based.
| Workload | Start the test with | Why it can be cheap | Stop rule |
|---|---|---|---|
| Bulk extraction, classification, normalization | DeepSeek V4 Flash, Gemini 3.1 Flash-Lite, Groq GPT OSS 20B, OpenAI GPT-5.4-nano | Low input and output rows matter because quality threshold is usually measurable with labels or validators. | Do not ship until false positives, retries, and human-review rate are counted. |
| Support chatbot and FAQ answers | Gemini 3.1 Flash-Lite, OpenAI GPT-5.4-mini or nano, Claude Haiku 4.5, DeepSeek V4 Pro | The output ratio is moderate, and cached system or policy context can help. | If escalation quality drops, the lowest token price is not the lowest cost. |
| Coding assistant or agentic tool use | Claude Sonnet 5, OpenAI GPT-5.4 or GPT-5.5, xAI Grok Build, Gemini 3.5 Flash | Failures can create expensive retries and developer time; capable models may be cheaper per accepted patch. | Require same-repo evals, tool-call success rate, and rollback cost before switching. |
| Long-context analysis | Gemini Pro/Flash long-context rows, DeepSeek V4 1M context, Grok 4.3 where context fits | One larger call can be cheaper than chunking plus retrieval if quality holds. | Reprice when the prompt crosses a context-tier threshold or when cache storage is involved. |
| Regulated, sensitive, or enterprise workflows | Direct provider API or a contracted cloud route | Billing, data handling, account ownership, audit logs, and support may beat a cheaper router. | Do not choose a router only because the token row is lower. |
| Offline batch processing | OpenAI Batch, Google Batch, Mistral Batch, Groq Batch where supported | Many providers discount asynchronous workloads. | Batch is not a latency route; verify completion window, retry behavior, and output retrieval. |
The practical rule is: pick the cheapest model that passes the task, then test the next-cheaper route against the same samples. If the cheaper route increases retry rate, fallback rate, tool errors, moderation misses, or manual review, its real cost goes up.

Monthly Cost Worksheet
The real bill starts with your token mix, not a single published token row. Estimate each candidate with the same workload shape:
- Monthly uncached input tokens.
- Monthly cached input tokens or cache-hit rate.
- Monthly output tokens, including reasoning or thinking tokens when the provider bills them as output.
- Tool, search, request, route, or platform fees.
- Retry and fallback overhead.
- Batch or cache savings.
- Human-review or failure cost if the output does not pass.
Here are two simplified examples using only token rows and no tool/search/router fees. They are not recommendations; they show why a workload-specific worksheet beats a static leaderboard.
| Scenario | Candidate route | Token mix | Simple monthly token cost | Interpretation |
|---|---|---|---|---|
| Bulk data cleanup | Groq GPT OSS 20B | 100M input, 10M output | $10.50 | Very cheap if the hosted open model passes validation. |
| Bulk data cleanup | DeepSeek V4 Flash | 100M cache-miss input, 10M output | $16.80 | Still low, with a direct DeepSeek owner row and a 1M context signal. |
| Bulk data cleanup | OpenAI GPT-5.4-nano | 100M input, 10M output | $32.50 | May be worth testing when OpenAI compatibility or output quality matters. |
| Bulk data cleanup | Gemini 3.1 Flash-Lite | 100M text input, 10M output | $40.00 | Can improve if cache or Batch applies, but do not mix Free Tier with production assumptions. |
| Output-heavy chatbot | Groq GPT OSS 20B | 20M input, 20M output | $7.50 | Output is still cheap, but open-model quality must be proven. |
| Output-heavy chatbot | DeepSeek V4 Flash | 20M cache-miss input, 20M output | $8.40 | Output price is low; measure hallucination and escalation cost. |
| Output-heavy chatbot | OpenAI GPT-5.4-nano | 20M input, 20M output | $29.00 | Output cost dominates; use if task quality beats cheaper routes. |
| Output-heavy chatbot | Gemini 3.1 Flash-Lite | 20M text input, 20M output | $35.00 | Good if Gemini quality and ecosystem fit reduce retries. |
Now add the real modifiers. If 40% of a repeated system prompt becomes cached on OpenAI GPT-5.4-nano, those cached input tokens fall from $0.20/M to $0.02/M. If a Gemini 3.1 Flash-Lite workload can run through Batch, the paid input row drops from $0.25/M to $0.125/M and output from $1.50/M to $0.75/M. If an OpenRouter route adds a 5.5% platform fee, multiply the routed model spend by 1.055 before comparing it with direct provider billing.
