As of July 2, 2026, OpenAI direct Standard pricing for o4-mini is $1.10 per 1M input tokens, $0.275 per 1M cached input tokens, and $4.40 per 1M output tokens. That row is only the starting point: hidden reasoning tokens are billed as output, Batch and Flex can change the route price, and current OpenAI docs point many new reasoning workloads toward newer GPT-5.x models.
| If you need to know... | Read this row first | Practical meaning |
|---|---|---|
| Default API cost | Standard: $1.10 input, $0.275 cached input, $4.40 output per 1M tokens | Use this for normal OpenAI direct o4-mini inference estimates. |
| Async lower-cost work | Batch: $0.55 input and $2.20 output per 1M tokens | Use only when a 24-hour async route fits the workload. |
| Lower-priority live work | Flex: $0.55 input, $0.138 cached input, $2.20 output per 1M tokens | Treat it as a service-tier choice, not a guaranteed default for every account. |
| Premium processing | Priority: $2.00 input, $0.50 cached input, $8.00 output per 1M tokens | Do not use this as the normal cost estimate. |
| Strange higher rows | Deep Research, fine-tuning/RFT, Azure, or provider pages | These are separate contracts, not the base OpenAI direct price. |
The stop rule: estimate o4-mini with fresh input, cached input, visible output, and hidden reasoning tokens before calling it cheap. Keep it where your evals already prove quality at acceptable cost; test GPT-5.4 mini or GPT-5.5 for new reasoning workloads; use a cheaper non-reasoning model for extraction, classification, formatting, and routing.
What o4-mini is now
OpenAI's o4-mini model page still lists o4-mini as a reasoning model with the current snapshot o4-mini-2025-04-16, and it describes the model as a fast, cost-efficient reasoning option optimized for coding and visual tasks. The same model page also says it was succeeded by GPT-5 mini, so the right wording is "still listed and usable where it fits," not "new default" and not "deprecated."
That distinction matters for cost planning. A legacy router may already have evals showing that o4-mini gives acceptable answers at a lower bill than a larger reasoning model. A new application should not assume the same result. OpenAI's current reasoning guidance points most fresh reasoning work toward newer GPT-5.x models first, then toward lower-cost GPT-5.4 or GPT-5.4 mini when cost is the deciding pressure.
The model identity is also easy to confuse. o4-mini is not GPT-4o mini. It is not GPT-5 mini. It is not GPT-5.4 mini. It is also not the specialized o4-mini-deep-research row on the pricing page. Use the exact model ID in code, logs, dashboards, and cost spreadsheets so support, usage, and billing evidence all point at the same row.
Official o4-mini price rows

OpenAI's API pricing page is the source of truth for the numbers below. The safest way to read it is to separate the base model row from service tiers and specialized rows before doing any math.
| Route | Input per 1M tokens | Cached input per 1M tokens | Output per 1M tokens | Use it when |
|---|---|---|---|---|
Standard o4-mini | $1.10 | $0.275 | $4.40 | You need the normal OpenAI direct API price for synchronous inference. |
Batch o4-mini | $0.55 | Not separately listed | $2.20 | The job can run asynchronously with the Batch API's 24-hour completion window. |
Flex o4-mini | $0.55 | $0.138 | $2.20 | The workload can tolerate lower-priority processing and the route is available for your use case. |
Priority o4-mini | $2.00 | $0.50 | $8.00 | You are intentionally paying more for premium processing. |
o4-mini-deep-research | $2.00 | $0.50 | $8.00 | You are using the separate specialized Deep Research model row. |
The fine-tuning and reinforcement fine-tuning areas of the pricing page can expose different o4-mini-2025-04-16 numbers, including training-hour and higher inference rows. Those are not the base Standard inference price. Azure OpenAI and third-party providers are also separate billing surfaces. They can be relevant for procurement, but they should not be pasted into an OpenAI direct cost estimate.
The cached input price deserves special attention. Cached tokens are not a second request. They are part of the current input that match a reusable prefix and qualify for the cached rate. If an 80K-token prompt has 60K cached tokens, the fresh input portion is 20K, not 80K plus 60K.
How to estimate a real o4-mini request

For Standard pricing, the working formula is:
hljs textcost = fresh_input_tokens / 1,000,000 * 1.10 + cached_input_tokens / 1,000,000 * 0.275 + (visible_output_tokens + reasoning_tokens) / 1,000,000 * 4.40
Reasoning tokens are the part most spreadsheets miss. OpenAI's reasoning docs explain that reasoning tokens are not visible in the final answer, but they are billed as output tokens and occupy context. That means a short visible answer can still be expensive if the model spends many tokens reasoning before it answers.