The calculation should end with price per completed task:
price per completed task = total monthly route cost / accepted task count
If a cheap route completes 94% of tasks and a more expensive route completes 99.5%, the cheap route is not automatically cheaper. The missing 5.5% can become retries, fallbacks, manual review, support tickets, or lost output.

Direct API, Router, Hosted Open Model, or Self-Host?
A direct API and a router solve different ownership problems. Direct provider APIs are usually cleaner when you need official support, billing clarity, model-owner documentation, data-processing terms, or enterprise controls. They also make incident diagnosis simpler because the account, project, model, and status page point to one owner.
Routers are useful when the problem is model switching, fallback, traffic comparison, or a single integration across many providers. OpenRouter's pricing page makes that contract visible: Pay-as-you-go has a 5.5% platform fee, free users have request limits, and pricing changes or model deprecations still affect the routed workload. That can be worth it when the routing feature saves engineering time, but it is not the same as quoting OpenAI, Anthropic, or Google list prices.
Hosted open-model APIs sit between those worlds. Groq owns the serving price, rate limits, latency profile, and available roster for its hosted models. A Groq GPT OSS price row can be an excellent cost test, but it does not become OpenAI's API price just because the model label includes openai/gpt-oss.
Self-hosting belongs in the comparison only when volume, data locality, hardware access, and operations capacity justify it. Otherwise, the visible "free weights" price hides GPU utilization, serving engineering, monitoring, retries, scaling, security patching, and on-call cost.
Price Modifiers That Break Simple Tables
Output ratio is the first trap. A summarization or chatbot product can spend more on output than input. Choosing by input price alone can make the expensive row look cheap or the cheap row look safer than it is.
Caching is the second. OpenAI, Google, Anthropic, DeepSeek, and Groq expose different cache semantics or cache rows. Some rows distinguish cache hit from cache miss. Some add storage price. Some discounts depend on prompt structure or repeated prefixes. A cached policy-heavy support agent can price differently from a one-off question-answer workload.
Batch is the third. OpenAI, Google, Mistral, and Groq all expose batch-style economics in some form, but Batch is not a latency route. It belongs to offline extraction, eval generation, enrichment, and other asynchronous jobs. Do not compare a 24-hour batch window with a realtime chat endpoint as if they were the same product.
Tool and search fees are the fourth. OpenAI web search, Google Grounding with Search or Maps, Groq compound tools, and router-side features may add request or content charges. If your agent performs search on every turn, the model token row can be a minority of the bill.
Preview, introductory, and tier thresholds are the fifth. Anthropic's Sonnet 5 intro row has an end date. Google Gemini Pro Preview changes price by prompt length. Free tiers can be useful for testing while still being the wrong production contract. A table that omits these caveats is not a cost plan.
Finally, retry overhead is not optional. A cheaper model that needs 1.3 attempts per accepted answer should be priced as 1.3 attempts. A fallback route that pays only the successful model run still has latency and observability cost. A failed generated answer can cost more than its tokens if it reaches a customer.
Provider Notes
OpenAI's official pricing page is the owner for OpenAI direct API token rows. It lists Standard, Batch, Flex, and Priority separately, with input, cached input, and output columns. It also warns that direct OpenAI pricing can differ from AWS Bedrock billing and that eligible regional processing endpoints can carry a data-residency uplift.
Anthropic's pricing page is the owner for Claude direct API rows. It is also where cache writes, cache hits, Batch, Fast mode, and data-residency modifiers belong. If you are comparing Claude API billing with a subscription workflow, use a narrower branch such as Claude API pricing versus subscription; do not mix subscription seats into API token math.
Google Gemini's pricing page is the owner for Gemini Developer API rows. It currently separates Gemini 3.5 Flash, Gemini 3.1 Flash-Lite, Gemini 3.1 Pro Preview, image models, search grounding, Batch, and Free Tier terms. If the question is specifically free quota or live project limits, use a narrower guide such as Gemini API free tier rather than treating free status as production spend.