Example A: an interactive request has 10,000 fresh input tokens, no cached input, 2,000 visible output tokens, and 3,000 reasoning tokens. The input portion is 10,000 / 1,000,000 * $1.10 = $0.011. The output-billed portion is (2,000 + 3,000) / 1,000,000 * $4.40 = $0.022. The estimated Standard API cost is about $0.033 before any other platform-level considerations.
Example B: a longer workflow has an 80,000-token prompt where 60,000 tokens are cached, so only 20,000 tokens are fresh input. It returns 5,000 visible output tokens and uses 10,000 reasoning tokens. The fresh input portion is 20,000 / 1,000,000 * $1.10 = $0.022. The cached portion is 60,000 / 1,000,000 * $0.275 = $0.0165. The output-billed portion is (5,000 + 10,000) / 1,000,000 * $4.40 = $0.066. The estimate is about $0.1045.
Those examples are deliberately small. Monthly cost usually comes from volume, retries, long context, and repeated reasoning. If 100,000 requests look cheap one at a time, a few extra thousand reasoning tokens per request can still move the monthly bill by a meaningful amount.
When o4-mini still makes sense
o4-mini is most defensible when it already has a measured job in your system. Good candidates include coding assistance with bounded outputs, math or logic checks where you can evaluate correctness, visual reasoning tasks that do not need the newest model, and routing steps where a larger model is wasteful. The point is not that o4-mini is universally cheap. The point is that it can be cheap enough when reasoning depth and output length stay under control.
Use an eval set before moving traffic. Compare answer quality, latency, visible output length, reasoning-token usage, retry rate, and downstream correction cost. A model that is cheaper per token can still cost more if it needs longer reasoning, more retries, or human repair. A model that costs more per token can still be cheaper in the full workflow if it resolves the task in one pass.
Legacy routers are another valid lane. If your production system already routes a specific class of requests to o4-mini, keep that lane while you test alternatives. Do not replace a working router just because a newer model exists. Replace it when newer models win on your own quality, cost, and failure-rate metrics.
When to switch models
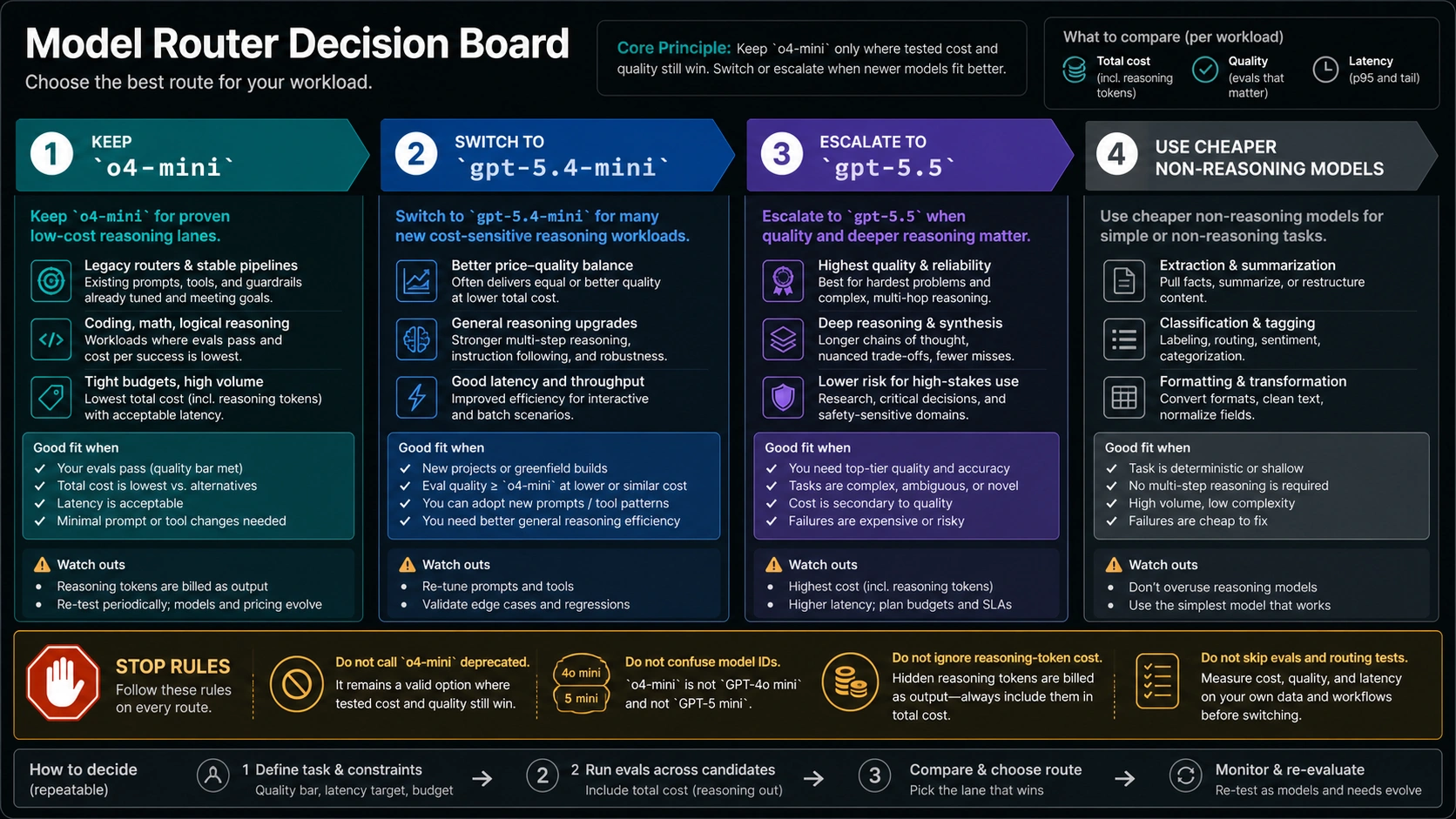
For new reasoning work, start by testing the current GPT-5.x recommendations rather than assuming o4-mini should be the default. GPT-5.4 mini is the natural comparison when the job is cost-sensitive and still needs reasoning. GPT-5.5 is the escalation lane when deep reasoning, reliability, or hard problem-solving matters more than the smaller model's token price.
For simple extraction, classification, formatting, metadata normalization, routing, or small deterministic transformations, do not force a reasoning model into the path. A cheaper non-reasoning model can be the right first move if you can validate the output shape. The cost savings come from using reasoning only where it changes the result.
Keep a decision table in your router:
| Workload | First model to test | Why |
|---|---|---|
Existing o4-mini lane with passing evals | Keep o4-mini while retesting alternatives | You already have a measured baseline. |
| New cost-sensitive reasoning | GPT-5.4 mini and o4-mini side by side | The newer mini reasoning model may win on quality per dollar. |
| Hard reasoning, coding repair, or complex planning | GPT-5.5 | Higher quality can reduce retries and human correction. |
| Extraction, classification, formatting, routing | Cheaper non-reasoning model | Reasoning tokens may not add value. |
| Long repeated prompts | Model with prompt caching discipline | Cached input and stable prefixes can matter more than the headline row. |
The best model choice is rarely a one-row price comparison. It is a measured route decision: quality, retries, output length, reasoning tokens, latency, and support burden all affect the bill.
Cost controls that actually matter
Prompt caching is the first lever to check when prompts share a long stable prefix. OpenAI's prompt caching docs describe automatic caching for prompts that meet the threshold, and the usage object can show cached token details. Put static instructions, schemas, long policies, and repeated reference blocks early and keep them stable. Move volatile per-request content later so the cacheable prefix stays intact.
max_output_tokens is a cost guardrail, but with reasoning models it covers more than visible text. The reasoning docs note that the output budget includes visible output and reasoning tokens. If the budget is too low, a response can stop before useful visible output appears. If it is too high, you may hide runaway reasoning cost. Track both visible output and reasoning token usage rather than tuning the cap blindly.
Batch is useful when the workload can wait. OpenAI's Batch API docs describe the route as lower cost, higher rate limits, and a 24-hour turnaround. It is a poor fit for interactive chat and user-facing workflows that expect immediate answers. It is a strong fit for backfills, offline evaluation, bulk classification, and nightly processing.
Flex is a service-tier lever, not a universal replacement for Standard. Treat it as an option for lower-priority work where the route is available and the operational behavior fits. Priority is the opposite: it can raise cost, so reserve it for cases where premium processing has a measurable business reason.
Finally, reduce work before optimizing the rate. OpenAI's cost optimization guidance puts model choice, fewer requests, and token reduction ahead of rate-card reading for a reason. Shorter inputs, narrower tool calls, fewer retries, smaller output formats, and better model routing can beat a nominally cheaper row. If the request is failing because of quota or rate limits rather than price, the adjacent OpenAI API rate limit guide is the better troubleshooting path. If the blocker is API-key setup or billing state, start with the OpenAI API key free trial guide.