DeepSeek's official pricing page now presents deepseek-v4-flash and deepseek-v4-pro, with cache-hit, cache-miss, and output prices. It also says legacy deepseek-chat and deepseek-reasoner names map to V4 Flash modes and are scheduled for deprecation on July 24, 2026. That is why older comparator rows should be rechecked before publication.
Mistral's pricing page is enough to cite the pricing method and the Mistral Large example row, plus the 50% Batch discount. If your comparison depends on exact Mistral Small or Medium pricing, fetch the relevant model documentation before quoting a row.
xAI's model docs point general chat work to Grok 4.3, currently shown at $1.25 input and $2.50 output per 1M tokens, and coding work to Grok Build 0.1, currently shown at $1.00 input and $2.00 output per 1M tokens. Keep voice, image, and video units out of a text-token LLM table.
Groq is best treated as a hosted open-model serving lane. Its prices are official for GroqCloud serving, not for the underlying model authors. It is a strong candidate for high-volume evaluation when open-model quality is acceptable.
OpenRouter is a router and marketplace lane. Use it when routing, fallback, provider choice, activity logs, or one integration key matters. Do not quote an OpenRouter row as the official OpenAI, Anthropic, Google, DeepSeek, or xAI price.
Production Recheck Checklist
Before production traffic moves to the cheapest-looking route, run the same-task test:
| Check | What to record |
|---|---|
| Price owner | Official provider, hosted provider, router, cloud marketplace, or self-hosted route. |
| Model ID | Exact model string and whether it is an alias, preview, dated version, or deprecation path. |
| Token mix | Input, cached input, output, reasoning/thinking tokens, and average output ratio. |
| Route fees | Platform fee, request fee, search/tool fee, cache storage, data residency, and cloud marketplace uplift. |
| Quality threshold | Pass rate, retry rate, fallback rate, human-review rate, and failed-output cost. |
| Latency and limits | RPM, TPM, context limit, batch window, timeout, and provider status behavior. |
| Data route | Retention, training use, region, enterprise terms, and audit needs. |
| Spend controls | Hard caps, alerts, per-project budgets, tenant-level attribution, and rollback route. |
If the route still wins after that worksheet, it is a real low-cost candidate. If it wins only in a per-token table, keep it in evaluation.
FAQ
What is the cheapest LLM API right now?
For simple high-volume text tasks, hosted open-model routes such as Groq GPT OSS 20B or direct low-cost rows such as DeepSeek V4 Flash can look cheapest on token price. The real cheapest route is the one that passes your workload after output ratio, cache, batch, retries, route fees, and quality threshold are counted.
Is OpenAI cheaper than Claude or Gemini?
It depends on the model and workload. OpenAI GPT-5.4-nano and GPT-5.4-mini can be cost-effective rows for many OpenAI-compatible tasks, while Claude Sonnet 5 may be worth more for coding or agentic quality, and Gemini 3.1 Flash-Lite can be strong for high-volume Google ecosystem work. Compare the same token mix and success criteria.
Should I use a router like OpenRouter?
Use a router when model switching, fallback, one account, or provider comparison saves meaningful engineering time. Keep its platform fee, free-plan request limits, and routing behavior in the cost model. Use direct provider APIs when official support, data route, billing clarity, and incident ownership matter more.
Are free tiers useful for production?
Usually no. Free tiers are useful for exploration, evaluation, or low-risk prototypes. Production traffic needs predictable quota, billing owner, data terms, support path, and spend controls. A free row should not be treated as a permanent production entitlement.
Why does output price matter so much?
Many providers charge output tokens several times more than input tokens. A chatbot, agent, or report generator can spend more on generated output than prompt input. Always compare output-heavy and input-heavy workloads separately.
How do cache and batch discounts change the winner?
Cache discounts help repeated prompts, shared policy context, long reference documents, and multi-turn workflows with stable prefixes. Batch discounts help offline workloads that can wait. Both can flip the ranking, but only when the workload actually matches the discount conditions.
Can I trust third-party LLM price comparison tables?
Use them for discovery, not final pricing. They can reveal model breadth, UX expectations, and missing rows, but official direct provider pages own direct provider prices. Router and hosted-provider pages own their own route economics.
How often should I update an LLM API pricing comparison?
Recheck it before any production decision and before each published refresh. Model names, preview status, deprecations, free tiers, cache rules, batch discounts, and router fees can change quickly. For a static article, exact price rows should carry a checked date and owner label.