Common mistakes to avoid
Do not read a fine-tuning row as the base inference row. Fine-tuning and reinforcement fine-tuning pricing can show different numbers because training, data-sharing settings, and tuned-model inference are separate from ordinary o4-mini Standard calls.
Do not read o4-mini-deep-research as plain o4-mini. The name is similar, but it is a specialized model row with a different job. If the model ID in your request is o4-mini, estimate from the o4-mini row. If the model ID is o4-mini-deep-research, estimate from that row.
Do not use Azure or provider prices as OpenAI direct prices. Azure may have regional, deployment, data-zone, or enterprise terms. Providers may bundle credits, rate limits, routing, logging, and support differently. Those can be valid routes, but they are not evidence for OpenAI's direct API price.
Do not assume cached input applies just because a prompt is long. Caching depends on reusable prefixes and the way requests are structured. If the repeated part changes position or content, the cache benefit can disappear.
Do not call o4-mini deprecated. Current OpenAI docs say it is succeeded by GPT-5 mini and current reasoning docs recommend newer GPT-5.x models for many workloads. That is enough to change the default starting point. It is not the same as an official deprecation notice.
Quick checklist before shipping
- Confirm the exact model ID in code and logs is
o4-mini. - Use the Standard row for normal OpenAI direct estimates.
- Separate fresh input from cached input.
- Add visible output and reasoning tokens together for output-billed cost.
- Test Batch only for async workloads.
- Test Flex only when lower-priority processing fits.
- Keep Priority out of normal estimates unless you intentionally need it.
- Compare GPT-5.4 mini and GPT-5.5 on your eval set before sending new reasoning traffic to
o4-mini. - Route simple extraction, classification, formatting, and routing to cheaper non-reasoning models when quality holds.
- Keep Azure, provider, Deep Research, and fine-tuning/RFT prices in separate spreadsheets.
FAQ
What is the current o4-mini API price?
As of July 2, 2026, OpenAI direct Standard pricing for o4-mini is $1.10 per 1M input tokens, $0.275 per 1M cached input tokens, and $4.40 per 1M output tokens. Batch, Flex, Priority, Deep Research, fine-tuning, Azure, and provider routes have separate rows or terms.
Are reasoning tokens billed for o4-mini?
Yes. For reasoning models, hidden reasoning tokens are billed as output tokens. Estimate cost with visible output plus reasoning tokens, not visible output alone.
Does cached input mean the prompt is counted twice?
No. Cached input is the portion of the current input that qualifies for the cached rate. If a prompt has 80K total input tokens and 60K cached tokens, the fresh input portion is 20K.
Is Batch cheaper for o4-mini?
The Batch row is lower than Standard for input and output, but it is an async route with a 24-hour completion window. Use it for offline jobs, backfills, and bulk processing, not interactive user flows.
Is Flex the same as Batch?
No. Flex is a lower-priority service tier for eligible workloads. Batch is an asynchronous batch-processing route. Both can reduce price, but they solve different operational problems.
Is o4-mini deprecated?
Current OpenAI docs list o4-mini and say it is succeeded by GPT-5 mini. That should push new work toward current GPT-5.x tests, but it is not the same as an official deprecation statement.
Should I use o4-mini or GPT-5.4 mini?
Test both if the workload needs low-cost reasoning. Keep o4-mini when your evals show it wins at acceptable quality and cost. Try GPT-5.4 mini first for many new cost-sensitive reasoning workloads because it is the current mini reasoning lane in OpenAI's newer model guidance.
Should I use o4-mini or GPT-5.5?
Use GPT-5.5 when hard reasoning, complex planning, coding repair, or lower failure rate matters more than the smaller model's token price. A higher per-token price can still be cheaper in practice if it avoids retries and manual correction.
Why do some pages show higher o4-mini numbers?
They may be showing Priority, Deep Research, fine-tuning/RFT, Azure, provider pricing, or tuned-model inference rather than the base OpenAI direct Standard row. Check the model ID, route, and billing surface before copying a number.
How do I estimate monthly o4-mini spend?
Estimate one request first: fresh input, cached input, visible output, and reasoning tokens. Multiply by expected volume, then add retry rate, failed requests that still consume tokens, Batch/Flex routing share, and any Priority or specialized routes. Reconcile the spreadsheet against real usage logs before committing a budget.